9 Word-level Quality Estimation for Machine Translation Post-editing
That’s just what translation is, I think. That’s all speaking is. Listening to the other and trying to see past your own biases to glimpse what they’re trying to say. Showing yourself to the world, and hoping someone else understands.
– Rebecca F. Kuang, Babel (2022)
9.1 Introduction
Recent years saw a steady increase in the quality of machine translation systems and their widespread adoption in professional translation workflows (Kocmi et al., 2024a). Still, human post-editing of MT outputs remains a fundamental step to ensure high-quality translations, particularly for challenging textual domains requiring native fluency and specialized terminology (Liu et al., 2024). Quality estimation (QE) techniques were introduced to reduce post-editing effort by automatically identifying problematic MT outputs without the need for human-written reference translations and were quickly integrated into industry platforms (Tamchyna, 2021).
Segment-level QE models correlate well with human perception of quality (Freitag et al., 2024) and exceed the performance of reference-based metrics in specific settings (Rei et al., 2021; Amrhein et al., 2022; Amrhein et al., 2023). On the other hand, word-level QE methods for identifying error spans requiring revision have received less attention in the past due to their modest agreement with human annotations, despite their promise for more granular and interpretable quality assessment in line with modern MT practices (Zerva et al., 2024). In particular, while the accuracy of these approaches is regularly assessed in evaluation campaigns, research has rarely focused on assessing the impact of such techniques in realistic post-editing workflows, with notable exceptions suggesting limited benefits (Shenoy et al., 2021; Eo et al., 2022). This hinders current QE evaluation practices: by foregoing experimental evaluation with human editors, it is implicitly assumed that word-level QE will become helpful once sufficient accuracy is achieved, without accounting for the additional challenges associated with successfully integrating these methods into post-editing workflows.
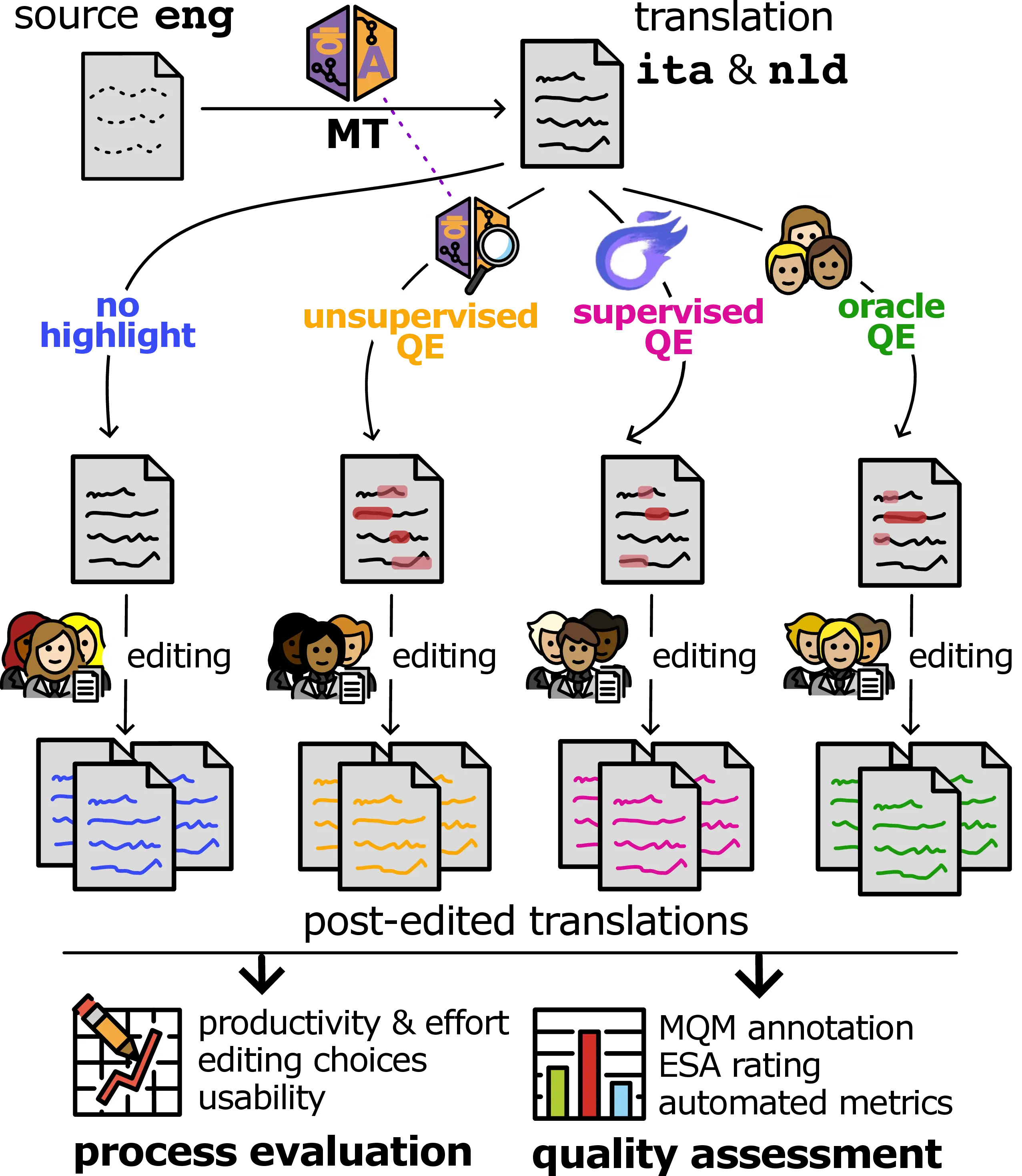
In this chapter, we present a study, which we dub QE4PE (Quality Estimation for Post Editing), addressing this gap through a large-scale study with 42 professional translators for the English\(\rightarrow\)Italian and English\(\rightarrow\)Dutch directions to measure the impact of word-level QE on editing quality, productivity and usability. We aim for a realistic and reproducible setup, employing the high-quality open-source NLLB 3.3B MT model (NLLB Team et al., 2024) to translate challenging documents from biomedical and social media domains. We then conduct a controlled evaluation of post-editing with error spans in four highlight modalities, i.e. using highlights derived from four word-level QE methods: a supervised state-of-the-art QE model trained on human error annotations (xcomet, Guerreiro et al., 2024), an unsupervised method leveraging the uncertainty of the MT model during generation, oracle error spans obtained from the consensus of previous human post-editors, and a no highlight baseline. The human post-editing is performed using GroTE, a simple online interface we built to support the real-time logging of granular editing data, enabling a quantitative assessment of editing effort and productivity across highlight modalities. We also survey professionals using an online questionnaire to collect qualitative feedback about the usability and quality of the MT model, as well as the interface and error span highlights. Finally, a subset of the original MT outputs and their post-edited variants is annotated following the MQM and ESA protocols (Lommel et al., 2013; Kocmi et al., 2024b) to verify quality improvements after post-editing. See Figure 9.1 for an overview of the study. Most similar to our study, Shenoy et al. (2021) investigated the effect of synthetic word-level QE highlights for English\(\rightarrow\)German post-editing on Wikipedia data, concluding that word-level QE accuracy was at the time still insufficient to produce tangible productivity benefits in human editing workflows. We expand the scope of such evaluation by including two translation directions, two challenging real-world text domains and state-of-the-art MT and QE systems and methods. In summary, our work represents a step towards evaluating translation technologies and methods that leverage model internals, centered on users’ experience (Guerberof-Arenas and Moorkens, 2023; Savoldi et al., 2025).
We release all data, code and the GroTE editing interface to foster future studies on the usability of error span highlighting techniques for other word-level QE methods and translation directions.1
9.2 Experimental Setup
9.2.1 Structure of the Study
Our study is organized in five stages:
1) Oracle Post-editing As a preliminary step, segments later used in the main assessment are post-edited by three professionals per direction using their preferred interface without logging. This allows us to obtain post-edits and produce oracle word-level spans based on the editing consensus of multiple human professionals. Translators involved in this stage are not involved further in the study.
