7 Steering Language Models for Personalized Machine Translation
I don’t speak, I operate a machine called language. It creaks and groans, but is mine own.
– Frank Herbert, Dune Messiah (1969)
7.1 Introduction
When we read a translated book, we do not simply read the story in a new language; we also experience the translator’s personal voice through their stylistic choices. Past efforts in the automatic translation of literary works have historically been constrained by the limited capabilities and flexibility of machine translation systems. The recent popularization of MT systems based on large language models has significantly improved their capacity to handle the long contexts typical of literary translations, but mimicking the creative and rich language that characterizes the translators’ own style remains an open issue. In this context, several works have explored the use of prompting and tuning-based strategies to ensure that translations are stylistically appropriate (Michel and Neubig, 2018; Wang et al., 2021). However, their influence on model internal representations is rarely explored, making their impact less controllable and often unpredictable. Building upon the prompting techniques demonstrated in Chapter 6, this chapter tackles the more complex challenge of personalizing machine translation to match individual translator styles. While Ramp focused on explicit attributes like formality and gender, literary translation requires capturing the subtle, implicit stylistic preferences that characterize individual translators’ voices. For this purpose, we compare prompting approaches with steering methods proposed in interpretability literature. These techniques can be used to surgically intervene on LLMs’ intermediate representation to generate personalized translations when few examples are available, using the Par3 dataset (Thai et al., 2022) with multiple human translations for novels translated into English from 7 typologically diverse languages.
We begin with preliminary assessments by verifying whether translators’ styles are discernible by automatic systems, finding that trained classifiers can distinguish writing styles with high accuracy, while the task is notoriously challenging for human annotators (Youyou et al., 2015; Flekova et al., 2016). We also find a simple prompting setting with in-context personalization examples to improve the style accuracy of LLM translation, suggesting personalized translation styles are reproducible. We connect the conditioning induced by prompting to the inner workings of the model, identifying activations with high discriminative capacity for style differences in intermediate model layers. We then propose a contrastive steering approach based on sparse autoencoders (SAEs, Huben et al. (2024)) to condition model generations by upweighting sparse, interpretable latents at inference time. We validate the effectiveness of our method across three LLMs of various sizes on Par3 novels, comparing our results with established prompting and steering methods.
Our results show that contrastive SAE steering is a promising approach for MT personalization, resulting in translations that not only align more closely with general human translation features but also with the desired personalized style compared to other methods. Importantly, these results are achieved with no degradation in translation quality, according to established MT quality metrics. We conclude by comparing the impact of our method on model representations with the outcome of multi-shot prompting, finding that probes trained on prompt-conditioned activations can predict the effectiveness of SAE steering with high precision. These results confirm that tested prompting and steering techniques converge to similar solutions for conditioning model behavior, enabling future investigations into the mechanistic impact of prompting through the study of learned SAE latents and other interpretable components.
7.2 Related Work
Machine Translation of Literary Texts The literary domain has historically been challenging for automatic MT systems due to their limited ability in handling rich linguistic and cultural contexts (Matusov, 2019) and their propensity to produce overly literal outputs (Guerberof-Arenas and Toral, 2022). Automatic literary translation has a long history dating back to pre-neural MT approaches (Voigt and Jurafsky, 2012; Toral and Way, 2015; Toral and Way, 2018; Moorkens et al., 2018) with two recent dedicated evaluation campaigns (Wang et al., 2023b; Wang et al., 2024a). The advent of LLMs has brought new opportunities in processing longer contexts for document-level translation (Wang et al., 2023a; Briakou et al., 2024; Wu et al., 2025), but critical errors requiring human translators’ intervention nonetheless persist (Karpinska and Iyyer, 2023). Here, we use the Par3 dataset (Thai et al., 2022) containing multiple human translations of novels to evaluate MT personalization in the literary domain.
Personalization for Machine Translation Advances in MT quality recently led to a growing interest in personalization approaches to ensure a consistent format and appropriate stylistic choices in model generations (Rabinovich et al., 2017; Lin et al., 2021). Previous approaches for controlling attributes such as formality (Sennrich et al., 2016; Niu et al., 2017; Nadejde et al., 2022) or gender (Vanmassenhove et al., 2018; Saunders and Byrne, 2020) typically required tuning existing models on pre-defined properties of interest, with few works attempting a real data-driven adaptation from unlabeled demonstrations (Michel and Neubig, 2018; Wang et al., 2021; Zhang et al., 2022). More recently, several studies employed prompting (Garcia and Firat, 2022; Sarti et al., 2023) or preference optimization from post-editing behavior (Lee et al., 2023; Berger et al., 2024) to render MT personalization more effective and data-efficient. We complement established prompt methodologies with steering approaches to personalize MT outputs using a few user-provided examples.
7.3 Preliminaries
| ZH → EN || 道人道:「既如此,便隨你去來。」 | |
|---|---|
| H\(_1\) | "Such being the case," the Taoist acquiesced, "I am ready to follow you, whenever you please to go." |
| H\(_2\) | "Very good, I will go with you then," said the Taoist. |
| Gemma 2 2B | "If that's the case, then go ahead" said the Taoist. |
| Gemma 2 9B | "If so, then I will go with you" the Taoist said |
| Llama 3.1 8B | The Taoist said: "If you insist on going, then go ahead." |
| IT → EN || Sarà l’effetto dell’acqua del mare. Il mare ne fa di questi scherzi | |
|---|---|
| H\(_1\) | "The salt water must have done it. The sea plays funny tricks." |
| H\(_2\) | "It must have been the effect of sea-water. The sea makes extraordinary changes." |
| Gemma 2 2B | "It will be the effect of the sea water. The sea makes of these jokes." |
| Gemma 2 9B | It will be the effect of the sea water. The sea plays these tricks. |
| Llama 3.1 8B | It will be the effect of the sea water. The sea does things like this. |
Before testing the effectiveness of personalization strategies, we validate some key assumptions: i) Whether the personalized translation style is discernible, i.e., if it is possible to tell apart human- and machine-generated translations; ii) Whether different translation styles are automatically reproducible, i.e., if LLMs can mimic a specific translator’s style when provided with some examples; and iii) Whether style distinctions are reflected in the model’s internal representations, to motivate the interest in steering approaches for personalization.
