6 Retrieval and Marking for Attribute-Controlled Translation
Like physical events with their causal and teleological interpretations, every linguistic event had two possible interpretations: as a transmission of information and as the realization of a plan.
– Ted Chiang, Stories of Your Life and Others (2002)
6.1 Introduction
Text style transfer (TST) is a task that aims to control stylistic attributes of an input text without affecting its semantic content (Jin et al., 2022). Research in TST has focused mainly on English, thanks to the availability of large monolingual English datasets that cover stylistic attributes such as formality and simplicity (Rao and Tetreault, 2018; Zhu et al., 2010). In recent years, however, multilingual and cross-lingual applications of TST have steadily gained popularity (Briakou et al., 2021; Garcia et al., 2021; Krishna et al., 2022). A notable instance of cross-lingual TST is attribute-controlled translation (ACT), in which attribute1 conditioning is performed alongside machine translation to ensure that translations are not only correct but match user-specified preferences, such as formality/honorifics (Sennrich et al., 2016; Niu et al., 2017; Michel and Neubig, 2018; Niu and Carpuat, 2020; Nadejde et al., 2022; Wang et al., 2023), gender (Rabinovich et al., 2017; Vanmassenhove et al., 2018; Saunders and Byrne, 2020), and length (Lakew et al., 2019; Schioppa et al., 2021). ACT is crucial for sectors such as customer service and business communication, where stylistic differences can significantly impact user perception (e.g., misgendering customers or speaking to them in an inappropriately informal tone can be perceived as offensive or disconcerting). Table 6.1 shows examples of ACT for formality and gender attributes.
| Formality-Controlled Translation (CoCoA-MT) | |
|---|---|
| Neutral Src (EN) | OK, then please follow me to your table. |
| Formal Ref (JA) | ではテーブルまで私について来てください。 |
| Informal Ref (JA) | ではテーブルまで私について来て。 |
| Gender-Controlled Translation (MT-GenEval) | |
|---|---|
| Neutral Src (EN) | After retiring from teaching, Cook became a novelist. |
| Feminine Ref (NL) | Nadat ze stopte met lesgeven, werd Cook schrijfster. |
| Masculine Ref (NL) | Nadat hij stopte met lesgeven, werd Cook schrijver. |
Most prior work on ACT relies on a supervised adaptation component that conditions the generative model on the selective attribute. However, few annotated ACT datasets are available, and they generally cover only a limited set of languages and attributes. Thus, enabling few-shot or zero-shot ACT would facilitate applying attribute control to less-resourced attributes and languages.
As a first step into our investigation of conditioning machine translation generation, this chapter introduces a new approach for ACT: Retrieval and Attribute-Marking enhanced Prompting (Ramp). Recent studies have shown that large language models can perform MT out of the box using the prompting paradigm (Brown et al., 2020; Lin et al., 2022; Chowdhery et al., 2023). We build on this, prompting LLMs to perform attribute-controlled MT through two innovations: (1) retrieval of similar examples and (2) explicit attribute marking.
Recent works adopting the prompting paradigm for text style transfer have mainly focused on the generalization capabilities of large English-centric LMs for zero-shot style transfer using previously unseen style descriptions (Suzgun et al., 2022; Reif et al., 2022). However, prior work on other NLP tasks has shown that cross-lingual prompting of multilingual LLMs can be effective (Zhao and Schütze, 2021; Zhou et al., 2023; Huang et al., 2022). As such, we leverage multilingual LLMs and extend their ACT capabilities cross-lingually to languages not covered by the in-context examples, thus enabling zero-shot ACT.
