8 Machine Translation Post-editing for Typologically Diverse Languages
Language was just difference. A thousand different ways of seeing, of moving through the world. No, a thousand worlds within one. And translation, a necessary endeavor however futile, to move between them.
– Rebecca F. Kuang, Babel (2022)
8.1 Introduction
Recent advances in neural language modeling and multilingual training have led to the widespread adoption of machine translation (MT) technologies across an unprecedented range of languages worldwide. While the benefits of state-of-the-art MT for cross-lingual information access are undisputed (Gene, 2021), its usefulness as an aid to professional translators varies considerably across domains, subjects and language combinations (Zouhar et al., 2021). In the last decade, the MT community has been including an increasing number of languages in its automatic and human evaluation efforts (Bojar et al., 2013; Barrault et al., 2021). However, the results of these evaluations are typically not directly comparable across different language pairs for several reasons. First, reference-based automatic quality metrics are hardly comparable across different target languages (Bugliarello et al., 2020). Second, human judgments are collected independently for different language pairs, making their cross-lingual comparison vulnerable to confounding factors such as tested domains and training data sizes. Similarly, recent work on NMT post-editing efficiency has focused on specific language pairs such as English-Czech (Zouhar et al., 2021), German-Italian, German-French (Läubli et al., 2019) and English-Hindi (Ahsan et al., 2021). However, a controlled comparison across a set of typologically diverse languages is still lacking.
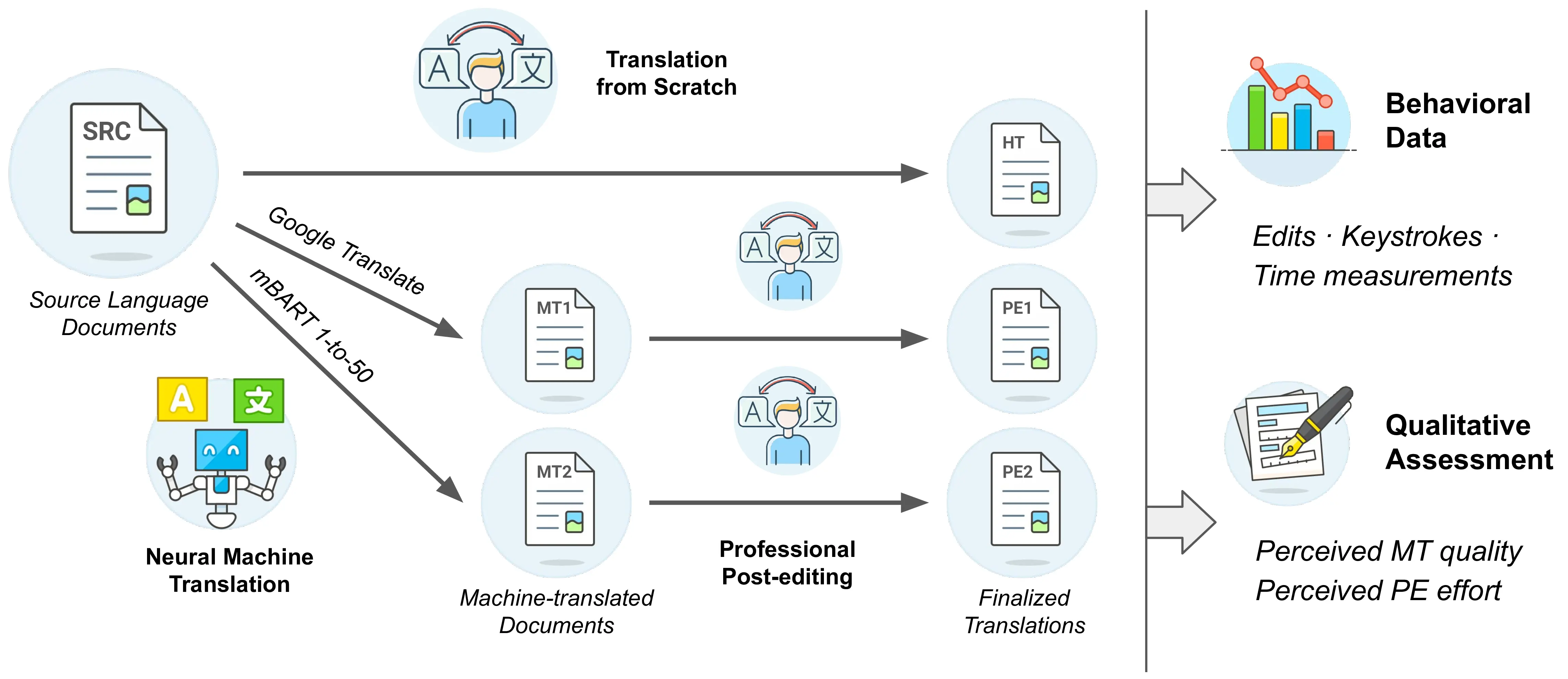
In this chapter, we conduct an initial assessment of the usefulness of state-of-the-art NMT in professional translation with a strictly controlled cross-language setup (Figure 8.1). Specifically, professionals were asked to translate the same English documents into six typologically distinct languages—Arabic, Dutch, Italian, Turkish, Ukrainian, and Vietnamese—using the same platform and guidelines. Three translation modalities were adopted: human translation from scratch (HT), post-editing of Google Translate’s translation (PE\(_1\)), and post-editing of mBART-50’s translation (PE\(_2\)), the latter being a state-of-the-art open-source, multilingual NMT system. In addition to post-editing results, subjects’ fine-grained editing behavior, including keystrokes and time information, was logged to measure productivity and effort across languages, systems and translation modalities. Finally, translators were asked to complete a qualitative assessment regarding their perceptions of MT quality and post-editing effort. The resulting DivEMT dataset, to our best knowledge, is the first public resource that allows a direct comparison of professional translators’ productivity and fine-grained editing information across a set of typologically diverse languages. All collected data are publicly released1 alongside this paper to foster further research in the language- and system-dependent nature of NMT advances in real-world translation scenarios.
8.3 The DivEMT Dataset
DivEMT’s primary purpose is to assess the usefulness of state-of-the-art NMT for professional translators and to study how this usefulness varies across target languages with different typological properties. We present below our data collection setup, which strikes a balance between simulating a realistic professional translation workflow and maximizing the comparability of results across languages.