We use the Par3 dataset by Thai et al. (2022), which contains multiple non-English novels, as a benchmark to evaluate personalization. Novels are segmented into paragraphs with translations into English by two professional literary translators. To ensure a diverse and representative evaluation, we select novels spanning a variety of linguistic families and cultural backgrounds. Our dataset includes Romance languages such as Italian (Pinocchio) and French (Around the World in Eighty Days), as well as Germanic languages like Dutch (The Diary of a Young Girl) and German (Beware of Pity). To evaluate our setup on non-Latin scripts and distinct linguistic structures, we also include Russian (Crime and Punishment), Japanese (No Longer Human), and Chinese (Dream of the Red Chamber). Table 7.2 summarizes the number of paragraphs employed in the evaluation of each language.
| Lang | Novel name | Train | Val | Test | ICL Ex. |
|---|---|---|---|---|---|
| Italian (IT) | Pinocchio | 745 | 82 | 107 | 20 |
| French (FR) | Around the World in Eighty Days | 829 | 92 | 120 | 20 |
| Dutch (NL) | The Diary of a Young Girl | 769 | 85 | 110 | 20 |
| German (DE) | Beware of Pity | 606 | 67 | 96 | 20 |
| Russian (RU) | Crime and Punishment | 1517 | 168 | 224 | 20 |
| Japanese (JA) | No Longer Human | 652 | 40 | 81 | 20 |
| Chinese (ZH) | Dream of the Red Chamber | 694 | 76 | 92 | 20 |
Examples for a subset of languages are shown in Table 7.1. We name the two available human translations H\(_1\) and H\(_2\), and compare them with MT outputs produced by LLMs, which we denote as \(\text{MT}_{\text{model}}\). We use three LLMs, namely Llama 3.1 8B Instruct (Team, 2024b) and Gemma 2 (Team, 2024a) in its 2B and 9B instruction-tuned variants. Our model selection is motivated by our steering requirements, discussed in Section 7.5.
7.3.1 Are Personalized Translations Discernible?
Following prior work on personalization (Wang et al., 2024c; Liu et al., 2023), we train a series of classifiers based on multilingual XLM transformer encoders (Conneau et al., 2020) to distinguish between H\(_1\), H\(_2\), and MT translations. If those systems can reliably separate these three classes, it suggests the presence of reasonably distinct stylistic signals differentiating them. In particular, the ability to distinguish between H\(_1\) and H\(_2\) would denote not only the possibility to discern a human-like style from human-made and automatic translations, but also a personalized style from different human translators.
We train a classifier for each language and each model in our evaluation suite. All classifiers are fine-tuned from the xlm-roberta-large model1, using a linear classification head. Training is conducted for 6 epochs with a learning rate of 2e-5 and a batch size of 32, selecting the best model checkpoint based on validation accuracy. Training data only includes generations from models and the translator without any source text. It is also perfectly balanced, as each paragraph provides one instance for all three labels: H\(_1\), H\(_2\), and MT. The total size of the training set varies depending on the number of paragraphs in the chosen novel. On average, we obtain approximately 830 instances, resulting in a total of around 2,490 labeled examples for training (see Table 7.2). Validation and test sets are strictly held out and never seen during training. Additionally, they do not include the small 20-example subsets used for prompting or steering. Results in Table 7.3 indicate that translation styles are discernible with high accuracy. On average, across all models and languages, the classifiers achieve an accuracy ranging from 77% (Japanese) to 99% (Chinese), with an overall average of 86%. These results suggest that personalization information is abundant in the literary setting and can plausibly be exploited for modeling. These findings corroborate previous results showing the high learnability of this task by machines while remaining intrinsically difficult for human annotators (Youyou et al., 2015; Flekova et al., 2016; Wang et al., 2024b).2
| Lang | Gemma 2 2B | Gemma 2 9B | Llama 3.1 8B |
|---|---|---|---|
| DE | 0.89 | 0.90 | 0.84 |
| RU | 0.92 | 0.90 | 0.91 |
| ZH | 0.99 | 0.98 | 0.98 |
| IT | 0.78 | 0.85 | 0.80 |
| NL | 0.79 | 0.78 | 0.82 |
| FR | 0.88 | 0.87 | 0.90 |
| JA | 0.76 | 0.79 | 0.76 |
7.3.2 Can LLMs Reproduce Human Translation Styles?
To confirm whether MT personalization can be achieved, we test the LLM’s ability to mimic the stylistic choices of a particular translator in a multi-shot (MS) prompting setup. For each translator available across tested novels, we provide the model with 20 in-context examples selected from the original pool of translated paragraphs by that translator, asking it to generate a consistent translation. We compare MS results with the default zero-shot (ZS) prompting, which uses no examples from the translator, to quantify the effect of in-context examples. Table 7.4 presents results for personalization accuracy, automatically evaluated using our high-scoring classifiers from the previous section; and translation quality, estimated via the widely used comet MT metric (Rei et al., 2020). The proportion of outputs categorized as matching the translator’s style is increased two- to four-fold following MS prompting, suggesting that LLMs can employ implicit clues in small sets of user examples to produce personalized translations. Stable scores for comet also confirm that translation quality is maintained during style adaptations.