6.2 Method
Attribute-Controlled Translation ACT takes two inputs, a sentence \(\mathbf{x}\) and a desired target attribute \(a \in A\) (with \(A\) being the space of attributes), and outputs a translation \(\mathbf{y}\) that complies with the specified attribute. It can be formulated as a function \(f: (\mathbf{x},a)\rightarrow\mathbf{y}\). In our experiments, we use attribute values provided by the CoCoA-MT formality translation dataset and the MT-GenEval gender translation dataset, i.e., \(A=\) {formal, informal} or {female, male}.2
Prompting In the prompting paradigm for decoder-only LLMs, inputs are given as decoding prefixes to the model, usually combined with natural language instructions for output generation. In style-controlled translation, we formulate the prompt for target language \(l\) and attribute \(a\) using the text “Here is a sentence: {\(\underline{\mathbf{x}}\)} Here is its \(\underline{l}\) translation written in a \(\underline{a}\) style:” to produce the output \(\mathbf{y}\).3 In the few-shot setting, we provide a sequence of \(k\) labeled in-context examples before the unlabeled input, which can be formulated as a function \(f: \{(\mathbf{x}_1, l_1, a, \mathbf{y}_1),\dots, (\mathbf{x}_{k+1}, l_{k+1}, a)\}\rightarrow\mathbf{y}_{k+1}\).
6.2.1 Our Approach: Ramp
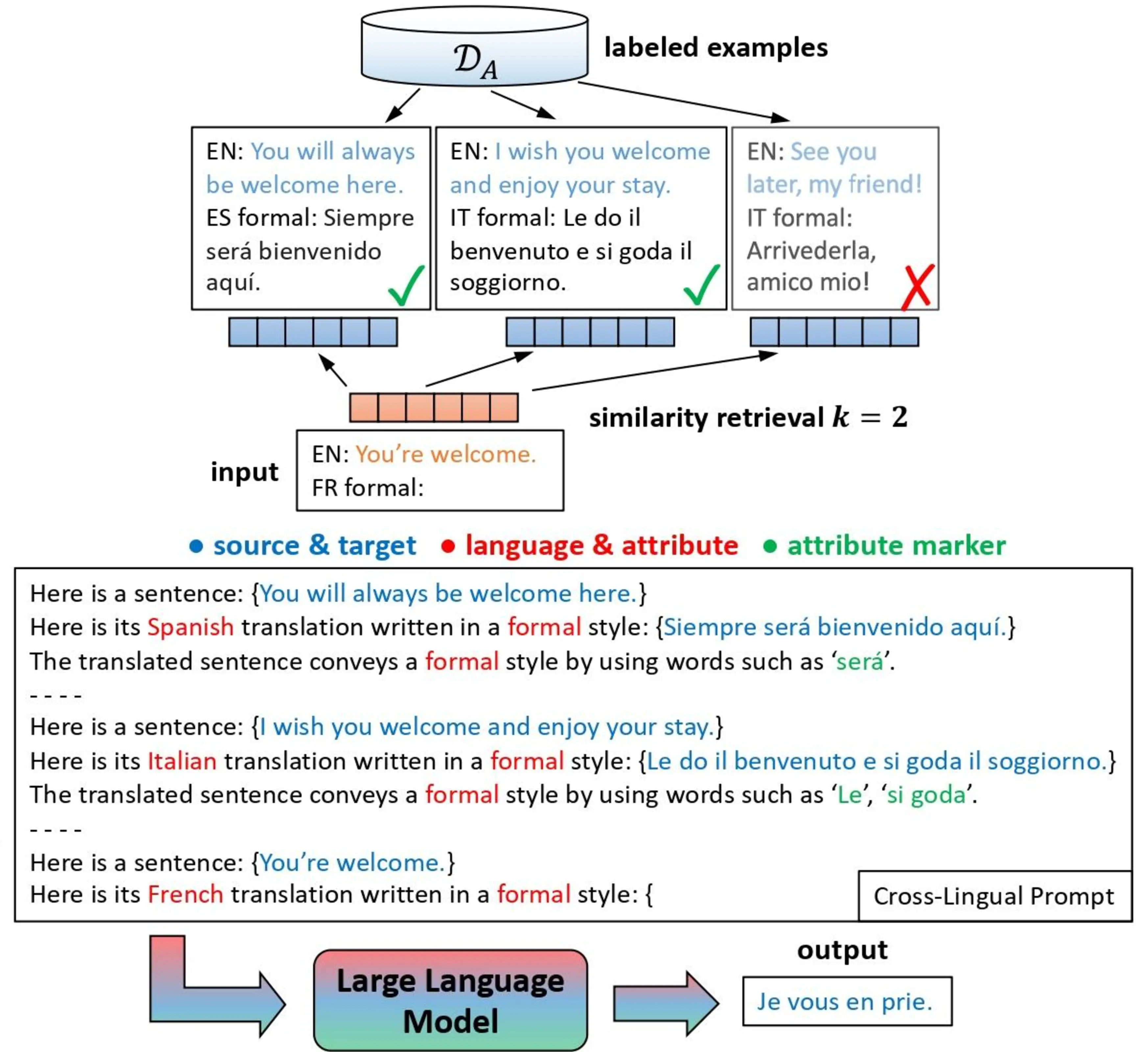
Ramp builds on the success of the prompting paradigm on few-shot generation tasks such as monolingual text style transfer (Reif et al., 2022) and MT (Garcia and Firat, 2022; Agrawal et al., 2023) by creating more informative prompts through similarity retrieval and attribute marking. See Figure 6.1 for an illustration of Ramp.
Similarity Retrieval In standard prompting, in-context examples are sampled randomly from the pool of labeled examples \(\mathcal{D}_A\). In Ramp, we select examples based on their similarity with the input text. We first embed both the input text and the source texts of \(\mathcal{D}_A\) using all-MiniLM-L6-v2 (Wang et al., 2020). Then, the top-\(k\) most similar examples are retrieved for the input text based on cosine similarity. These are then used in a descending order based on their cosine similarity as in-context examples in the inference prompt. As demonstrated in Figure 6.1, the in-context example “You will always be welcome here.” has the highest similarity to the test example “You’re welcome.”, so it is prompted first.