8.3.1 Subjects and Task Scheduling
To control for the effect of individual translators’ preferences and styles, we involve a total of 18 subjects (three per target language). During the experiment, each subject receives a series of short documents (3 to 5 sentences each) where the source text is presented in isolation (HT) or alongside a translation proposal produced by one of the NMT systems (PE\(_1\), PE\(_2\)). The experiment comprises two phases: during the warm-up phase a set of 5 documents is translated by all subjects following the same, randomly sampled sequence of modalities (HT, PE\(_1\) or PE\(_2\)). This phase allows the subjects to become accustomed to the setup and enables us to identify potential issues in the logged behavioral data before proceeding.2 In the main collection phase, each subject is asked to translate documents in a pseudo-random sequence of modalities. This time, however, the sequence is different for each translator and chosen so that each document gets translated in all three modalities. This allows us to measure translation productivity independently from the subject’s productivity and document-specific difficulties.
Table 8.1 shows an example of the adopted modality scheduling. The modality of document docM\(_i\) for translator T\(_j\) in the main task is picked randomly among the two modalities that were not seen by the same translator for docM\(_{i-1}\), enforcing consecutive documents given to the same translator to be assigned different modalities to avoid periodicity in repetition and enable same-language comparisons. Importantly, although all three modes were collected for every document, we did not enforce mode consistency across the same translator identifier across languages (i.e. T\(_1\) for Italian does not have the same sequence of modalities of translator T\(_1\) in Arabic, for example). For this reason, individual subjects are not directly comparable across languages. This is relevant since comparable editing behavior should be attributed to similar personal preferences rather than an identical modality assignment of the same sentences. Despite modality scheduling, we have no guarantees that translators consistently follow the order of documents presented in PET, and thus possibly operate on documents assigned to the same modality consecutively. However, this possibility reduces to random guessing due to a lack of any identifying information related to the modality until the document is entered for editing. The sequence of modalities for the warmup task is fixed and is: HT, PE\(_2\), PE\(_1\), HT, PE\(_2\).
| T\(_1\) | T\(_2\) | T\(_3\) | ||
|---|---|---|---|---|
| warm-up | docW\(_1\) | HT | HT | HT |
| docW\(_2\) | PE\(_1\) | PE\(_1\) | PE\(_1\) | |
| ... | ||||
| docW\(_N\) | PE\(_2\) | PE\(_2\) | PE\(_2\) | |
| main | docM\(_1\) | HT | PE\(_1\) | PE\(_2\) |
| docM\(_2\) | PE\(_2\) | HT | PE\(_1\) | |
| docM\(_3\) | HT | PE\(_2\) | PE\(_1\) | |
| ... | ||||
| docM\(_N\) | PE\(_2\) | PE\(_1\) | HT |
As productivity and other behavioral metrics can only be estimated with a sizable sample, we prioritize the number of documents over the number of subjects per language during budget allocation. In future analyses, a larger set of post-edited documents would also provide more insight into the error type distribution of NMT systems across different language pairs.