| Gemma 2 2B | Gemma 2 9B | Llama 3.1 8B | ||||
|---|---|---|---|---|---|---|
| 📊 | ☄️ | 📊 | ☄️ | 📊 | ☄️ | |
| ZS | 0.10 | 0.69 | 0.08 | 0.71 | 0.08 | 0.70 |
| MS | 0.24 | 0.69 | 0.31 | 0.73 | 0.32 | 0.73 |
7.3.3 Finding Personalization Information in LLM Representations
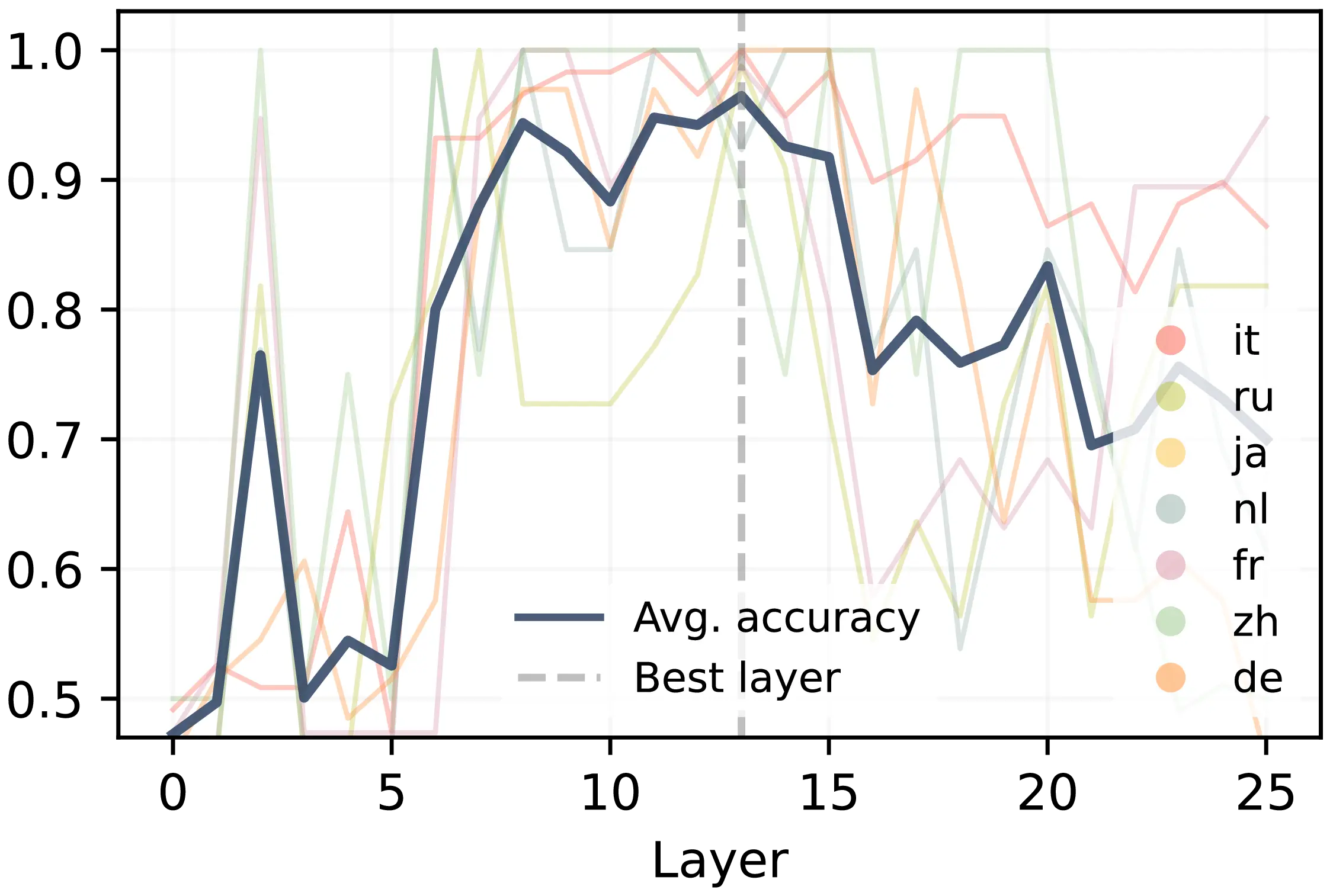
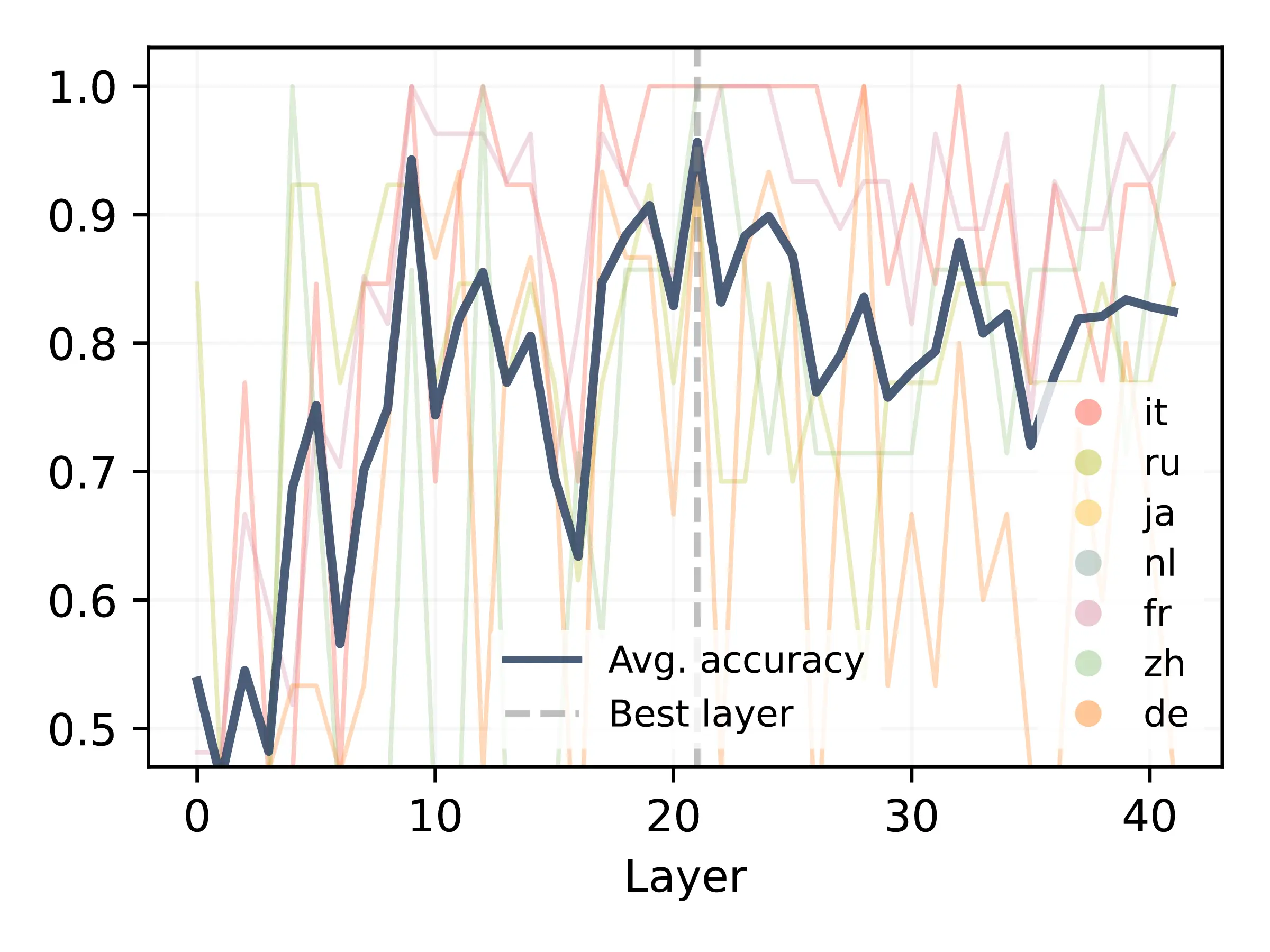
In light of these results, we set out to test how the model encodes information reflecting a stylistic shift when style-appropriate examples are provided. To this purpose, we train linear probes (Belinkov, 2022) using model activations as input features to predict the style label (MT, H\(_1\), or H\(_2\)) that the style classifier (from Section 7.3.1) would assign to the eventual translation, based purely on the prompt’s internal representation. Probing accuracy is measured by testing the model’s ability to predict the classified outcome before generation, using only the prompt representation formed by the model. Given a test set of human-translated paragraphs, we train our probes on a set of examples using an MS prompt with 20 in-context examples. The set is balanced between prompts that showcase personalization with gold in-context examples from a human translator and non-personalized prompts with MT-generated examples previously produced by the same tested model in a ZS setup. Test examples are selected from the respective novels to ensure for the classifier prediction shifts from MT in the ZS setting to the style of in-context examples when MS is used, signaling a causal influence of demonstrations on output personalization.3 This balanced setup prevents the leakage of task information, such as the number of in-context examples, to learned probes, ensuring that stylistic differences between human- and machine-generated in-context examples are the sole factor determining differences in model activations. We focus specifically on Gemma models, extracting activations after the attention block at each model layer for the last token of the prompt, which was previously shown to encode key task-relevant information (Hendel et al., 2023; Todd et al., 2024; Scalena et al., 2024). Figure 7.2 reports probe accuracies across all layers of Gemma 2 2B and 9B. We find a peak in probe accuracy of \(\sim95\%\) around intermediate model layers, suggesting that these layers encode stylistic information with near-perfect precision.4 These results confirm that personalization is discernible from LLMs’ internal representation, motivating our experiments towards the design of inference-time interventions to steer models towards personalized MT outputs.
7.4 Methods
We begin by introducing the prompting and steering methods that we use as baselines and outline our own proposed SAE-based steering approach for personalized translation.
7.4.1 Prompting Baselines
Zero-Shot (ZS) The ZS setup used in our main experiment corresponds to the one from Section 7.3.1, in which the model is simply asked to produce a translation with no conditioning from examples or explanations towards the target translation style. We use this setting to establish a baseline style and translation quality performance for the models.