Attribute Marking In standard prompting, in-context examples are provided without explicit information on why they satisfy the prompting objective. Inspired by recent studies that have shown that decomposition of complex tasks can improve prompting quality (Nye et al., 2022; Wei et al., 2022), we include for every in-context example an additional sentence directly after the target sentence that specifies which text spans convey the desired attribute (e.g., “The translated sentence conveys a formal style by using words such as ‘Vous’.”). In our experiments, we use the gold attribute spans included in the CoCoA-MT and MT-GenEval datasets. In Section 6.5 we suggest possibilities for automatically deriving attribute spans when gold training labels are not available.
6.2.2 Cross-Lingual Prompting
The similarity retrieval component of Ramp requires a large pool \(\mathcal{D}_A\) from which to find appropriate in-context examples for prompting. Low-resource attributes or language pairs may have insufficient or no annotated data from which to retrieve such examples. To mitigate this issue, we introduce cross-lingual prompting, in which the target side of the in-context examples differs from the desired target language of the translation task. As demonstrated in Figure 6.1, we investigate whether the system can leverage examples in one language (e.g., attribute indicators in Spanish) to produce the same attribute in another (e.g., French). Two main features of our Ramp model allow us to perform cross-lingual prompting: (1) the use of multilingual LLMs, and (2) the example retrieval step, which is done on the source language only.
6.3 Experiments
In this section, we describe the datasets, LLMs, and baselines used in our experiments, as well as the evaluation metrics. We then present the results of Ramp in both same-language and cross-lingual prompting settings.
6.3.1 Datasets
We experiment on two multilingual ACT datasets:
- CoCoA-MT (Nadejde et al., 2022) covers formality-controlled translation in the conversation domain. Source sentences are underspecified for formality, and references require formality markings (formal or informal).
- MT-GenEval (Currey et al., 2022) covers gendered translation in the Wikipedia domain. We use the contextual subset, in which sentences are gender ambiguous in the source while the reference requires gender marking. We do not use the disambiguating sentences; instead, we explicitly control the target gender.