2) Pretask (Pre) The pretask allows the core translators (12 per language direction, see Section 9.2.4) to familiarize themselves with the GroTE interface and text highlights. Before starting, all translators complete a questionnaire to provide demographic and professional information about their profile (Table 9.9). In the pretask, all translators work in an identical setup, post-editing a small set of documents similar to those of the main task with Oracle highlights. We assign core translators into three groups based on their speed, as determined by their editing logs (4 translators per group for faster, average and slower groups in each direction). Individuals from each group are then randomly assigned to each highlight modality to ensure an equal representation of editing speeds, resulting in 1 faster, 1 average, and 1 slower translator for each highlight modality. This procedure is repeated independently for both translation directions.
3) Main Task (Main) This task, conducted in the two weeks following the pretask, covers the majority of the collected data and is the main object of study for the analyses of Section 9.3. In the main task, 24 core translators work on the same texts using the GroTE interface, with three translators per modality in each translation direction, as shown in Figure 9.1. After the main task, translators complete a questionnaire on the quality and usability of the MT outputs, the interface and, where applicable, word highlights.2
4) Post-Task (Post) After Main, the 12 core translators per direction are asked to post-edit an additional small set of related documents with GroTE, but this time working all with the No Highlight modality. This step lets us obtain baseline editing patterns for each translator, allowing us to estimate individual speed and editing differences across highlight modalities without the confounding effect of interface proficiency accounted for in the Pre stage.
5) Quality Assessment (QA) Finally, a subset consisting of 148 main task segments is randomly selected for manual annotation by six new translators per direction (see Section 9.2.4). For each segment, the original MT output and all its post-edited versions are annotated with MQM error spans, including minor/major error severity and a subset of MQM error categories, including e.g., mistranslations, omissions, and stylistic errors (Lommel et al., 2013). Table 9.1 presents our annotation guidelines.3 Moreover, the annotator proposes corrections for each error span, ultimately providing a 0-100 quality score, which matches the common DA scoring adopted in multiple WMT campaigns. We adopt this scoring system, which closely adheres to the ESA evaluation protocol (Kocmi et al., 2024b), following recent results showing its effectiveness and efficiency for ranking MT systems.
In summary, for each translation direction, we collect three full sets of oracle post-edits, 12 full sets of edits with behavioral logs for pre, main and post task data, and 13 subsets of main task data (12 post-edits, plus the original MT output) annotated with MQM error spans, corrections and segment-level ESA ratings. Moreover, we also collect 12 pre- and post-task questionnaire responses from core set translators to obtain a qualitative view of the editing process.
| Error category | Subcategory | Description |
|---|---|---|
| Accuracy Incorrect meaning has been transferred to the source text. |
Addition | Translation includes the information that is not present in the source and it changes or distorts the original message. |
| Omission | Translation is missing the information that is present in the source, which is important to convey the message. | |
| Mistranslation | Translation does not accurately represent the source content meaning. | |
| Inconsistency | There are internal inconsistencies in the translation (for example, using different verb forms in the bullet list or in CTAs, calling the same UI element differently, terminology used inconsistently etc). | |
| Untranslated | Content that should have been translated has been left untranslated. | |
| Linguistic Official linguistic reference sources such as grammar books. |
Punctuation | Punctuation is used incorrectly (for the locale or style), including missing or extra white spaces and the incorrect use of space (non-breaking space). Violation of typographic conventions of the locale. |
| Spelling | Issues related to spelling of words, including typos, wrong word hyphenation, word breaks and capitalization. | |
| Grammar | Issues related to the grammar or syntax of the text, other than spelling. | |
| Style Not suitable/native; too literal or awkward. |
Inconsistent Style | Style is inconsistent within a text. |
| Readability | Translation does not read well (due to heavy sentence structure, frequent repetitions, unidiomatic). | |
| Wrong Register | Inappropriate style for the specific subject field, the level of formality, and the mode of discourse (e.g., written text versus transcribed speech). |
| Severity | Description |
|---|---|
| Major | The Severity Level of an error that seriously affects the understandability, reliability, or usability of the content for its intended purpose or hinders the proper use of the product or service due to a significant loss or change in meaning or because the error appears in a highly visible or important part of the content. |
| Minor | The Severity Level of an error that does not seriously impede the usability, understandability, or reliability of the content for its intended purpose, but has a limited impact on, for example, accuracy, stylistic quality, consistency, fluency, clarity, or general appeal of the content. |
| Neutral | The Severity Level of an error that differs from a quality evaluator's preferential translation or that is flagged for the translator's attention but is an acceptable translation. |
9.2.2 Highlight Modalities
We conduct our study on four highlight modalities across two severity levels (minor and major errors). Using multiple severity levels aligns with current MT evaluation practices (Freitag et al., 2021; Freitag et al., 2024), as well as previous results indicating that users tend to prefer more granular and informative word-level highlights (Shenoy et al., 2021; Vasconcelos et al., 2025). The highlight modalities we employ are:
No Highlight The text is presented as-is, without any highlighted spans. This setting serves as a baseline to estimate the default post-editing quality and productivity using our interface.
Oracle Following the Oracle Post-editing phase, we produce oracle error spans from the editing consensus of human post-editors. We label text spans that were edited by two of the three translators as minor, and those edited by all three translators as major, following the intuition that more critical errors are more likely to be identified by several annotators, while minor changes will show more variance across subjects. This modality serves as a best-case scenario, providing an upper bound for future improvements in word-level QE quality.
Supervised In this setting, word-level error spans are obtained using xcomet-xxl (Guerreiro et al., 2024), which is a multilingual transformer encoder (Goyal et al., 2021) further trained for joint word- and sentence-level QE prediction. We select xcomet-xxl in light of its broad adoption, open accessibility and state-of-the-art performance in QE across several translation directions (Zerva et al., 2024). For the severity levels, we use the labels predicted by the model, mapping critical labels to the major level.
Unsupervised In this modality, we exploit the access to the MT model producing the original translations to obtain uncertainty-based highlights. As a preliminary evaluation to select a capable unsupervised word-level QE method, we evaluate two unsupervised QE methods employing token log-probabilities assigned by MT model to predict human post-edits: raw negative log-probabilities (Logprobs), corresponding to the surprisal assigned by the MT model to every generated token, and their variance for 10 steps of Monte Carlo Dropout (Logprobs\(_\text{mcd var}\), Gal and Ghahramani, 2016). We employ surprisal-based metrics, following previous work that shows their effectiveness in predicting translation errors (Fomicheva and Specia, 2019) and human editing time (Lim et al., 2024). We collect scores for the English\(\rightarrow\)Italian and English\(\rightarrow\)Dutch directions of QE4PE Oracle post-edits and our DivEMT dataset (Sarti et al., 2022) to identify the best-performing method, using metric scores extracted from the original models used for translation to predict human post-edits. We use average precision (AP) as a threshold-agnostic performance metric for the tested continuous methods. Oracle highlights obtained from the consensus of three annotators in the first stage of the study are used as reference for QE4PE, while a single set of post-edits is available for DivEMT. The xcomet-xxl model used for Supervised highlights, and the average agreement of individual Oracle editors with the consensus label are also included for comparison.
| Method | DivEMT | QE4PE | ||||||
|---|---|---|---|---|---|---|---|---|
| en→it | en→nl | en→it | en→nl | |||||
| AP | AU | AP | AU | AP | AU | AP | AU | |
| Logprobs | 0.18 | 0.18 | 0.19 | 0.19 | 0.10 | 0.09 | 0.09 | 0.09 |
| Logprobs \(_\text{mcd var}\) (Unsup.) | 0.41 | 0.41 | 0.42 | 0.42 | 0.23 | 0.23 | 0.31 | 0.31 |
| xcomet-xxl (Sup.) | 0.16 | 0.23 | 0.19 | 0.28 | ||||
| Avg. Oracle single translator | - | - | - | - | 0.53 | 0.73 | 0.55 | 0.75 |
Results in Table 9.2 show a strong performance for the Logprobs\(_\text{mcd var}\) method, even surpassing the accuracy of the supervised xcomet model across both datasets.4 Hence, we select it for the Unsupervised highlight modality, setting value thresholds for minor/major errors to match the respective highlighted word proportions in the Supervised modality to ensure a fair comparison of their effectiveness in the post-editing task.