Zero-Shot Explain (ZS-Exp) Building upon the ZS setting, we experiment with a prompting strategy where LLMs are provided with detailed explanations of the most salient elements that characterize the desired translation style. We obtain such descriptions by prompting a capable proprietary model, GPT-4o (OpenAI, 2023), with 20 translations matching the desired style, asking it to synthesize a set of guidelines to match the examples. We evaluate two contrastive variants of this approach, providing GPT-4o with either MT examples (ZS-Exp\(_\text{HT}\)) or alternative human translations (ZS-Exp\(_\text{PT}\)) alongside examples matching the desired style, and asking to describe what characterizes the latter compared to the former. To avoid data leakage, all generated explanations are manually reviewed to ensure they do not contain any verbatim content or direct excerpts from the input examples.5 Tested models are then prompted with GPT-4o explanations in a ZS setting, to verify whether interpretable directives synthesized from a set of examples matching the desired behavior can produce reliable personalization results.
Multi-Shot (MS) Following Section 7.3.2’s findings, we adopt the same MS setup using 20 in-context translation examples matching the style of a target human translator (H\(_1\) or H\(_2\)).
7.4.2 Steering Baselines
We employ the Activation Addition (ActAdd) and Representation Fine-tuning (ReFT) methods introduced in Section 2.3.2 as baselines for comparing the effectiveness of our proposed method. For ActAdd, we employ the standard contrastive formulation by Rimsky et al. (2024) and Scalena et al. (2024) to extract two sets of style-relevant (\(\{z\}^+\)) and default (\(\{z\}^-\)) activations from a given model layer using 20 in-context examples demonstrating default behavior (MT) and the desired behavior (H\(_1\) or H\(_2\) translations), respectively. We then compute the average \(\Delta\) steering vector between the two sets of activations, scale it by a factor of \(\alpha\) = 2, which was found to be effective by previous research (Scalena et al., 2024), and apply it additively to the same model layer during inference. For ReFT, we apply learned interventions to the same personalization-relevant layers identified in Section 7.3.3 and limit confounding factors by tuning ReFT interventions with the set of 20 examples used for MS prompting.
7.4.3 Contrastive SAE Steering
Given the SAE formulation we present in Section 2.3.2, our primary interest lies in the sparse latents \(h(z_l) \in \mathbb{R}^m\) learned by the SAE encoder, which were empirically found to capture monosemantic and interpretable properties of model inputs.
Contrastive prompt setup Given a set of paragraphs \(\mathcal{D}\) for a novel in the Par3 dataset, each instance in it is a tuple:
\[ \mathcal{D} = \left\{ \left< s, \text{H}_1, \text{H}_2, \text{MT}_{\text{model}} \right> \right\} \]
with s being the non-English source sentence, \(\text{H}_1\) and \(\text{H}_2\) translations from two distinct human translators and \(\text{MT}_{\text{model}}\) the machine translation from the model under evaluation. Similar to previous methods, we employ a contrastive approach to extract SAE latents that are most active in the presence of the desired personalization style, while simultaneously controlling for more generic features that capture the generic properties of the task. We define two sets of contrastive prompts:
\[ \mathcal{D}^+ = \left\{ \left< s, e^{+} \right> \right\}\;\;\text{and}\;\;\mathcal{D}^- = \left\{ \left< s, e^{-} \right> \right\} \]
capturing the personalized style of interest and baseline properties of the task, respectively. Similarly to the ZS-Exp setup from Section 7.4.1, we explore two \(\mathcal{D}^-\) configurations using either \(e^- =\) MT (SAE Cont.\(_\text{HT}\)) or \(e^- =\) H\(_2\) (or H\(_1\), if H\(_2\) is the personalization target; SAE Cont.\(_\text{PT}\)) to assess the effect of baseline choice on steering effectiveness.