Both datasets have gold annotations for attribute-marked target spans, and both cover translation from English into multiple diverse target languages. We list their target languages in Table 6.2.
| AR | Arabic | DE | German | EN | English |
| ES | Spanish | FR | French | HI | Hindi |
| IT | Italian | JA | Japanese | NL | Dutch |
| RU | Russian |
| AR | ES | FR | HI | PT | DE | IT | JA | RU | NL | |
|---|---|---|---|---|---|---|---|---|---|---|
| CoCoA-MT | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| MT-GenEval | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| XGLM | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| BLOOM | ✓ | ✓ | ✓ | ✓ | ✓ |
6.3.2 Large Language Models
We select three massively multilingual decoder-only LLMs for the prompting experiments:
XGLM (Lin et al., 2022) is a 7.5B-parameter model trained on a balanced corpus containing 30 languages. It was shown to outperform much larger models such as GPT-3 on tasks related to machine translation and cross-lingual language understanding. We select it due to its broad linguistic coverage and its manageable size.
Bloom (BigScience Workshop et al., 2022) is a model available in multiple sizes, trained on a curated corpus spanning 46 natural languages (and 13 programming languages). However, many of the test languages are not part of its pre-training corpus (see Table 6.2). We evaluate two variants of the model (7.1B and 175B parameters) to assess how it is affected by a massive scaling in model parameters. The larger variant has a parameter count comparable to that of GPT-3, making it the largest publicly available multilingual LLM at present.
GPT-NeoX (Black et al., 2022) is a 20B-parameter model trained on The Pile (Gao et al., 2021), a large English-centric corpus covering a broad range of domains. While the model was primarily trained on English data and is therefore not intended for multilingual usage, it exhibits interesting generalization performance for many of our target languages.
The selected models span three orders of magnitude in terms of number of parameters and differ in the languages that they cover (see Table 6.2).
6.3.3 Baseline
Attribute tagging is a standard method for ACT, so we include a baseline following the approach and configuration used by Nadejde et al. (2022), i.e. an encoder-decoder transformer MT model (Vaswani et al., 2017) pre-trained on public parallel data and further finetuned on contrastive training pairs with attribute tags (from either CoCoA-MT or MT-GenEval) such as <formal>, <informal>, <masculine> and <feminine>. We refer to these models as adapted MT in our evaluation.
| Dataset | Attribute | # Train | # Test | Acc. |
|---|---|---|---|---|
| CoCoA-MT | Formality | 7,600 | 1,596 | 0.990 |
| MT-GenEval | Gender | 4,900 | 9,854 | 0.970 |
6.3.4 Evaluation Metrics
We measure translation quality with BLEU (Papineni et al., 2002) and comet (Rei et al., 2020). For attribute accuracy, we use the lexical matching metrics provided with CoCoA-MT and MT-GenEval (Lexical-Accuracy) and sentence encoders trained on contrastive examples (Sentential-Accuracy). For the latter, we train multilingual classifiers on top of the mDeBERTa-v3 encoder (He et al., 2023). High-performance pre-trained classifiers have been shown to produce attribute accuracy estimates closer to human judgments for style transfer (Lai et al., 2022). Table 6.3 presents the accuracy of the classification models on the test sets of their respective datasets, averaged across all languages.
We use the original train/test split provided by the CoCoA-MT dataset. Each split contains telephony and topical_chat domains. We use the topical_chat domain in our experiments. MT-GenEval contains a dev and test split, and we use the dev split as training data for the classification model and prompting experiments.
We finetune mDeBERTa-v3-base model4 on the contrastive examples in the respective training sets to obtain the attribute classifiers. We fine-tune the classifier for two epochs with a batch size of 8, a learning rate of 2e-5, 500 warm-up steps, a max sequence length of 256, and save checkpoints every 500 steps. We do not do hyperparameter tuning, and thus, a validation set is not used.