9.2.3 Data and MT model
MT Model On the one hand, the MT model must achieve high translation quality in the selected languages to ensure our experimental setup applies to state-of-the-art proprietary systems. Still, the MT model should be open-source and have a manageable size to ensure reproducible findings and enable the computation of uncertainty for the unsupervised setting. All considered, we use NLLB 3.3B (NLLB Team et al., 2024), a widely used MT model achieving industry-level performances across 200 languages (Moslem et al., 2023).
Data selection We begin by selecting two translation directions, English\(\rightarrow\)Italian and English\(\rightarrow\)Dutch, according to the availability of professional translators from our industrial partners. We intentionally focus on out-of-English translations as they are generally more challenging for modern MT models (Kocmi et al., 2023). We aim to identify documents that are manageable for professional translators without domain-specific expertise but still prove challenging for our MT model to ensure a sufficient amount of error spans across modalities. Since original references for our selected translation direction were not available, we do not have a direct mean to compare MT quality in the two languages. However, according to our human MQM assessment in Section 9.3.3 (Table 9.7), NLLB produces a comparable amount of errors across Dutch and Italian translations, suggesting similar quality.
| Task | Domain | # Docs | # Seg. | # Words |
|---|---|---|---|---|
| Pre | Social | 4 | 23 | 539 |
| Biomed. | 2 | 15 | 348 | |
| Main | Social | 30 | 160 | 3375 |
| Biomed. | 21 | 165 | 3384 | |
| Post | Social | 6 | 34 | 841 |
| Biomed. | 2 | 16 | 257 | |
| Total | 64 | 413 | 8744 | |
We begin by translating 3,672 multi-segment English documents from the WMT23 General and Biomedical MT shared tasks (Kocmi et al., 2023; Neves et al., 2023) and MT test suites to Dutch and Italian. Our choice for these specialized domains, as opposed to e.g. generic news articles, is driven by the real-world needs of the translation industry for domain-specific post-editing support (Eschbach-Dymanus et al., 2024; Li et al., 2025). Moreover, focusing on domains that are considerably more challenging for MT systems than news, as shown by recent WMT campaigns (Neves et al., 2024), ensures a sufficient amount of MT errors to support a sound comparison of word-level QE methods. Then, xcomet-xxl is used to produce a first set of segment-level QE scores and word-level error spans for all segments. To make the study tractable, we further narrow down the selection of documents according to several heuristics to ensure a realistic editing experience and a balanced occurrence of error spans (details in Section C.2.1). This procedure yields 351 documents, from which we manually select a subset of 64 documents (413 segments, 8,744 source words per post-editor) across two domains:
- Social media posts, including Mastodon posts from the WMT23 General Task (Kocmi et al., 2023) English\(\leftrightarrow\)German evaluation and Reddit comments from the Robustness Challenge Set for Machine Translation (RoCS-MT, Bawden and Sagot, 2023), displaying atypical language use, such as slang or acronymization.
- Biomedical abstracts extracted from PubMed from the WMT23 Biomedical Translation Task (Neves et al., 2023), including domain-specific terminology.
Table 9.3 present statistics for the Pre, Main and Post editing stages, and Table 9.4 shows an example of highlights and edits. While including multiple domains in the same task can render our post-editing setup less realistic, we deem it essential to test the cross-domain validity of our findings.
| Sourceen | So why is it that people jump through extra hoops to install Google Maps? |
| No High. | Quindi perché le persone devono fare un salto in più per installare Google Maps? |
| Oracle | Quindi perché le persone devono fare un salto in più per installare Google Maps? |
| Sup. | Quindi perché le persone devono fare un salto in più per installare Google Maps? |
| Unsup. | Quindi perché le persone devono fare un salto in più per installare Google Maps? |
| PE\(_{\text{No High.}}\) | Quindi perché le persone devono fare un passaggio in più per installare Google Maps? |
| PE\(_{\text{Oracle}}\) | Allora, perché le persone fanno un passaggio in più per installare Google Maps? |
| PE\(_{\text{Sup.}}\) | Quindi perché le persone fanno passaggi in più per installare Google Maps? |
| PE\(_{\text{Unsup.}}\) | Quindi perché le persone fanno i salti mortali per installare Google Maps? |
Critical Errors Before producing highlights, we manually introduce 13 critical errors into main task segments to assess post-editing thoroughness. Errors are produced, for example, by negating statements, inverting the polarity of adjectives, inverting numbers, and corrupting acronyms. We replicate the errors in both translation directions to enable direct comparison. Most of these errors were correctly identified across all three highlight modalities. Table 9.5 presents some examples of critical errors in the dataset.
| Remove negation (13-6) | |
| English | No significant differences were found with respect to principal diagnoses […] |
| Dutch | Er werden geen significante verschillen → significante verschillen gevonden met betrekking tot de belangrijkste diagnoses […] |
| Title literal translation (16-3) | |
| English | The Last of Us is an easy and canonical example of dad-ification. […] |
| Italian | The Last of Us → L’ultimo di noi è un esempio facile e canonico di dad-ification. […] |
| Wrong term (48-5) | |
| English | […], , except for alkaline phosphatase. |
| Italian | […], ad eccezione della fosfatasi alcalina → chinasi proteica. |
9.2.4 Participants
For both directions, the professional translation companies Translated and Global Textware recruited three translators for the Oracle post-editing stage, the core set of 12 translators working on Pre, Main and Post tasks, and six more translators for the QA stage, for a total of 21 translators per direction. All translators were freelancers with native proficiency in their target language and self-assessed proficiency of at least C1 in English. Almost all translators had more than two years of professional translation experience and regularly post-edited MT outputs (details in Table 9.9).
9.2.5 Editing Interface
We develop a custom interface, which we name Groningen Translation Environment (GroTE, Figure 9.2), to support editing over texts with word-level highlights. While the MMPE tool used by Shenoy et al. (2021) provide extensive multimodal functionalities (Herbig et al., 2020), we aim for a bare-bones setup to avoid confounders in the evaluation. GroTE is a web interface based on Gradio (Abid et al., 2019) and hosted on the Hugging Face Spaces to enable multi-user data collection online. Upon loading a document, source texts and MT outputs for all segments are presented in two columns, following standard industry practices. For modalities with highlights, the interface provides an informative message and supports removing all highlights from a segment via a button, with highlights on words disappearing automatically upon editing, as in (Shenoy et al., 2021). The interface supports real-time logging of user actions, allowing for the analysis of the editing process. In particular, we log the start and end times for each edited document, the accessing and exiting of segment textboxes, highlight removals, and individual keystrokes during editing.