All subjects are professional translators with at least 3 years of professional experience, including at least 1 year of post-editing experience, and strong proficiency in CAT tools.3 Translators were provided with links to the source articles to facilitate contextualization, were asked to produce translations of publishable quality and were instructed not to use any external MT engine to produce their translations. Assessing the final quality of the post-edited material is out of the scope of the current study, although we realize that this is an important consideration to assess usability in a professional context.4
8.3.2 Choice of Source Texts
The selected documents represent a subset of the FLORES-101 benchmark (Goyal et al., 2022) consisting of sentences taken from English Wikipedia, and covering a mix of topics and domains.5 While professional translators generally specialize in one or a few domains, we opt for a mixed-domain dataset to minimize domain adaptation efforts by the subjects and maximize the generalizability of our results. Importantly, FLORES-101 includes high-quality human translations into 101 languages, which enables the automatic estimation of NMT quality and the discarding of excessively low-scoring models or language pairs before our experiment. FLORES-101 also provides valuable metadata, e.g. source URL, which allows us to ensure the absence of public translations of the selected contents, which could be leveraged by translators and compromise the validity of our setup. The documents used for our study are fragments of contiguous sentences extracted from Wikipedia articles that compose the original FLORES-101 corpus. Even if small, the context provided by document structure allows us to simulate a more realistic translation workflow if compared to out-of-context sentences.
Based on our available budget, we selected 112 English documents from the devtest portion of FLORES-101, corresponding to 450 sentences and 9,626 words. More details on the data selection process are provided in Section C.1.3.
| Genus:Family | d\(_{syn}\) | Morphology | MSP | TTR | Script | |
|---|---|---|---|---|---|---|
| Eng | Indo-European:Germanic | -- | Fusional | 1.17 | 0.28 | latin |
| Ara | Afro-Asiatic:Semitic | 0.57 | Introflexive | 1.67 | 0.46 | arabic |
| Nld | Indo-European:Germanic | 0.49 | Fusional | 1.16 | 0.28 | latin |
| Ita | Indo-European:Romance | 0.51 | Fusional | 1.30 | 0.30 | latin |
| Tur | Altaic:Turkic | 0.70 | Agglutinative | 2.28 | 0.50 | latin |
| Ukr | Indo-European:Slavic | 0.51 | Fusional | 1.42 | 0.47 | cyrillic |
| Vie | Austro-Asiatic:VietMuong | 0.57 | Isolating | 1.00 | 0.12 | latin |
8.3.3 Choice of Languages
Training data is one of the most important factors in determining the quality of an NMT system. Unfortunately, using strictly comparable or multi-parallel datasets, such as Europarl (Koehn, 2005) or the Bible corpus (Mayer and Cysouw, 2014), would dramatically restrict the diversity of languages available to our study or imply prohibitively low translation quality on general-domain text. In order to minimize the effect of training data disparity while maximizing language diversity, we choose representatives of six different language families for which comparable amounts of training data are available in our open-source model, namely Arabic, Dutch, Italian, Turkish, Ukrainian, and Vietnamese. As shown in Table 8.2, our language sample exhibits a good diversity in terms of language family, relatedness to English, type of morphological system, morphological complexity, measured by the mean size of paradigm (MSP, Xanthos et al., 2011), and script. We also report the type-token ratio (TTR), the only language property found to correlate significantly with translation difficulty in a sample of European languages (Bugliarello et al., 2020). While the amount of language-specific parallel sentence pairs used for the multilingual fine-tuning of mBART-50 varies widely (4K \(< N <\) 45M), all our selected language pairs fall within the 100K-250K range (mid-resourced, see Table 8.3), enabling a fair cross-lingual performance comparison.