Unlike lexical accuracy, the multilingual attribute classifier does not penalize text generated in incorrect languages. Thus, in cross-lingual prompting experiments, we include a step of language detection5 so that generated sentences not in the requested target language are considered incorrect.
6.3.5 Same-Language Prompting
We first evaluate the effectiveness of Ramp for formality- and gender-controlled translation where the language pair used for in-context examples is the same as the one used in the prompt candidate (e.g., English\(\to\)Spanish formality-controlled translation using English\(\to\)Spanish in-context examples).
We begin by conducting a preliminary evaluation of 3 LLMs across different ranges of in-context examples to reduce the number of experimental settings for our main assessment. We perform formality-controlled translation using CoCoA-MT, and evaluate LLMs by varying the number of in-context examples (i.e., 4-8-16-32, selected based on the feasible context length6). Figure 6.2 presents results averaged across all four languages seen by Bloom during its pre-training.
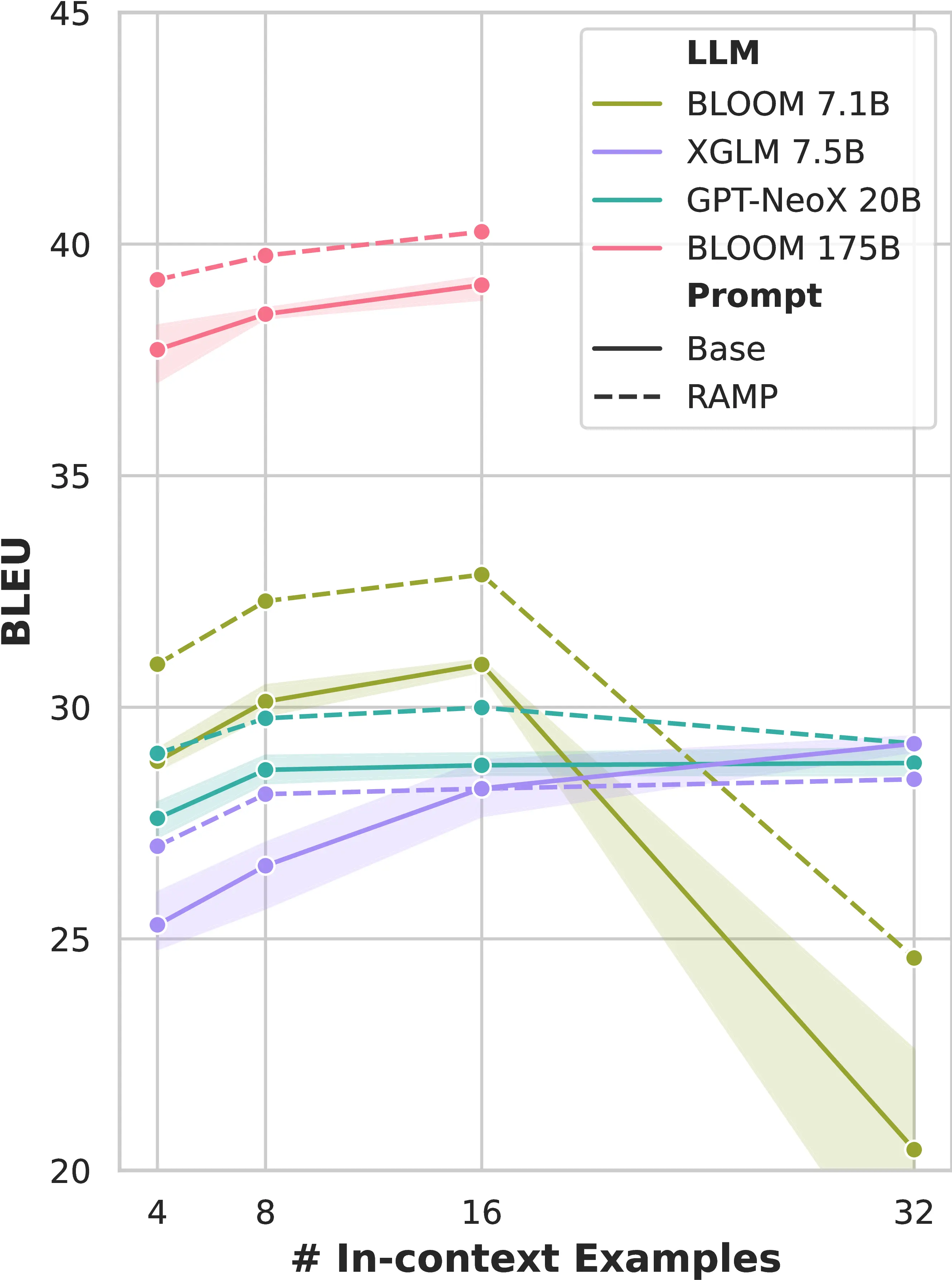
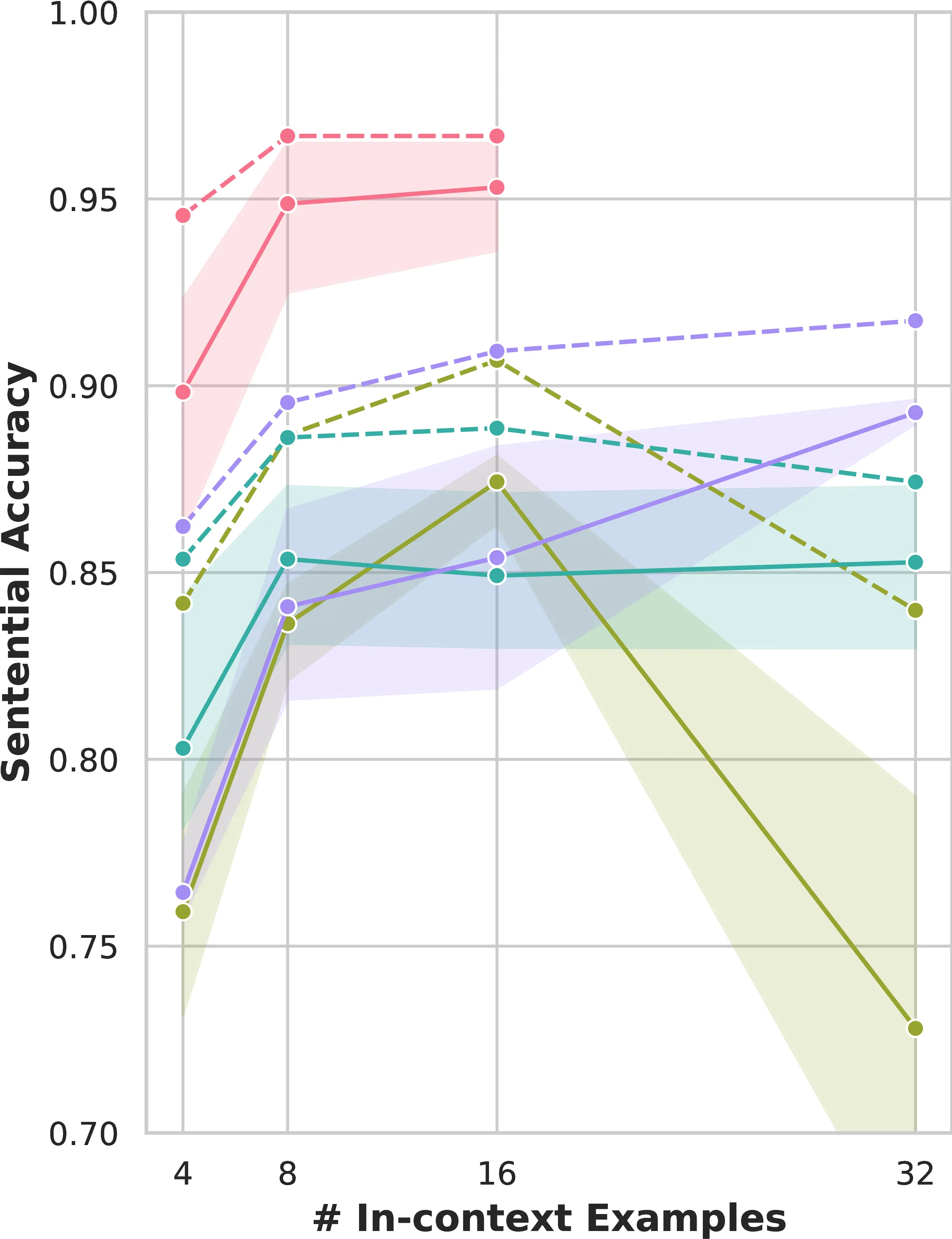
We observe that Ramp generally outperforms base prompting (i.e., random in-context examples and no attribute marking) across most LLMs and example settings for both BLEU and formality accuracy. Moreover, BLEU and formality accuracy improve with increased model size and with the number of examples, until this number reaches 16. Based on these results, we move forward with the main evaluation using XGLM 7.5B and Bloom 175B models and 16 in-context examples for both datasets.