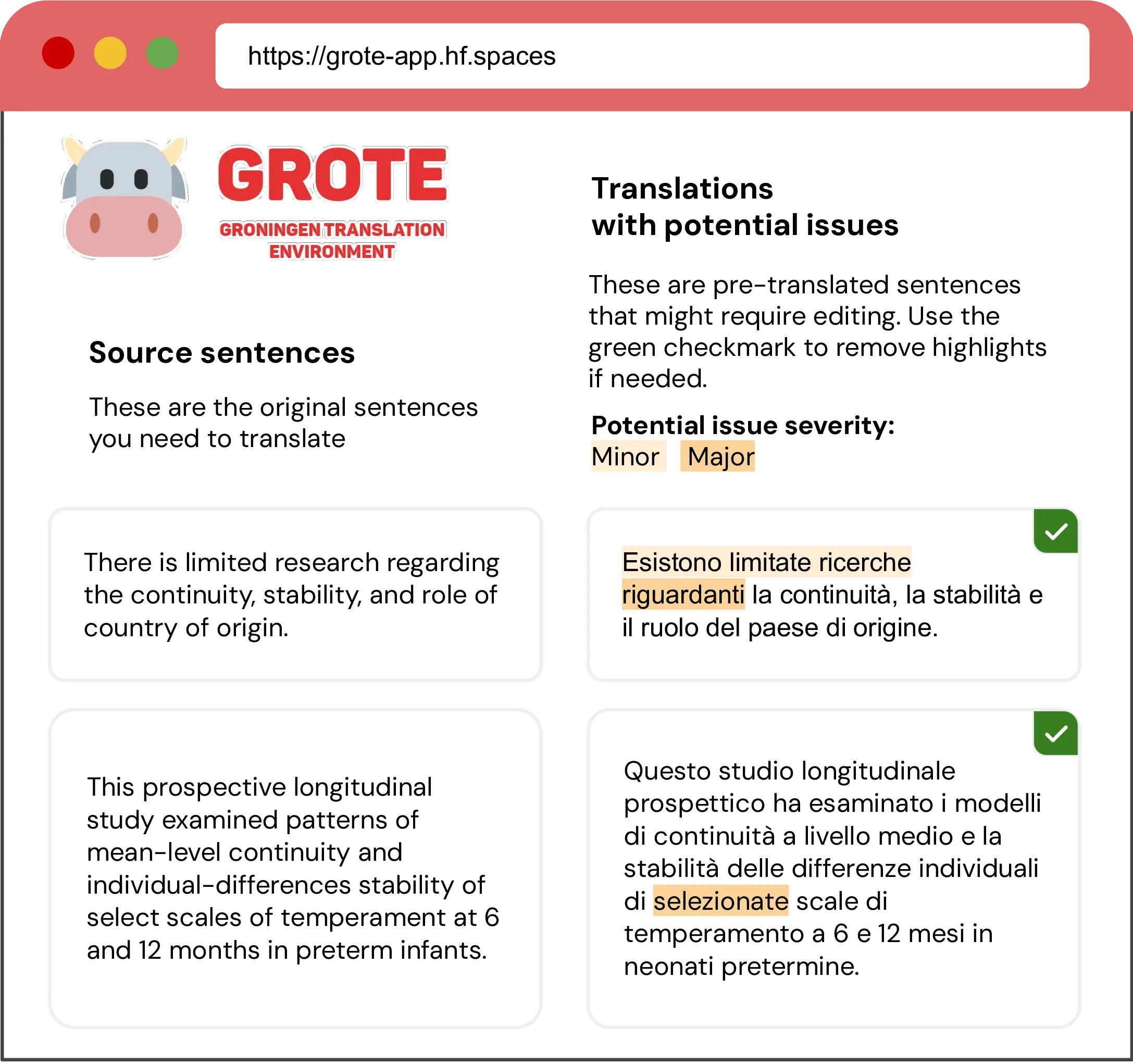
GroTE intentionally lacks standard features such as translation memories, glossaries, and spellchecking to ensure equal familiarity among translators, ultimately controlling for editor proficiency with these tools, as done in previous studies (Shenoy et al., 2021; Sarti et al., 2022). While most translators noted the lack of advanced features in our usability assessment, the majority also found the interface easy to set up, access, and use (Table 9.9).
9.3 Analysis
9.3.1 Productivity
We obtain segment- and document-level edit times and compute editing productivity as the number of processed source characters divided by the sum of all document-level edit times, measured in characters per minute. To account for potential breaks taken by post-editors during editing, we filter out pauses between logged actions longer than 5 minutes. We note that this procedure does not significantly impact the overall ranking of translators, while ensuring a more robust evaluation of editing time.
Do Highlights Make Post-editors Faster? Figure 9.3 shows translators’ productivity across stages, with every dot corresponding to the productivity of a single individual. We observe that no highlight modality consistently leads to faster editing across all speed groups and that the ordering of Pre-task speed groups is maintained in the following stages despite the different highlight modalities. These results suggest that individual variability in editing speed is more critical than highlight modality in predicting editing speed. However, the fastest English\(\rightarrow\)Dutch translators achieved outstanding productivity, i.e. \(>2\) standard deviations above the overall mean (entries with \(>300\) char/min, → in Figure 9.3) almost exclusively in No Highlight, and, Oracle modalities, suggesting that lower-quality highlights hinder editing speed.
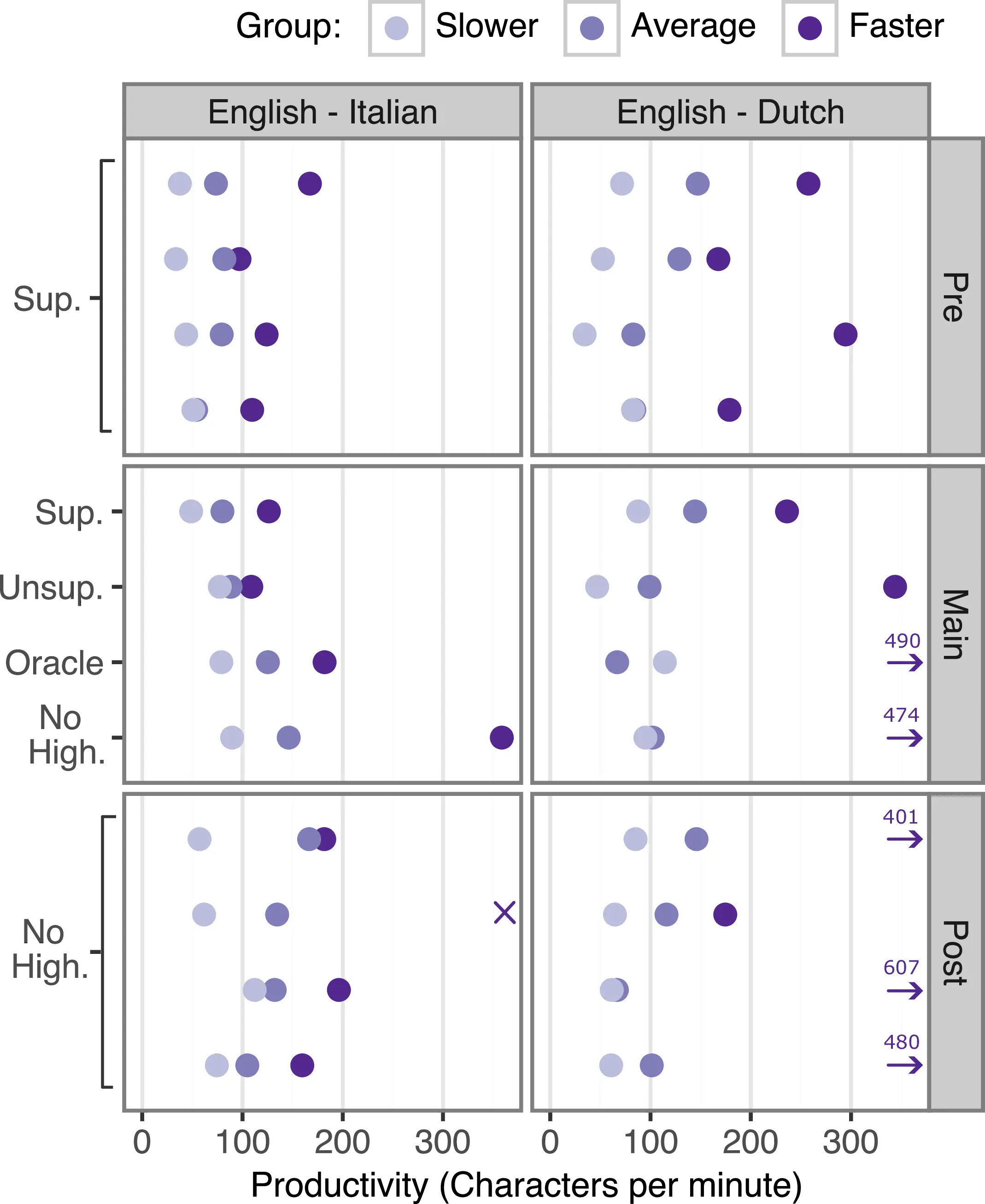
We validate these observations by fitting a negative binomial mixed-effect model on segment-level editing times (model details in Table C.10). Excluding random factors such as translator and segment identity from the model results in a significant drop in explained variance, confirming the inherent variability of editing times (\(R^2 = 0.93 \rightarrow 0.41\)). Model coefficients indicate that the output length of MT and the proportion of highlighted characters are the primary factors driving an increase in editing times, possibly reflecting an increase in cognitive effort required to process additional information. We find that highlights have a significant impact on increasing the editing speed of English\(\rightarrow\)Italian translators \((p < 0.001)\), but a minimal impact for English\(\rightarrow\)Dutch. Comparing the productivity of the same translator editing with and without highlights (Main vs Post), two-thirds of the translators editing with highlights were up to two times slower on biomedical texts. However, the same proportion of translators was up to three times faster on social media texts across both directions.