| Google Translate (PE\(_1\)) | mBART-50 (PE\(_2\)) | # Pairs | |
|---|---|---|---|
| Ara | 34.1 / 65.6 / .737 | 17.0 / 48.5 / .452 | 226K |
| Nld | 29.1 / 60.0 / .667 | 22.6 / 53.9 / .532 | 226K |
| Ita | 32.8 / 61.4 / .781 | 24.4 / 54.7 / .648 | 233K |
| Tur | 35.0 / 65.5 / 1.00 | 18.8 / 52.7 / .755 | 204K |
| Ukr | 31.1 / 59.8 / .758 | 21.9 / 50.7 / .587 | 104K |
| Vie | 45.1 / 61.9 / .724 | 34.7 / 54.0 / .608 | 127K |
8.3.4 Choice of MT Systems
While most of the best-performing general-domain NMT systems are commercial, experiments based on such systems are not replicable, as their backends are silently updated over time. Moreover, without knowing the exact training specifics, we cannot attribute differences in the cross-lingual results to intrinsic language properties. We balance these observations by including two NMT systems in our study: Google Translate (GTrans)6 as a representative of commercial quality, and mBART-50 one-to-Many7 (Tang et al., 2021) as a representative of state-of-the-art open-source multilingual NMT technology. The original multilingual BART model (Liu et al., 2020) is an encoder-decoder transformer model pre-trained on monolingual documents in 25 languages. Tang et al. (2021) extend mBART by further pre-training on 25 new languages and performing multilingual translation fine-tuning for the full set of 50 languages, producing three configurations of multilingual NMT models: many-to-one, one-to-many, and many-to-many. Our choice of mBART-50 is primarily motivated by its manageable size, good performance across the set of evaluated languages (see Table 8.3), and its adoption for other NMT studies (Liu et al., 2021) and post-editing evaluations (Fomicheva et al., 2022). Although mBART-50 performances are usually comparable or slightly worse than those of tested bilingual NMT models,8 using a multilingual model allows us to evaluate the downstream effectiveness of a single, unified system trained on pairs evenly distributed across tested languages. Finally, adopting two systems with marked differences in automatic evaluation scores allows us to estimate how a significant increase in metrics such as BLEU, ChrF and comet (Papineni et al., 2002; Popović, 2015; Rei et al., 2020) impacts downstream productivity across languages in a realistic post-editing scenario.
8.3.5 Translation Platform and Collected Data
Translators were asked to use PET (Aziz et al., 2012), a computer-assisted translation tool that supports both translating from scratch and post-editing. This tool was chosen because (i) it logs information about the post-editing process, which we use to assess effort (see Section 8.4); and (ii) it is a mature research-oriented tool that has been successfully used in several previous studies (Koponen et al., 2012; Toral et al., 2018), and we modify it slightly to support right-to-left languages like Arabic. Using PET, we collect three types of data:
- Resulting translations produced by translators in either HT or PE modes, constituting a multilingual corpus with one source text and 18 translations (one per language-modality combination) exemplified in Table 8.4.
- Behavioral data for translated sentences, including editing time, amount and type of keystrokes (content, navigation, erase, etc.), and number and duration of pauses above 300/1000 milliseconds (Lacruz et al., 2014).
- Pre- and post-task questionnaire. The former focuses on demographics, education, and work experience with translation and post-editing. The latter elicits subjective assessments of post-editing quality, effort and enjoyability compared to translating from scratch.
| Eng | Src | Inland waterways can be a good theme to base a holiday around. |
| Ara | HT | يمكن أن تكون الممرات المائية الداخلية خياراً جيداً لتخطيط عطلة حولها |
| MT | يمكن أن تكون السكك الحديدية الداخلية موضوعًا جيدًا لإقامة عطلة حول | |
| PE | قدتكونالممراتالمائيةالداخليةمكانًاجيدًالقضاءعطلةحولها | |
| Nld | HT | Binnenlandse waterwegen kunnen een goed thema zijn voor een vakantie. |
| MT | Binnenwaterwegen kunnen een goed thema zijn om een vakantie rond te zetten. | |
| PE | Binnenwaterwegen kunnen een goed thema zijn om een vakantie rond te organiseren. | |
| Ita | HT | I corsi d'acqua dell'entroterra possono essere un ottimo punto di partenza da cui organizzare una vacanza. |
| MT | I corsi d’acqua interni possono essere un buon tema per fondare una vacanza. | |
| PE | I corsi d’acqua interni possono essere un buon tema su cui basare una vacanza. | |
| Tur | HT | İç bölgelerdeki su yolları, tatil planı için iyi bir tema olabilir. |
| MT | İç suyolları, tatil için uygun bir tema olabilir. | |
| PE | İç sular tatil için uygun bir tema olabilir. | |
| Ukr | HT | Можна спланувати вихідні, взявши за основу подорож внутрішніми водними шляхами. |
| MT | Водні шляхи можуть бути хорошим об ’єктом для базування відпочинку навколо. | |
| PE | Місцевість навколо внутрішніх водних шляхів може бути гарним вибором для організації відпочинку. | |
| Vie | HT | Du lịch trên sông có thể là một lựa chọn phù hợp cho kỳ nghỉ. |
| MT | Các tuyến nước nội địa có thể là một chủ đề tốt để xây dựng một kì nghỉ. | |
| PE | Du lịch bằng đường thủy nội địa là một ý tưởng nghỉ dưỡng không tồi. |
8.4 Post-Editing Effort Across Languages
In this section, we use the DivEMT dataset to quantify the post-editing effort of professional translators across our diverse set of target languages. We consider two main objective indicators of editing effort: temporal measurements (and related productivity gains) and post-editing rates, measured by the Human-targeted Translation Edit Rate (HTER, Snover et al. (2006)). Finally, we assess the subjective perception of PE gains by examining the post-task questionnaires. We reiterate that all scores in this section are computed on the same set of source sentences for all languages, resulting in a faithful cross-lingual comparison of post-editing effort thanks to DivEMT’s controlled setup.