Table 6.4 presents our main results alongside the adapted MT baseline. The base model uses in-context examples that are randomly sampled from the pool of labeled examples. We also include an ablation that adds only attribute marking on top of base prompting, without similarity retrieval (+mark).
| CoCoA-MT | MT-GenEval | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BLEU | COMET | L-Acc | S-Acc | BLEU | COMET | L-Acc | S-Acc | |||
| Same-Language | XGLM 7.5B | base | 28.6 | 0.463 | 0.835 | 0.846 | 23.7 | 0.445 | 0.790 | 0.727 |
| +mark | 28.7 | 0.423 | 0.920 | 0.902 | 23.7 | 0.444 | 0.789 | 0.732 | ||
| Ramp | 30.0 | 0.451 | 0.938 | 0.923 | 24.8 | 0.473 | 0.836 | 0.820 | ||
| BLOOM 175B | base | 39.9 | 0.691 | 0.930 | 0.940 | 33.3 | 0.679 | 0.748 | 0.704 | |
| +mark | 40.3 | 0.688 | 0.970 | 0.970 | 33.1 | 0.674 | 0.759 | 0.725 | ||
| Ramp | 41.9 | 0.711 | 0.973 | 0.970 | 34.3 | 0.699 | 0.817 | 0.818 | ||
| Adapted MT | 38.5 | 0.454 | 0.691 | 0.693 | 39.6 | 0.750 | 0.842 | 0.864 | ||
| Cross-Lingual | BLOOM 175B | base | 32.1 | 0.644 | 0.567 | 0.596 | 28.5 | 0.469 | 0.777 | 0.633 |
| Ramp | 31.8 | 0.646 | 0.625 | 0.622 | 29.4 | 0.502 | 0.788 | 0.673 | ||
We observe that in the +mark setting, simple attribute marking consistently improves attribute accuracy of the generated text, but leads to degradation of comet on CoCoA-MT. The complete Ramp with similarity retrieval not only compensates for the comet degradation but also improves quality and attribute metrics across the board, especially for the high-capacity Bloom 175B model.
Adapted MT outperforms Bloom 175B on MT-GenEval in all metrics, but underperforms it on CoCoA-MT. This suggests that it is challenging to conduct a fine-grained comparison between LLMs and standard MT systems, as they may have different domain coverage. Bloom 175B consistently outperforms XGLM 7.5B in both generic translation quality and attribute control accuracy, so we focus on Bloom 175B for our cross-lingual prompting analysis.