In summary, we find that highlight modalities are not predictive of edit times on their own, but translation direction and domain play an important role in determining the effect of highlights on editing productivity. We attribute these results to two main factors, which will remain central in the analysis of the following sections: (1) the different propensity of translators to act upon highlighted issues in the two tested directions, and (2) the different nature of errors highlighted across domains.
9.3.2 Highlights and Edits
We then examine how highlights are distributed across modalities and how they influence the editing choices of human post-editors.
Agreement Across Modalities First, we quantify how different modalities agree in terms of highlights’ distribution and editing. We find that highlight overlaps across modalities range from 15% to 39% when comparing highlight modalities in a pairwise fashion, with the highest overlap for English\(\rightarrow\)Italian social media and English\(\rightarrow\)Dutch biomedical texts.5 Despite the relatively low agreement on highlights, we find an average agreement of 73% for post-edited characters across modalities. This suggests that edits are generally uniform regardless of highlight modalities and are not necessarily restricted to highlighted spans.6
| Base Freq. | Measured | Projected | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| \(P(H)\) | \(P(E)\) | \(P(E|H)\) | \(\Lambda_E\) | \(P(H|E)\) | \(\Lambda_H\) | \(\vec{P}(E|H)\) | \(\vec{\Lambda}_E\) | \(\vec{P}(H|E)\) | \(\vec{\Lambda}_H\) | |
| en→it | ||||||||||
| No High. | - | 0.05 | - | - | - | - | - | - | - | - |
| Random | 0.16 | - | - | - | - | - | 0.06 | 1.20 | 0.18 | 1.20 |
| Oracle | 0.15 | 0.12 | 0.37 | 4.62 | 0.45 | 4.1 | 0.18₋₀.₁₉ | 6.00₊₁.₃₈ | 0.55₊₀.₁₀ | 4.23₊₀.₁₄ |
| Unsup. | 0.16 | 0.13 | 0.25 | 2.27 | 0.21 | 2.2 | 0.11₋₀.₁₄ | 2.75₊₀.₄₈ | 0.37₊₀.₁₆ | 2.47₊₀.₂₆ |
| Sup. | 0.12 | 0.16 | 0.28 | 2.00 | 0.22 | 2.0 | 0.14₋₀.₁₄ | 3.50₊₁.₅₀ | 0.35₊₀.₁₃ | 3.18₊₁.₁₈ |
| en→nl | ||||||||||
| No High. | - | 0.14 | - | - | - | - | - | - | - | - |
| Random | 0.17 | - | - | - | - | - | 0.16 | 1.14 | 0.19 | 1.19 |
| Oracle | 0.20 | 0.10 | 0.26 | 4.33 | 0.53 | 3.12 | 0.28₊₀.₀₂ | 2.55₋₁.₇₈ | 0.40₋₀.₁₃ | 2.35₋₀.₇₇ |
| Unsup. | 0.20 | 0.11 | 0.20 | 2.50 | 0.36 | 2.00 | 0.22₊₀.₀₂ | 1.83₋₀.₆₇ | 0.31₋₀.₀₅ | 1.72₋₀.₂₈ |
| Sup. | 0.12 | 0.09 | 0.24 | 3.43 | 0.33 | 3.30 | 0.28₊₀.₀₄ | 2.33₋₁.₁₀ | 0.24₋₀.₀₉ | 2.40₋₀.₉₀ |
Do Highlights Accurately Identify Potential Issues? Table 9.6 (Base Freq.) shows raw highlight and edit frequencies across modalities. We observe different trends across the two language pairs: for English\(\rightarrow\)Italian, post-editors working with highlights edit more than twice as much as those working with No Highlight, regardless of the highlight modality. On the contrary, for English\(\rightarrow\)Dutch they edit 33% less in the same setting. These results suggest a different attitude towards acting upon highlighted potential issues across the two translation directions, with English\(\rightarrow\)Italian translators appearing to be more inclined to perform more edits when highlights are present. We introduce four metrics to quantify highlights-edits overlap:
- \(P(E|H)\) and \(P(H|E)\), reflecting highlights’ precision and recall in predicting edits, respectively.
- \(\Lambda_E\,{\stackrel{\text{\tiny def}}{=}}\,P(E|H)/P(E|\neg H)\) shows how much more likely an edit is to fall within rather than outside highlighted characters.
- \(\Lambda_H\,{\stackrel{\text{\tiny def}}{=}}\,P(H|E)/P(H|\neg E)\) shows how much more likely it is for a highlight to mark edited rather than unmodified spans.
Intuitively, character-level recall \(P(H|E)\) should be more indicative of highlight quality compared to precision \(P(E|H)\), provided that word-level highlights can be useful even when not minimal. For example, if the fully-highlighted word traduttore is changed to its feminine version traduttrice, \(P(H|E) = 1\) (edit correctly and fully predicted) but \(P(E|H) = 0.3\) since word stem characters are left unchanged. Table 9.6 (Measured) shows metric values across the three highlight modalities7. As expected, Oracle highlights obtain the best performance in terms of precision and recall, with \(P(H|E)\), in particular, being significantly higher than the other two modalities across both directions.
Surprisingly, we find no significant precision and recall differences between Oracle and Unsupervised highlights, despite the word-level QE training of xcomet used in the former modality. Moreover, they support the potential of unsupervised, model internals-based techniques to complement or substitute more expensive supervised approaches. Still, likelihood ratios \(\Lambda_E, \Lambda_H \gg 1\) for all modalities and directions indicate that highlights are 2-4 times more likely to precisely and comprehensively encompass edits than non-highlighted texts. This suggests that even imperfect highlights that do not reach Oracle-level quality might effectively direct editing efforts toward potential issues. We validate these observations by fitting a zero-inflated negative binomial mixed-effects model to predict segment-level edit rates. Results confirm a significantly higher edit rate for English\(\rightarrow\)Italian highlighted modalities and the social media domain with \(p<0.001\) (features and significances shown in Appendix Table C.11). We find a significant zero inflation associated with translator identity, suggesting the choice of leaving MT outputs unedited is highly subjective.
Do Highlights Influence Editing Choices? Since we found in Section 9.3.1 that the proportion of highlighted characters affects the editing rate of translators, we question whether the relatively high \(P(E|H)\) and \(P(H|E)\) values might be artificially inflated by translators’ eagerness to intervene on highlighted spans. In other words, do highlights identify actual issues, or do they condition translators to edit when they otherwise would not? To answer this, we propose to project highlights from a selected modality—in which highlights were shown during editing—onto the edits performed by the No Highlight translators on the same segments. The resulting difference between measured and projected metrics can then be used as an estimate of the impact of highlight presentation on their resulting accuracy.