8.4.1 Temporal Effort and Productivity Gains
We begin by comparing task time (seconds per processed source word) across languages and modalities. For this purpose, edit times are computed for every document in every language without considering the presence of multiple translators for every language. As shown in Figure 8.2, translation time varies considerably across languages even when no MT system is involved (HT), suggesting an intrinsic variability in translation complexity for different subjects and language pairs. Indeed, for the HT modality, the time required for the “slowest” target languages (Italian, Ukrainian) is roughly twice that of the “fastest” one (Turkish). This pattern cannot be easily explained and contrasts with factors commonly tied to MT complexity, such as source-target morphological richness and language relatedness (Birch et al., 2008; Belinkov et al., 2017). On the other hand, we find that the relation PE\(_1\) < PE\(_2\) < HT (where PE\(_1\) is the fastest, PE\(_2\) has a medium speed, and HT is the slowest) holds for all the evaluated languages.
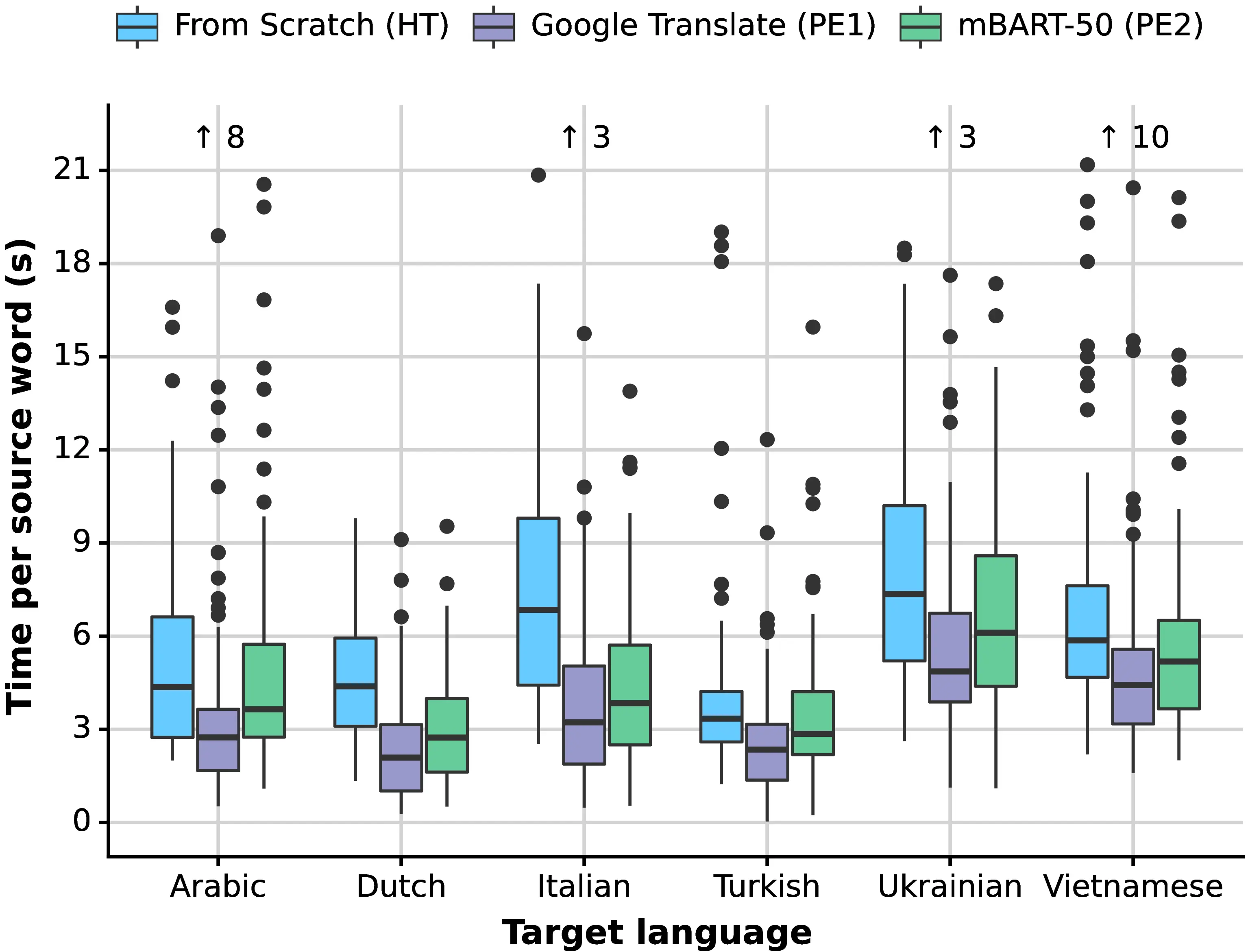
For a measure of productivity gains that is easier to interpret and more in line with translation industry practices, we turn to productivity expressed in source words processed per minute and compute the speed-up induced by the two post-editing modalities over translating from scratch (\(\Delta\)HT). Table 8.5 presents our results. Across systems, we find that large differences among automatic MT quality metrics indeed reflect post-editing effort, suggesting a nuanced picture that complements the findings of Zouhar et al. (2021). While post-editing time gains were observed to quickly saturate for slight changes in high-quality MT, we find that moving from medium-quality to high-quality MT yields meaningful productivity improvements across most evaluated languages. Across languages, too, the magnitude of productivity gains ranges widely, from doubling in some languages (Dutch PE\(_1\), Italian PE\(_1\) and PE\(_2\)) to only about 10% (Arabic, Turkish and Ukrainian PE\(_2\)). When only considering the better-performing system (PE\(_1\)), post-editing remains clearly beneficial in all languages despite the high variability in \(\Delta\)HT scores. Results are more nuanced for the open-source system (PE\(_2\)), with three out of six languages displaying only marginal gains (<15% in Arabic, Turkish and Ukrainian). Despite its overall inferior performance, mBART-50 (PE\(_2\)) is