6.3.6 Cross-Lingual Prompting
We have demonstrated the effectiveness of selecting similar same-language examples to build the prompt, echoing related work (Liu et al., 2022; Agrawal et al., 2023). In this section, we evaluate the cross-lingual prompting option, i.e., retrieving in-context examples from other target languages besides the desired language of translation. We test this zero-shot setting using the leave-one-out strategy, i.e. we retrieve in-context examples from every language except the desired language of translation. We ensure that we retrieve an equal number of examples from all languages: the number of examples retrieved from each language is the total desired number of in-context examples divided by the number of training languages. In CoCoA-MT, we retrieve 14 in-context examples from 7 languages. In MT-GenEval, we retrieve 8 in-context examples from 8 languages.7 Finally, results are averaged across tested language pairs. Languages that are not seen during the LLM pre-training are included among in-context examples, but not as the target language of the translation task.
Table 6.4 (bottom) presents our results using Bloom 175B. On both test sets, compared to the baseline, we observe improved attribute accuracy and comparable or better generic translation quality when using Ramp with cross-lingual prompting.
We observe translation quality degradation with Ramp on some target languages of CoCoA-MT, such as Spanish. Manual analysis shows that repeatedly inaccurate retrieval results could lead to hallucinations.8 For example, Ramp retrieves multiple sentences containing “million” for the input If you got it why not? He is worth over 20 billion dollars after all. This results in mistranslation of billion to million (millionario): Si lo tienes, ¿por qué no? Es millonario después de todo. We give detailed examples in Section B.1.3. This is a known issue with retrieval-based prompting (Liu et al., 2022; Agrawal et al., 2023), which can be mitigated by using more diverse in-context examples or a larger pool of training data for retrieval.
6.4 Limitations
We delineate some limitations of our approach and discuss future work directions.
Example Availability and Prompt Sensitivity The proposed formulation of the Ramp method relies on gold annotations for attribute marking, which are not always available depending on the dataset. However, Ramp could be easily extended to unsupervised settings through LLM input attribution methods, such as those we presented in the previous part of this thesis. This approach builds upon recent techniques in unsupervised language generation metrics (Fomicheva et al., 2021; Fomicheva et al., 2022; Leiter et al., 2024). Apart from the choice of in-context examples, prompting is also sensitive to their ordering (Lu et al., 2022) and the design of the template (Jiang et al., 2020). We refrain from tuning example orders and templates to avoid introducing too many variables, but we acknowledge that this could lead to suboptimal results.
Unseen Languages, Computational Resources and Diversity Multilingual LLMs perform competitively on machine translation for languages seen during their pre-training. However, we noticed that Bloom 175B produces better English\(\to\)Italian translations than XGLM 7.5B even though Italian is not listed among Bloom’s training languages. This could be due to typological similarity between Italian and the Romance languages included in Bloom training. Multilingual LLMs such as Bloom also require significantly more GPU resources for inference than standard bilingual MT systems do, making them less practical for production deployment. Finally, the MT-GenEval test set is limited in providing only two gender labels (female and male) as minimal pairs, while neutral rewriting is not represented.
6.5 Conclusion
As a first step in our exploration of conditioning machine translation generation, we introduced the Ramp in-context learning for better conditioning performance through the use of attribute annotations and similar retrieved examples. We demonstrated its effectiveness with multilingual LLMs for both formality-controlled and gender-controlled translation, showing that it improves attribute accuracy and translation quality over standard prompting and adapted MT baselines, including in cross-lingual settings using relevant in-context examples from other languages. In the next chapter, we expand our investigation to steering methods that intervene directly in the inner processing of LLMs and study their effectiveness for personalization in the challenging domain of literary machine translation.
We employ the term attribute rather than style, since not all the attributes addressed here (e.g., gender) can be considered styles.↩︎
See Section 6.4 for ethical considerations.↩︎
We adopt prompt templates similar to the one used by Reif et al. (2022), and we write the prompt template in English. Complete templates are provided in Section B.1.1.↩︎
Bloom 175B encountered out-of-memory errors with 32 in-context examples on 8 A100 40GB GPUs.↩︎
We reduced the number of in-context examples in this setting to avoid out-of-memory errors with Bloom 175B.↩︎
Vilar et al. (2023) also observe hallucinations when the retrieved examples have bad translations (i.e., non-parallel sentences).↩︎