To further ensure the soundness of our analysis, we use a set of projected Random highlights as a lower bound for highlight performance. To make the comparison fair, Random highlights are created by randomly highlighting words in MT outputs to match the average word-level highlight frequency across all highlighted modalities, given the current domain and translation direction. Table 9.6 (Projected) shows results for the three highlighted modalities. First, all projected metrics remain consistently above the Random baseline, suggesting a higher-than-chance ability to identify errors even for worst-performing highlight modalities. Projected precision scores \(P(E|H)\) depend on edit frequency, and hence see a major decrease for English\(\rightarrow\)Italian, where the No Highlight edit rate \(P(E)\) is much lower. However, the increase in \(\Lambda_E\) across all English\(\rightarrow\)Italian modalities confirms that, despite the lower edit proportion, highlighted texts remain notably more likely to be edited than non-highlighted ones. Conversely, the lower \(\Lambda_E\), \(P(H|E)\) and \(\Lambda_H\) for English\(\rightarrow\)Dutch show that edits become much less skewed towards highlighted spans in this direction when accounting for presentation bias.
Overall, while the presence of highlights makes English\(\rightarrow\)Italian translators more likely to intervene in MT outputs, their location in the MT output often pinpoints issues that would be edited regardless of the highlighting. English\(\rightarrow\)Dutch translators, on the contrary, intervene at roughly the same rate regardless of highlight presence, but their edits are focused mainly on highlighted spans when they are present. This difference is consistent across all subjects in both directions, despite the identical setup and comparable MT and QE quality across languages. This suggests that cultural factors may play a non-trivial role in determining the usability and influence of QE methods regardless of span accuracy, a phenomenon previously observed in human-AI interaction studies Ge et al. (2024).
9.3.3 Quality Assessment
We continue our assessment by inspecting the quality of MT and post-edited outputs along three dimensions. First, we use xcomet segment-level QE ratings as an automatic approximation of quality and compare them to human-annotated quality scores collected in the last phase of our study. For efficiency, these are obtained for the 0-100 Direct Assessment scale commonly used in QE evaluation (Specia et al., 2020), but following an initial step of MQM error annotation to condition scoring on found errors, as prescribed by the ESA protocol (Kocmi et al., 2024b). Then, MQM error span annotations are used to analyze the distribution of error categories. Finally, we manually assess critical errors, which were inserted to quantify the effect of highlighting modalities on unambiguous issues.
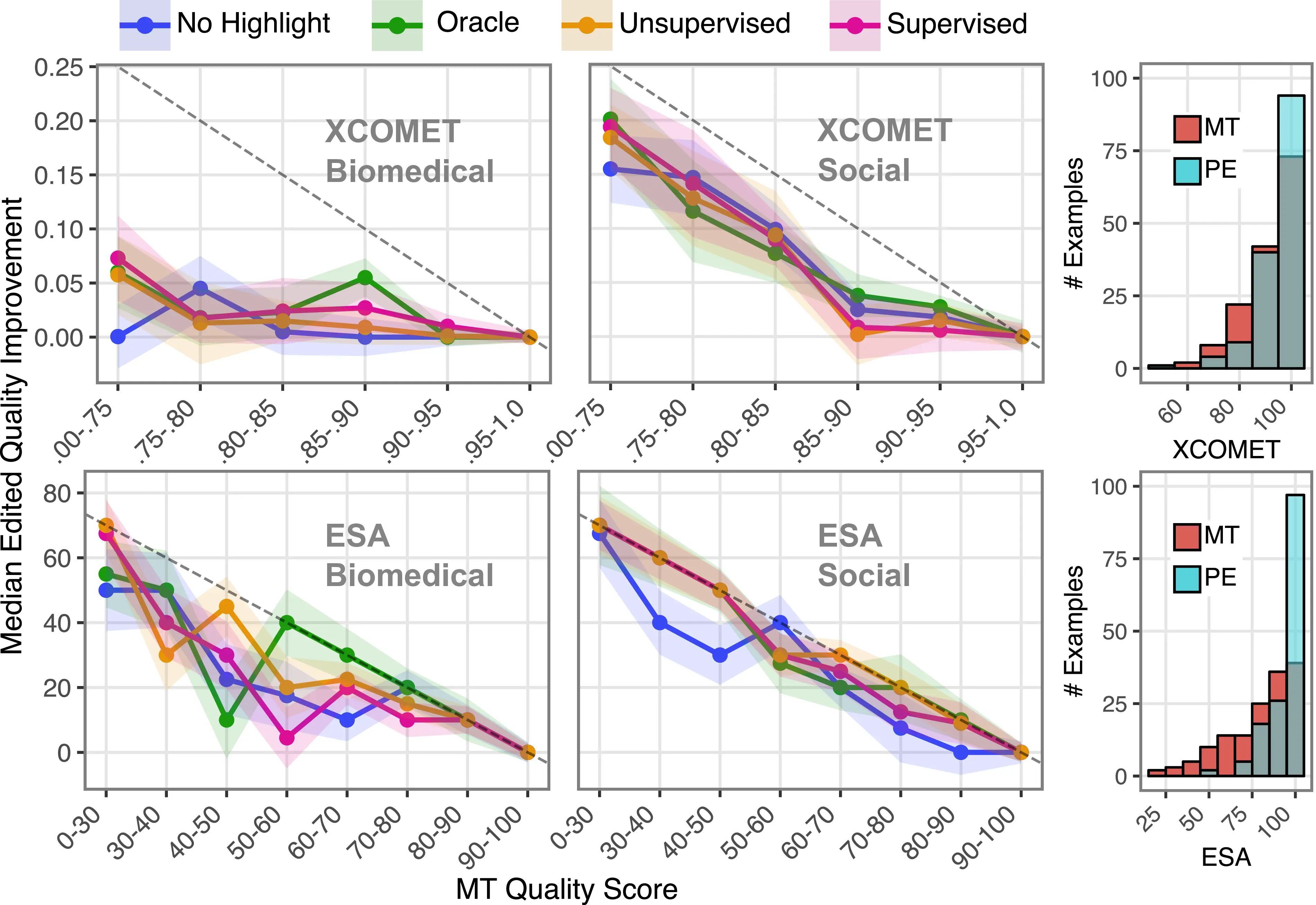
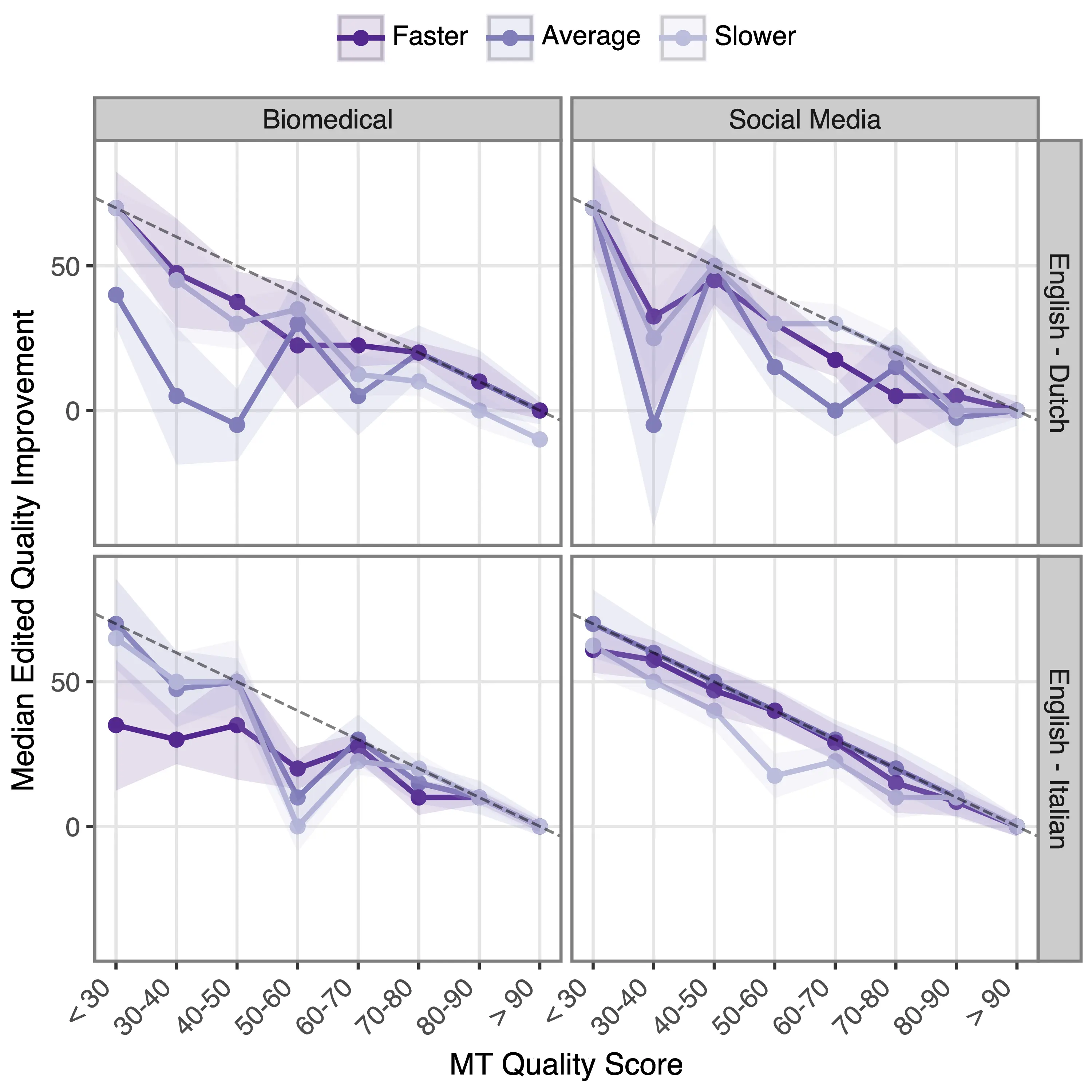
Do Highlights Influence Post-Editing Quality? In this stage, we focus particularly on edited quality improvements, i.e. how post-editing the same MT outputs under different highlight conditions influences the resulting quality of translations. We operationalize this assessment using human ratings and automatic metrics to score MT and post-edited translations, using their difference as the effective quality gain after the post-editing stage. Scores for this metric are generally positive—that is, human post-editing improves quality—and are bounded by the maximal achievable quality gain given the initial MT quality. Figure 9.4 shows median improvement values across quality bins defined from the distribution of initial MT quality scores (shown in histograms), in which all post-edited versions of each MT output appear as separate observations. Positive median scores confirm that post-edits generally lead to improvements in quality across all tested settings. However, we observe different trends across the two metrics: across both domains, xcomet greatly underestimates the human-assessed ESA quality improvement, especially for biomedical texts, where it shows negligible improvement regardless of the initial MT quality. These results echo recent findings cautioning users against the poor performance of trained MT metrics for unseen domains and high-quality translations (Agrawal et al., 2024; Zouhar et al., 2024). Focusing on the more reliable ESA scores, we observe large quality improvements from post-editing, as indicated by near-maximal quality gains across most bins and highlight modalities. While No Highlight seems to underperform other modalities in the social media domain, the lack of more notable differences in gains across highlight modalities suggests that highlights’ quality impact might not be evident in terms of segment-level quality, motivating our next steps in the quality analysis.