Feature extraction First, we gather activations \(z^+_l\) and \(z^-_l\) by prompting the model with inputs from the two contrastive sets \(\mathcal{D}^+\) and \(\mathcal{D}^-\). Activations are extracted at the last prompt token position from its most informative layer, as identified in Section 7.3.3. Activations are then converted into sparse latent representations \(x^+ = h(z^+)\) and \(x^- = h(z^-)\), with \(x^+, x^- \in \mathbb{R}^m\) by the SAE encoder. This procedure is repeated across 20 contrastive examples, resulting in two collections of SAE latent vectors for positive/negative examples:
\[ \begin{aligned} \mathcal{X}^+ &= \left\{x^{+}_1, x^{+}_2, \dots, x^{+}_{20} \right\} \\ \mathcal{X}^- &= \left\{x^{-}_1, x^{-}_2, \dots, x^{-}_{20} \right\} \end{aligned} \]
Relevance-based Feature Selection To identify discriminative features for personalization in the large set of latents, we employ an information-theoretic approach adapted from Zhao et al. (2025). For each of the inputs, we identify the subset of size \(n < m\) that includes only the SAE active features, i.e., the latent dimensions for which the logit is greater than 0. We consider logit values in this subset as instances of a random variable \(X_i \in x\), and calculate the mutual information \(I(X_i, Y)\) between each feature \(X_i\) and the target binary variable \(Y = \{+, -\}\) corresponding to the style of the provided examples (personalized or non-personalized). A higher \(I(X_i, Y)\) indicates that the \(i\)-th feature is more informative for discriminating between personalized and default inputs, and can hence be used for steering. A representative sample of 40 latents showing the highest mutual information scores for both personalized (\(\{X_i\}^+\)) and non-personalized (\(\{X_i\}^-\)) examples is selected using this procedure.6 For every selected latent, we compute its expected logit when personalization is present or absent in provided examples, i.e. \(\mathbb{E}^+[X_i]\) and \(\mathbb{E}^-[X_i]\).
Inference-time intervention Finally, activations are steered by setting selected latents to their expected value whenever their observed score is below (for the promoted personalized case) or above (for the demoted non-personalized case) the pre-computed average. Hence, in the SAE Cont.\(_\text{HT}\) setting we enhance the features relevant to a target personalized style, e.g. \(\{X_i\}^{H_1}\) for H\(_1\), and suppress the features \(\{X_i\}^{MT}\), corresponding to the model’s default MT. In SAE Cont.\(_\text{PT}\), instead, we promote the same H\(_1\)-related latents while suppressing \(\{X_i\}^{H_2}\) to steer the model towards H\(_1\) personal style. Additionally, we modulate the magnitude of the resulting vector with an \(\alpha\) coefficient, which was found to play an essential role in steering effectiveness in previous research (Scalena et al., 2024; Ferrando et al., 2025). Algorithm 1 outlines the procedure for our proposed latent-based steering. It enhances features identified as relevant to personalization while simultaneously suppressing those negatively correlated with the task.
7.5 Experiments
7.5.1 Setup
Model selection We evaluate our methods on the same three models used for our preliminary evaluation of Section 7.3. Our selection is guided by the availability of open-source pre-trained SAEs, which can be computationally expensive to train otherwise. For Gemma models, we employ SAEs from the GemmaScope suite (Lieberum et al., 2024); for the Llama 3.1 model, we employ the SAE released by McGrath et al. (2024). GemmaScope SAEs are available for every model layer, enabling us to steer Gemma models on their most informative layers for the task, which we identified in Section 7.3.3. On the contrary, a single SAE for the 19th layer is available for Llama, hence limiting our evaluation of SAE steering and potentially producing sub-optimal steering results for that model.
Metrics We evaluate our approaches on a held-out test set sourced from the Par3 dataset for personalization and output quality. For personalization, we use the classifiers described in Section 7.3.1. We define three submetrics employing the classifier probability distribution over the three classes (MT, H\(_1\), H\(_2\)) to better analyze different aspects of classifiers’ predictions. First, we compute H accuracy as the classifier’s total probability assigned to human-like translations, \(p(\)H\(_1\)\() + p(\)H\(_2\)\()\), thereby measuring the generic human-like style of the text. To measure personalization, we employ the personalization P, corresponding only to the human translation currently selected as target (H\(_1\) or H\(_2\)). Finally, the more stringent P\(_\text{flip}\) metric measures the proportion of examples for which the applied conditioning procedure (either prompting or steering) causally influences the resulting classifier prediction, identifying examples for which the label flips from MT to the desired target.
To ensure that our interventions do not result in a degradation of overall translation quality, we also employ comet7 (Rei et al., 2020) using the personalized translation as reference.