the only system that enables a fair comparison across languages (in terms of training data size and architecture, see Section 8.3.4). Interestingly, when focusing on the productivity gains achieved by this system, factors such as language relatedness and morphological complexity become relevant. Specifically, Italian (+95%), Dutch (+61%) and Ukrainian (+14%) are genetically and syntactically related to English, but Ukrainian has a richer morphology (see Table 8.2). On the other hand, Vietnamese (+23%), Turkish (+12%) and Arabic (+10%) all belong to different families. However, Vietnamese is isolating (little to no morphology), while Turkish and Arabic have rich morphological systems (respectively agglutinative and introflexive, the latter of which is especially problematic for subword segmentation, Amrhein and Sennrich (2021)). Other differences, however, are more difficult to explain. For instance, Dutch is closely related to English and has a simpler morphology than Italian, but its productivity gain with mBART-50 is lower (61% vs 95%). This finding is accompanied by an important gap in BLEU and comet scores achieved by mBART-50 on the two languages (22.6 vs 24.4 BLEU and 0.532 vs 0.648 comet for Dutch vs Italian, resp.), which cannot be explained by training data size.
| Prod \(\uparrow\) | \(\Delta\)HT \(\uparrow\) | ||||
|---|---|---|---|---|---|
| HT | PE\(_1\) | PE\(_2\) | PE\(_1\) | PE\(_2\) | |
| Ara | 13.1 | 21.7 | 16.3 | +84% | +10% |
| Nld | 13.6 | 28.7 | 21.7 | +119% | +61% |
| Ita | 8.8 | 18.6 | 15.6 | +96% | +95% |
| Tur | 17.9 | 25.5 | 21.0 | +34% | +12% |
| Ukr | 8.0 | 12.3 | 9.8 | +71% | +14% |
| Vie | 10.2 | 13.0 | 11.1 | +32% | +23% |
In summary, our findings confirm the overall positive impact of NMT post-editing on translation productivity observed in previous PE studies. However, we note that the magnitude of this impact is highly variable across systems and languages, with inter-subject variability also playing an important role, in line with previous studies (Koponen et al., 2020) (see Section 8.5 for more details). The small size of our language sample does not allow us to draw direct causal links between specific typological properties and post-editing efficiency. That said, we believe these results have important implications for the claimed `universality’ of current state-of-the-art MT and NLP systems, primarily based on the transformer architecture (Vaswani et al., 2017) and BPE-style subword segmentation techniques (Sennrich et al., 2016).