We also find no clear relationship between translator speed and improved edited quality, suggesting that higher productivity does not come at a cost for faster translators (Figure 9.5). This finding confirms that neglecting errors is not the cause of the different editing patterns observed in previous sections.
Which Error Types Do Highlights Identify? Table 9.7 shows a breakdown of MQM annotations for MT and all highlight modalities using the Accuracy, Style and Linguistic macro-categories of MQM errors.8 At this granularity, differences across modalities become visible, with overall error counts showing a clear relation to \(\Lambda_E\) from Table 9.6, i.e. Oracle being remarkably better for English\(\rightarrow\)Italian, with milder and more uniform trends in English\(\rightarrow\)Dutch. At least for English\(\rightarrow\)Italian, these results confirm that an observable quality improvement from editing with highlights is present in the best-case Oracle scenario. By contrast, for English\(\rightarrow\)Dutch, the Unsupervised method is found to outperform even the Oracle setting in reducing the amount of errors, while it fares relatively poorly for English\(\rightarrow\)Italian. We also observe a distinct distribution of Accuracy and Style errors, with the formers being more prevalent in biomedical texts, and the latters appearing more frequently in translated social media posts (Figure C.8). We posit that differences in error types across domains might explain the opposite productivity trends observed in Section 9.3.1. While highlighted accuracy errors might lead to time-consuming terminology verification in biomedical texts, style errors might be corrected more quickly and naturally in the social media domain.
| Language | MQM Category | MT | No Highlight | Oracle | Unsupervised | Supervised | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Maj. | Min. | Maj. | Min. | Maj. | Min. | Maj. | Min. | Maj. | Min. | ||
| Italian | Accuracy - Addition | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| Accuracy - Mistranslation | 21 | 22 | 10 | 12 | 4 | 8 | 24 | 17 | 17 | 17 | |
| Accuracy - Inconsistency | 2 | 4 | 1 | 3 | 2 | 2 | 1 | 3 | 0 | 2 | |
| Accuracy - Omission | 2 | 0 | 0 | 0 | 0 | 1 | 4 | 1 | 1 | 2 | |
| Accuracy - Untranslated | 1 | 4 | 1 | 2 | 0 | 1 | 1 | 1 | 3 | 2 | |
| Style - Inconsistent Style | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Style - Readability | 17 | 25 | 5 | 30 | 0 | 12 | 4 | 34 | 1 | 29 | |
| Style - Wrong Register | 0 | 8 | 0 | 3 | 0 | 3 | 1 | 1 | 3 | 2 | |
| Linguistic - Grammar | 6 | 15 | 2 | 16 | 0 | 5 | 3 | 12 | 2 | 12 | |
| Linguistic - Punctuation | 1 | 13 | 0 | 9 | 0 | 3 | 1 | 6 | 0 | 3 | |
| Linguistic - Spelling | 5 | 3 | 0 | 4 | 0 | 3 | 3 | 2 | 0 | 1 | |
| Total | 55 | 95 | 19 | 79 | 6 | 38 | 42 | 77 | 28 | 71 | |
| Dutch | Accuracy - Addition | 0 | 1 | 0 | 2 | 0 | 3 | 0 | 2 | 0 | 1 |
| Accuracy - Mistranslation | 25 | 34 | 18 | 25 | 23 | 27 | 12 | 31 | 16 | 29 | |
| Accuracy - Inconsistency | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 2 | 0 | 5 | |
| Accuracy - Omission | 3 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 4 | 2 | |
| Accuracy - Untranslated | 4 | 4 | 1 | 1 | 1 | 4 | 1 | 3 | 0 | 2 | |
| Style - Inconsistent Style | 2 | 0 | 0 | 5 | 1 | 7 | 0 | 2 | 0 | 9 | |
| Style - Readability | 1 | 27 | 1 | 20 | 0 | 13 | 2 | 15 | 6 | 41 | |
| Style - Wrong Register | 0 | 2 | 0 | 3 | 0 | 3 | 0 | 1 | 1 | 0 | |
| Linguistic - Grammar | 3 | 19 | 2 | 14 | 3 | 23 | 2 | 6 | 3 | 12 | |
| Linguistic - Punctuation | 0 | 6 | 0 | 3 | 0 | 4 | 0 | 2 | 0 | 3 | |
| Linguistic - Spelling | 1 | 1 | 1 | 1 | 2 | 1 | 0 | 1 | 0 | 0 | |
| Total | 39 | 95 | 24 | 77 | 32 | 88 | 18 | 66 | 30 | 104 | |
Do Highlights Detect Critical Errors? We examine whether the critical errors we inserted were detected by different modalities, finding that while most modalities fare decently with more than 62% of critical errors highlighted, Unsupervised is the only setting for which all errors are correctly highlighted across both directions (Table 9.8). Then, critical errors are manually verified in all outputs, finding that 16-20% more critical errors are edited in highlighted modalities compared to No Highlight. Hence, highlights might lead to narrow but tangible quality improvements that can go undetected in coarse quality assessments, and finer-grained evaluations might be needed to quantify future improvements in word-level QE quality.