| Source/Method | Translation | 📊 Classifier | ☄️ COMET |
|---|---|---|---|
| Source (FR) | Cette somme vous sera restituée à votre sortie de prison, dit le juge. En attendant, vous êtes libres sous caution. | ||
| H1 | This sum of money will be returned to you when you leave prison,' said the judge. 'In the meantime you are free on bail. | - | - |
| ZS | This amount will be returned to you upon your release from prison, the judge said. Meanwhile, you are free on bail. | MT | 0.79 |
| SAE Cont.\(_\text{HT}\) (\(\alpha\)=5) | This sum will be repaid to you at your departure from prison, the judge declared. In the meantime, you are released under bond. | MT | 0.85 |
| SAE Cont.\(_\text{HT}\) (\(\alpha\)=50) | #echo all ought to goodness too was put moreover goodness behaving goodness goodness goodness goodness [...] | H1 | 0.20 |
| SAE Cont.\(_\text{HT}\) (\(\alpha\)=150) | GURL callers goodness_Noneummy amid'ala Reportedaps Beaverishlor Decompiled_unset queer headquarters Headquarters twe ... [...] | H1 | 0.23 |
| Source (DE) | Nein – was Sie lieber haben, Herr Leutnant! Nur keine Zeremonien, es ist doch ganz einerlei. | ||
| H2 | "No, no-whatever you would rather have, Lieutenant Hofmiller! Please don't stand on ceremony, it makes no difference to us." | - | - |
| ZS | No, whatever you prefer, Lieutenant! Just no ceremonies, it doesn't matter. | MT | 0.76 |
| SAE Cont.\(_\text{HT}\) (\(\alpha\)=5) | No, anything at all you want, sir! Just don't make a fuss about it, it really doesn't matter. | H2 | 0.79 |
| SAE Cont.\(_\text{HT}\) (\(\alpha\)=50) | ">I Don't worry about that... I don't want a ceremony for this one. It's not important... | [H2]{color=‘brand-color.lightbluedim’] | 0.46 |
| SAE Cont.\(_\text{HT}\) (\(\alpha\)=150) | IWhenInWhatItDonIf Sometimes AIs Celebrating cerimonies... Sosir please don't have parties ey' [...] | H2 | 0.24 |
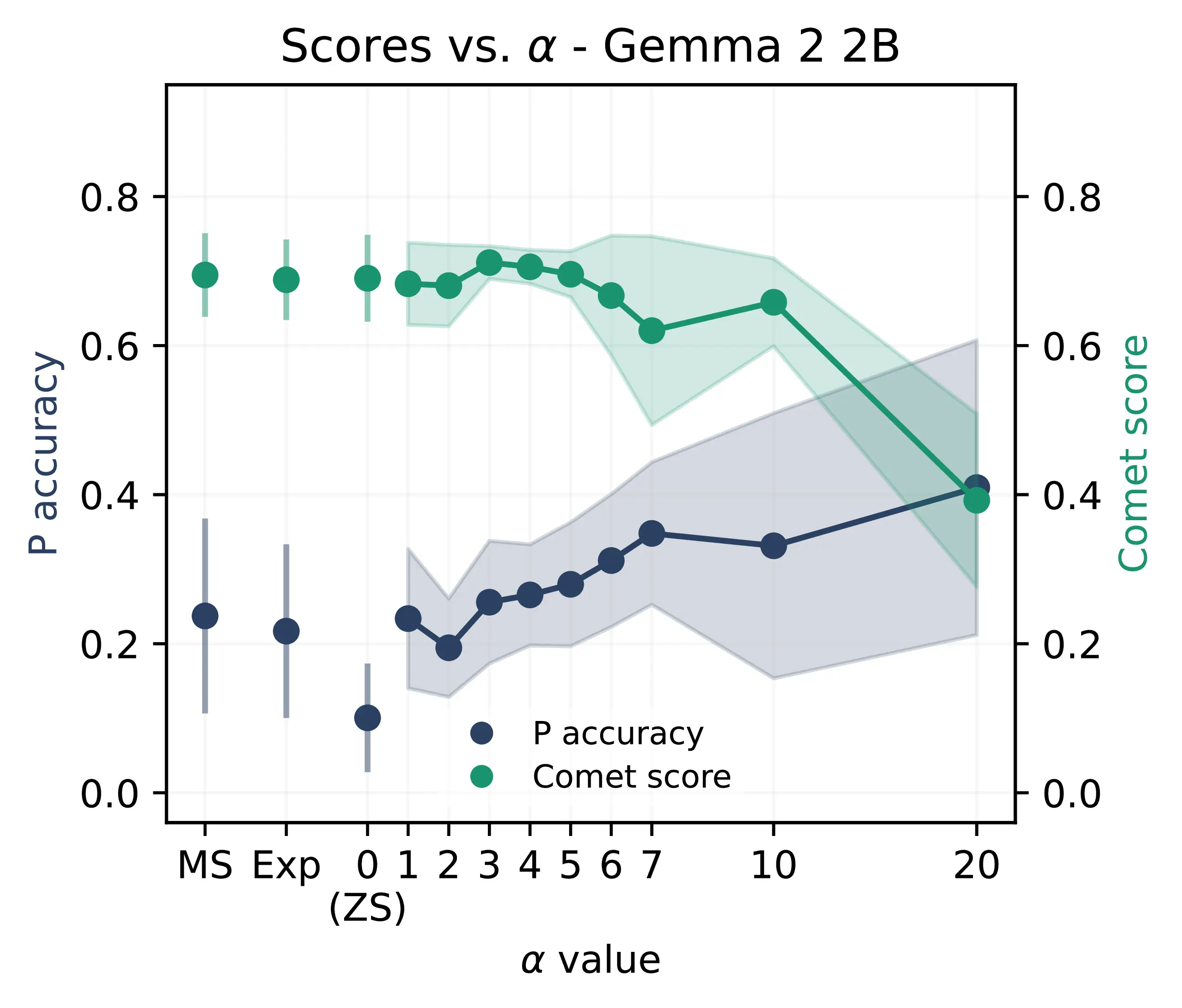
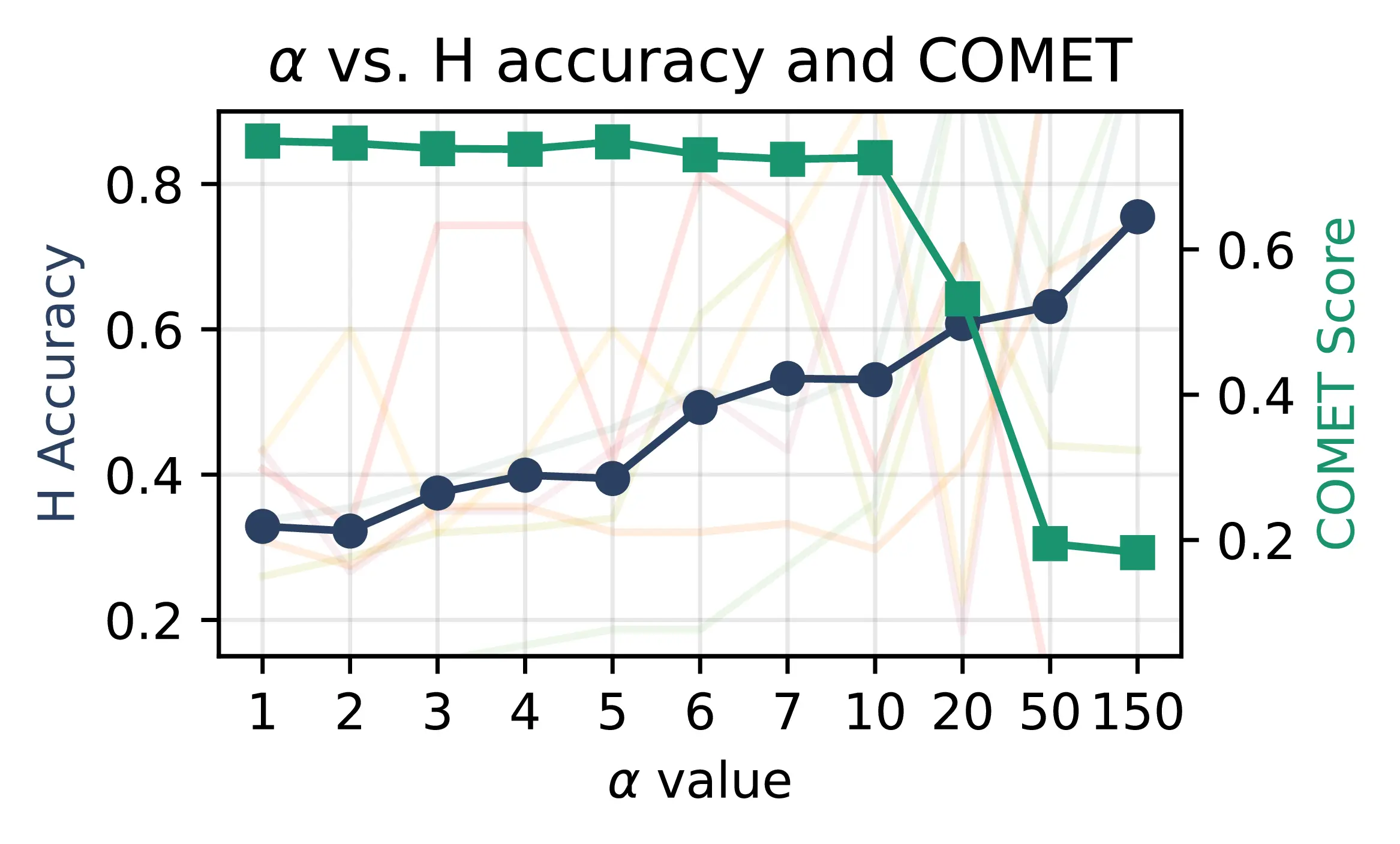
Quality-accuracy trade-off We begin by verifying the optimal steering intensity \(\alpha\) for our SAE steering technique. We primarily focus on results from Gemma 2 2B, for which we ran a comprehensive sweep over all relevant hyperparameters.8 Figure 7.3 illustrates the influence of \(\alpha\) on MT personalization accuracy and fluency averaged across all translators for all tested languages. For values of \(\alpha \leq 3\), performance remains close to that of the MS baseline, indicating that the contrastive method is effectively isolating latents associated with human-like style. As \(\alpha\) increases, performance generally exceeds the MS approach, achieving