8.4.1.1 Modeling Temporal Effort
Given the high variability among translators, segments and translation modalities, we assess the validity of our observations via statistical analysis of temporal effort using a linear mixed-effects regression model (LMER, Lindstrom and Bates (1988)), following Green et al. (2013) and Toral et al. (2018). Linear Mixed Effects models (LMER) are used for regression analyses involving dependent data, such as longitudinal studies with multiple observations per subject. We fit our model on \(n=7434\) instances, corresponding to 413 sentences translated by 18 translators, using translation time as the dependent variable, and translation modality, target language, their interaction and length of source segment in characters as fixed predictors:
edit_time ~ src_len_chr + lang_id * task_type +
(1|subject_id) +
(1 | document_id/item_id) +
(0 + task_type | document_id/item_id)We log-transform the dependent variable, edit time in seconds, given its long right tail. The models are built by adding one element at a time and checking whether such an addition leads to a significantly better model, as indicated by a reduction in AIC (i.e., a decrease of at least 2). Our random effects structure includes random intercepts for different segments (nested with documents) and translators, as well as a random slope for modality over individual segments. We start with an initial model that includes only the two random intercepts (by-translator and by-segment) and proceed by (i) finding significance for nested document/segment random effect; (ii) adding fixed predictors one by one; (iii) adding interactions between fixed predictors; and (iv) adding the random slopes.[^8-8]
Table 8.6 presents the set of predictors included in the final model, along with an estimate of their impact on edit times and their corresponding significance. We find that both PE modalities significantly reduce translation times (\(p < 0.001\)), with PE\(_1\) being significantly faster than PE\(_2\) (\(p < 0.001\)) across all languages. Considering Ukrainian—the language for which HT is slowest—as the reference level, the reduction in time brought by Google is significantly more pronounced for Italian, Dutch (\(p<0.001\)), and Turkish (\(p<0.05\)). For mBART-50, however, we only observe significantly more pronounced increases in productivity for Italian and Dutch (\(p<0.001\)) compared to the reference. We find these results to corroborate the observations of the previous section.
| Predictor | Estim. | p-value | Sig. |
|---|---|---|---|
(intercept) |
4.92 | 1.12e-11 | *** |
source length |
0.38 | < 2e-16 | *** |
lang_ara |
-0.49 | 0.1209 | |
lang_ita |
-0.14 | 0.6407 | |
lang_nld |
-0.58 | 0.0733 | x |
lang_tur |
-0.82 | 0.0162 | * |
lang_vie |
-0.24 | 0.4254 | |
task_pe1 |
-0.49 | < 2e-16 | *** |
task_pe2 |
-0.22 | 1.77e-07 | *** |
lang_ara:task_pe1 |
-0.11 | 0.0505 | x |
lang_ita:task_pe1 |
-0.40 | 8.97e-12 | *** |
lang_nld:task_pe1 |
-0.41 | 5.74e-12 | *** |
lang_tur:task_pe1 |
-0.14 | 0.0194 | * |
lang_vie:task_pe1 |
0.13 | 0.0290 | * |
lang_ara:task_pe2 |
0.05 | 0.3535 | |
lang_ita:task_pe2 |
-0.39 | 3.30e-11 | *** |
lang_nld:task_pe2 |
-0.29 | 4.46e-07 | *** |
lang_tur:task_pe2 |
0.03 | 0.5811 | |
lang_vie:task_pe2 |
0.04 | 0.5289 |
lang and task are Ukrainian and Translation from scratch (HT), respectively. Estimate impact on edit time for every predictor is provided in log seconds. Significance: *** = < 0.001, * = < 0.05, x = < 0.1
8.4.2 Post-Editing Rate
We proceed to study the post-editing patterns using the widely adopted Human-targeted Translation Edit Rate (HTER, Snover et al. (2006)), which is computed as the length-normalized sum of word-level substitutions, insertions, deletions, and shift operations performed during post-editing.