| # Doc.-Seg. | Error Type | Has Highlight | % Post-edited | |||||
|---|---|---|---|---|---|---|---|---|
| Oracle | Unsup. | Sup. | No High. | Oracle | Unsup. | Sup. | ||
| 1-8 | Wrong number | Nld Only | Both | Both | 67 | 83 | 83 | 83 |
| 13-6 | Remove negation | Ita Only | Both | Both | 50 | 33 | 33 | 50 |
| 16-3 | Title literal translation | Both | Both | Both | 83 | 100 | 100 | 100 |
| 20-1 | Wrong acronym | Nld Only | Both | Ita Only | 0 | 33 | 33 | 33 |
| 20-7 | Wrong acronym (1) | Neither | Both | Neither | 0 | 58 | 50 | 25 |
| 20-7 | Wrong acronym (2) | Nld Only | Both | Ita Only | 0 | 58 | 50 | 25 |
| 22-1 | Name literal translation | Both | Both | Both | 50 | 50 | 83 | 67 |
| 23-4 | Addition | Nld Only | Both | Neither | 100 | 100 | 83 | 50 |
| 31-2 | Wrong acronym | Nld Only | Both | Neither | 17 | 33 | 17 | 33 |
| 34-7 | Numbers swapped | Nld Only | Both | Nld Only | 17 | 50 | 33 | 67 |
| 37-4 | Verb polarity inverted | Both | Both | Both | 67 | 83 | 67 | 83 |
| 43-5 | Wrong name | Both | Both | Both | 50 | 83 | 67 | 83 |
| 48-5 | Wrong term | Nld Only | Both | Nld Only | 67 | 50 | 83 | 83 |
| Total (%) | 65 | 100 | 62 | 44 | 63 | 60 | 60 | |
9.3.4 Usability
In the post-task questionnaire answers (Table 9.9), most translators stated that the MT outputs had an average-to-high quality and that the provided texts were challenging to translate. Highlights were generally found to be reasonably accurate, but they were generally not found helpful to improve either productivity or quality (including Oracle ones). Interestingly, despite the convincing gains for critical errors measured in the last section, most translators stated that highlights did not influence their editing and did not help them identify errors that would have otherwise been missed. Specifically, this suggests that translators may not readily perceive potential quality improvements and may consider them secondary to the extra cognitive load elicited by highlighted spans. When asked to comment about highlights, several translators called them “more of an eye distraction, as they often weren’t actual mistakes” and “not quite accurate enough to rely on them as a suggestion”. Some translators also stated that missed errors led them to “disregarding the highlights to focus on checking each sentence”. Despite their high quality, only one editor working with Oracle highlights found highlights helpful in “making the editing process faster and somehow easier”. Taken together, these comments convincingly suggest a negative perception of the quality and usefulness of highlights, indicating that improvement in QE accuracy may not be sufficient to enhance QE usefulness in editors’ eyes.
Hover bars to see avg. response values.
| Question | Italian | Dutch |
|---|---|---|
| MT outputs were generally of high quality. | ||
| Provided texts were challenging to translate. | ||
| Highlights ... | ||
| ... were generally accurate in detecting potential issues. | ||
| ... were generally useful during editing. | ||
| ... improved my editing productivity. | ||
| ... improved the quality of my translations. | ||
| ... required additional editing effort on my part. | ||
| ... influenced my choices regarding edits. | ||
| ... helped identify errors I'd have otherwise missed. |
9.4 Limitations
Our study presents certain limitations that warrant consideration when interpreting its findings and guiding future research.
Firstly, while we included two domains and translation directions to improve the generalizability of our findings, our results suggest that language and domain play a crucial role in determining the effectiveness of word-level QE for human post-editing. While we observed mild gains from word-level QE on our tested mid-resourced translation directions (English\(\rightarrow\)Italian and English\(\rightarrow\)Dutch), we expect limited, if any, benefit of such approaches in low-resource languages and domains for which MT systems and QE methods are likely to underperform (Sarti et al., 2022; Zouhar et al., 2024). Furthermore, the domains tested in our study (biomedical and social media posts) provided concrete challenges in the form of specialized terminology and idiomatic expressions, respectively, which are known to hinder the quality of MT outputs (Neves et al., 2024; Bawden and Sagot, 2023). While future work should ensure that our findings can be extended to other domains and languages, the limited benefits brought by the tested word-level QE methods in challenging settings suggest a limited usefulness for higher-resource languages and more standard domains, such as news or Wikipedia texts.
Secondly, we acknowledge that several design choices in our evaluation setup, rather than about the QE methods themselves, may have influenced our results. These include, for instance, the specific procedure for discretizing continuous scores from the Unsupervised method into error spans, and the method of obtaining Oracle highlights via majority voting among post-editors. While we believe these choices are justified within the context of our study, their impact on the outcomes cannot be entirely discounted. Future studies might benefit from a more fine-grained assessment of how such low-level decisions influence the perceived accuracy and usability of word-level QE.
Finally, subjective factors such as the translators’ inherent propensity to edit, their prior opinions on the role of MT in post-editing, and their individual editing styles inevitably influenced both quantitative and qualitative assessments in this study. We attempted to mitigate these effects by ensuring a uniform and controlled evaluation setup for all 42 professional translators and by employing averaged judgments for translators working on the same highlight modality. However, we acknowledge that post-editor subjectivity might limit the reproducibility of our findings.
9.5 Broader Impact and Ethical Considerations
Our study explicitly centers the experience of professional translators, responding to recent calls for user-centered evaluation of translation technologies. By prioritizing translators’ perspectives and productivity, we aim to contribute to methods that complement rather than replace human expertise. Our findings highlight a gap between user perception and measured quality improvements, suggesting that future efforts should focus primarily on improving the usability of these methods in editing interfaces. In particular, new assistive approaches for post-editing should not only strive to increase productivity but also reduce the cognitive burden associated with post-editing work. This insight is crucial for designing more user-centered quality estimation tools that genuinely support human work. Ultimately, our results suggest that subjective norms across different domains and cultures play an important role in determining the effectiveness of proposed methodologies, underscoring the importance of accounting for human factors when designing such evaluations. All participants in this study were professional translators who provided informed consent. The research protocol ensured anonymity and voluntary participation, with translators recruited and remunerated through professional translation providers. The study’s open data release further promotes transparency, enabling other researchers to reproduce and build upon our findings.
9.6 Conclusion
Our QE4PE study evaluated the impact of various error-span highlighting modalities, including automatic and human-made ones, on the productivity and quality of human post-editing in a realistic professional setting. Our findings highlight the importance of domain, language and editors’ speed in determining the effect of highlights on productivity and quality, underscoring the need for broad evaluations encompassing diverse settings. The limited gains of human-made highlights over automatic QE and their indistinguishable perception from editors’ assessment indicate that further gains in the accuracy of these techniques might not be the determining factor in improving their integration into post-editing workflows. In particular, future work might explore other directions to further assess and improve the usability of word-level QE highlights, for example, by studying their impact on non-professional translators and language learners, or by combining them with edit suggestions to justify the presence of error spans.
While our QE4PE study included a preliminary assessment of unsupervised methods for word-level QE, the next chapter expands our investigation by conducting a broad evaluation of unsupervised word-level QE methods for post-editing, including a comparison with state-of-the-art supervised approaches. In light of our results showing the user-dependent effectiveness of quality estimation, we also inspect how the presence of multiple human annotations influences the quality assessment of identified error spans.
Dataset:
gsarti/qe4pe; Interface:gsarti/grote; Code: https://github.com/gsarti/qe4pe↩︎We do not disclose the highlight modality to translators to avoid biasing their judgment in the evaluation.↩︎
See Table C.15 for annotation examples.↩︎
Highlights are extended from tokens to words to match the granularity of other modalities.↩︎
Scores are normalized to account for highlight frequencies across modalities. Agreement is shown in Table C.12.↩︎
Editing agreement is shown in Figure C.6.↩︎
Breakdowns by domain and speed shown in Table C.14 and Table C.13↩︎
Per-domain breakdown in Figure C.8.↩︎