greater control and flexibility in guiding the model’s output with minimal impact on translation quality. However, for \(\alpha \geq 10\), we observe a notable degradation in comet, suggesting an important drop in translation fluency. Table 7.5 shows some examples of models generating output aligned with the Human translator according to the classifier, but with a low comet score corresponding to an almost unreadable output due to extreme \(\alpha\) values. False positive classifications in such settings suggest that steering methods and classifiers are aligned with potentially spurious stylistic features, which are not necessarily indicative of high-quality translations. We leave the investigation of these spurious features to future work, focusing here on the trade-off between personalization and translation quality.
Following Ferrando et al. (2025), which also employ SAEs for steering, we experiment with very high alpha values (up to 150), finding the classifier’s H accuracy approaching 100% for some languages. While this indicates that the contrastive steering is aggressively optimizing toward classifier preferences (Figure 7.4), the consequent drop in comet scores reveals a steep decline in translation quality, often resulting in incoherent or nonsensical generations from a human perspective. Ultimately, we identify \(\alpha\) = 5 as an appropriate steering intensity to balance personalization and fluency, and employ it for our main evaluation.
7.5.2 Results and Discussion
Table 7.6 presents performances of tested models across prompting and steering setups, averaged across all languages and personalization targets (H\(_1\) and H\(_2\) for each language). We find that our SAE Cont.\(_\text{HT}\) and SAE Cont.\(_\text{PT}\) methods generally achieve the best trade-off between personalization accuracy and translation quality, especially for the smaller Gemma 2 2B model. This could be due to the larger models’ superior ability to incorporate in-context information naturally, reducing the relative benefit of explicit steering. Comparing the two contrastive setups (HT and PT) for the ZS-Exp and SAE Cont. methods, we find that using different human demonstrations as a contrastive baseline in PT generally produces better results for larger models. As for general performance, we conjecture this could be due to the larger models’ improved ability to disentangle personalization-critical factors without explicit guidance. For the smaller Gemma 2 2B, the difference between the two approaches is minimal, suggesting that the model cannot fully exploit the differences between the examples.
| Gemma 2 2B | Gemma 2 9B | Llama 3.1 8B | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| H | P | Pflip | ☄️ | H | P | Pflip | ☄️ | H | P | Pflip | ☄️ | |
| ZS | 0.21 | 0.10 | 0.05 | 0.69 | 0.15 | 0.08 | 0.04 | 0.71 | 0.24 | 0.08 | 0.05 | 0.70 |
| ZS-Exp.HT | 0.30 | 0.22 | 0.16 | 0.68 | 0.41 | 0.22 | 0.18 | 0.72 | 0.56 | 0.23 | 0.21 | 0.69 |
| ZS-Exp.PT | -- | 0.20 | 0.14 | 0.69 | -- | 0.23 | 0.19 | 0.73 | -- | 0.30 | 0.26 | 0.70 |
| MS | 0.37 | 0.24 | 0.16 | 0.69 | 0.48 | 0.31 | 0.27 | 0.73 | 0.58 | 0.32 | 0.28 | 0.73 |
| ActAdd | 0.27 | 0.22 | 0.12 | 0.67 | 0.32 | 0.24 | 0.20 | 0.70 | 0.55 | 0.36 | 0.28 | 0.70 |
| ReFT | 0.31 | 0.22 | 0.18 | 0.70 | 0.46 | 0.34 | 0.27 | 0.67 | 0.53 | 0.38 | 0.26 | 0.70 |
| SAE Cont.HT | 0.39 | 0.27 | 0.19 | 0.70 | 0.46 | 0.33 | 0.29 | 0.72 | 0.59 | 0.31 | 0.27 | 0.72 |
| SAE Cont.PT | -- | 0.27 | 0.18 | 0.69 | -- | 0.35 | 0.29 | 0.73 | -- | 0.33 | 0.28 | 0.72 |
Do SAE Steering and MS Prompting Impact Activations in a Similar Way? Since SAE-based approaches perform on par or better than MS, we set out to investigate whether the two methods result in a similar impact on model representations. We collect the modified activations \(z_{\text{steer}}\) obtained from the SAE Cont.\(_\text{HT}\) steering setting and evaluate them using the probing classifier trained on MS-conditioned activations, as introduced in Section 7.3.3, for detecting personalization information. Table 7.7 shows probe accuracy in detecting the positive impact of SAE steering across the three possible outcomes of the steering procedure. We find that the probe trained on the SAE layer effectively distinguishes between activations corresponding to successful and unsuccessful SAE steering, despite having been exposed only to MS conditioning during training. This includes both instances where the classifier prediction is flipped after steering (MT \(\to\) H) and settings where the conditioning fails (MT \(\to\) MT). In settings where the original output already matches human style (H \(\to\) H*), the probe obtains lower accuracy with broader confidence intervals, denoting higher uncertainty. These findings suggest that the SAE’s latents we extract through our contrastive method are meaningfully connected to the stylistic patterns embedded in the multi-shot examples, providing evidence that our intervention influences the internal representations of the model, aligning them to the natural effect of the MS approach.
| MT → H* | MT → MT | H* → H* | |
|---|---|---|---|
| Gemma 2 2B | 0.94 ±0.01 | 0.07 ±0.02 | 0.72 ±0.15 |
| Gemma 2 9B | 0.93 ±0.02 | 0.12 ±0.10 | 0.68 ±0.19 |
7.6 Limitations
While we demonstrates the potential of steering LLMs for MT personalization using sparse autoencoders, we acknowledge several limitations.
Firstly, the generalizability of our findings is constrained by the scope of our experiments. We focused on literary translation from seven specific source languages into English and evaluated three LLMs of relatively small size. Consequently, the observed effectiveness of SAE-based steering and the identified optimal layers for intervention may not directly transfer to other language pairs, significantly different model architectures or sizes, or distinct domains beyond literary texts. Further research is needed to assess the robustness of our approach across a broader range of linguistic and modeling contexts.
Secondly, the computational overhead associated with sparse autoencoders presents a practical challenge. Although we utilized pre-trained SAEs in our study, the initial training of these components is resource-intensive. This could limit the accessibility and scalability of our proposed method, particularly for researchers or practitioners with limited computational resources or when frequent retraining for new models or tasks is required. The current availability of pre-trained SAEs also restricts model choice, as seen with the Llama 3.1 8B model, where an SAE was only available for a potentially sub-optimal layer.
Finally, our investigation primarily focused on downstream performance and the impact of various personalization strategies on model representations. However, we did not pursue a mechanistic understanding of the “personalization circuits” within the LLMs. Future work could adopt a more fine-grained mechanistic interpretability approach to study how specific SAE latents or combinations thereof encode and manipulate nuanced stylistic features, thereby providing deeper insights into the underlying processes of LLM personalization.
7.7 Conclusion
We conducted a broad evaluation of various prompting and steering approaches for personalizing LLM-generated translations. Our evaluation targets a practical, real-world application of literary translation and addresses the underexplored challenge of steering LLM generations in a linguistically rich and stylistically sensitive domain. Through comprehensive evaluation across multiple languages, novels, and models, we demonstrate that our proposed SAE-based approach outperforms prompting and alternative steering techniques.
Although faithfully replicating individual human translation styles remains a highly challenging task, our approach achieves strong alignment with human translation quality, as reflected in both general human-likeness and translator-specific personalization metrics. These results highlight the method’s robustness and its potential to support high-fidelity translation workflows in real-world settings. Concretely, these results have important implications in the development of personalized MT systems based on LLMs. In particular, the notable effectiveness of our proposed approach on smaller models might enable MT customization when few examples are available, facilitating further research on how personalization information is encoded and produced by language models. Despite their effectiveness, the interpretability of the learned SAE latents and their potential use with larger LLMs—where increased capacity may further enhance the precision and fluency of personalized translations—remain open questions for future investigation.
The success of SAE-based steering for personalized translation highlights the effectiveness of internals-based interventions for controlling model generation. However, the practical deployment of such approaches requires a careful evaluation of their impact on users’ trust and behaviors. The first two parts of this thesis focused on developing methods for analyzing and steering model generation. The third and final part, beginning with the next chapter, focuses instead on the users of machine translation systems, specifically professional post-editors and translators, to explore how their interactions with machine-translated content are shaped by factors such as language similarity and translation quality. Finally, we investigate whether these interactions can be improved using the trove of information available from the inner workings of MT models.
Two human annotators were asked to label 100 translated paragraphs from the novel Pinocchio (IT\(\rightarrow\)EN) as either human or MT, resulting in an accuracy of \(\sim60\%\).↩︎
Examples are resampled for every test paragraph to prevent the probe from overfitting on spurious prompt features.↩︎
We find probes for layers 13 and 21 to perform best for the 2B and 9B models, respectively.↩︎
Details on the prompt templates are in Section B.2.1.4.↩︎
By contrast, traditional SAE-based steering methods only employ features associated with the positive class (Chalnev et al., 2024; Arditi et al., 2024).↩︎
Larger models were evaluated using a subset of the best-performing configurations. Details in Section B.2.2.↩︎