As shown in Figure 8.3, PE\(_1\) required less editing than PE\(_2\) for all languages, and a high variability is observed across the two systems and all languages. Because translators were not informed about the presence of two MT systems, we exclude the possibility that these results reflect an over-reliance or distrust towards a specific MT system. For Google Translate, Ukrainian shows the heaviest edit rate, followed by Vietnamese, whereas Arabic, Dutch, Italian and Turkish all show relatively low amounts of edits. Focusing again on mBART-50 for a more fair cross-lingual comparison, Ukrainian is by far the most heavily edited language, followed by a medium-tier group composed of Vietnamese, Arabic and Turkish, and finally by Dutch and Italian as low-edit languages. Results show that several of our observations on linguistic relatedness and morphology type also apply to edit rates, with languages less related to English or having richer morphology requiring more post-edits on average.
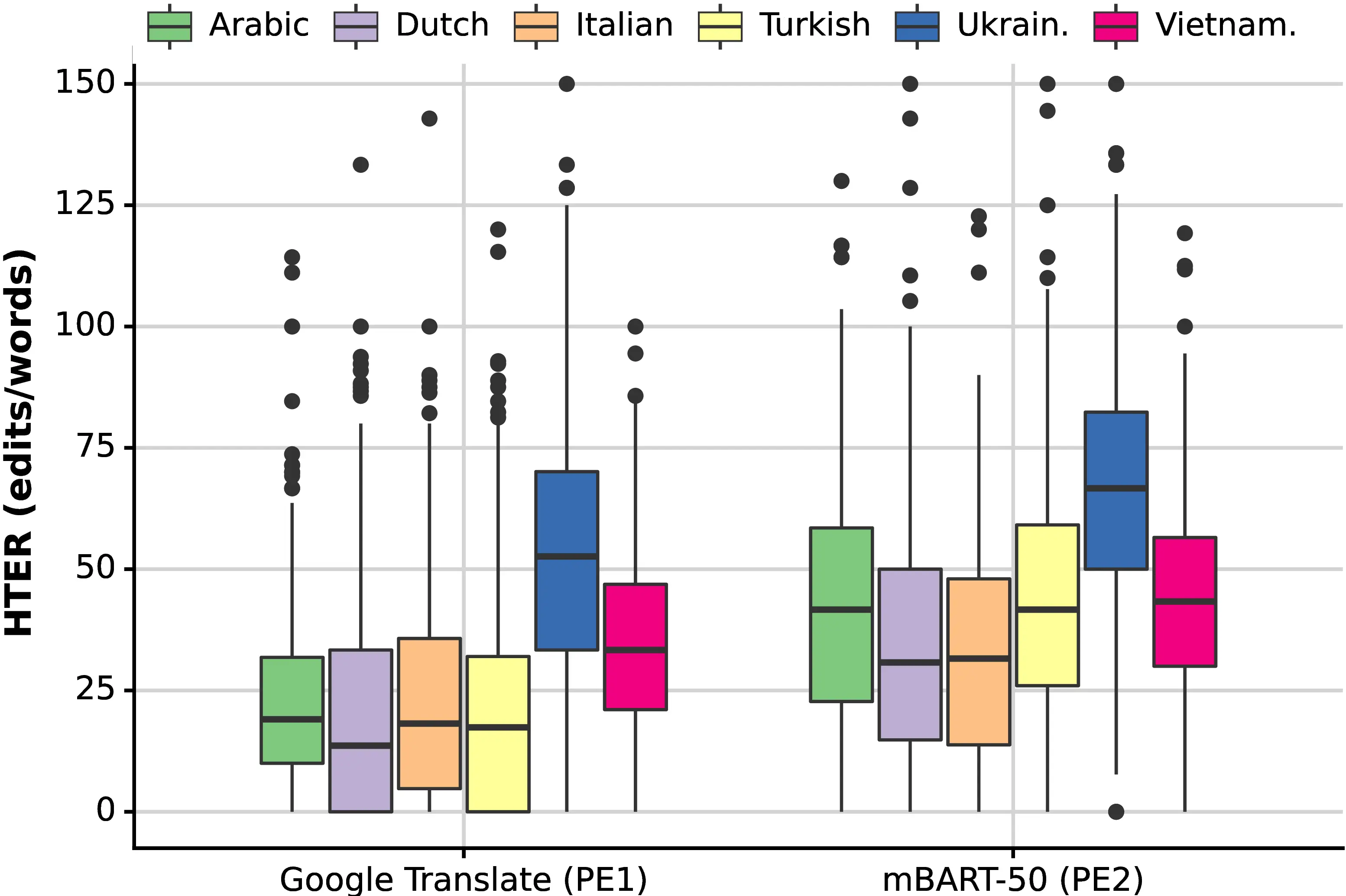
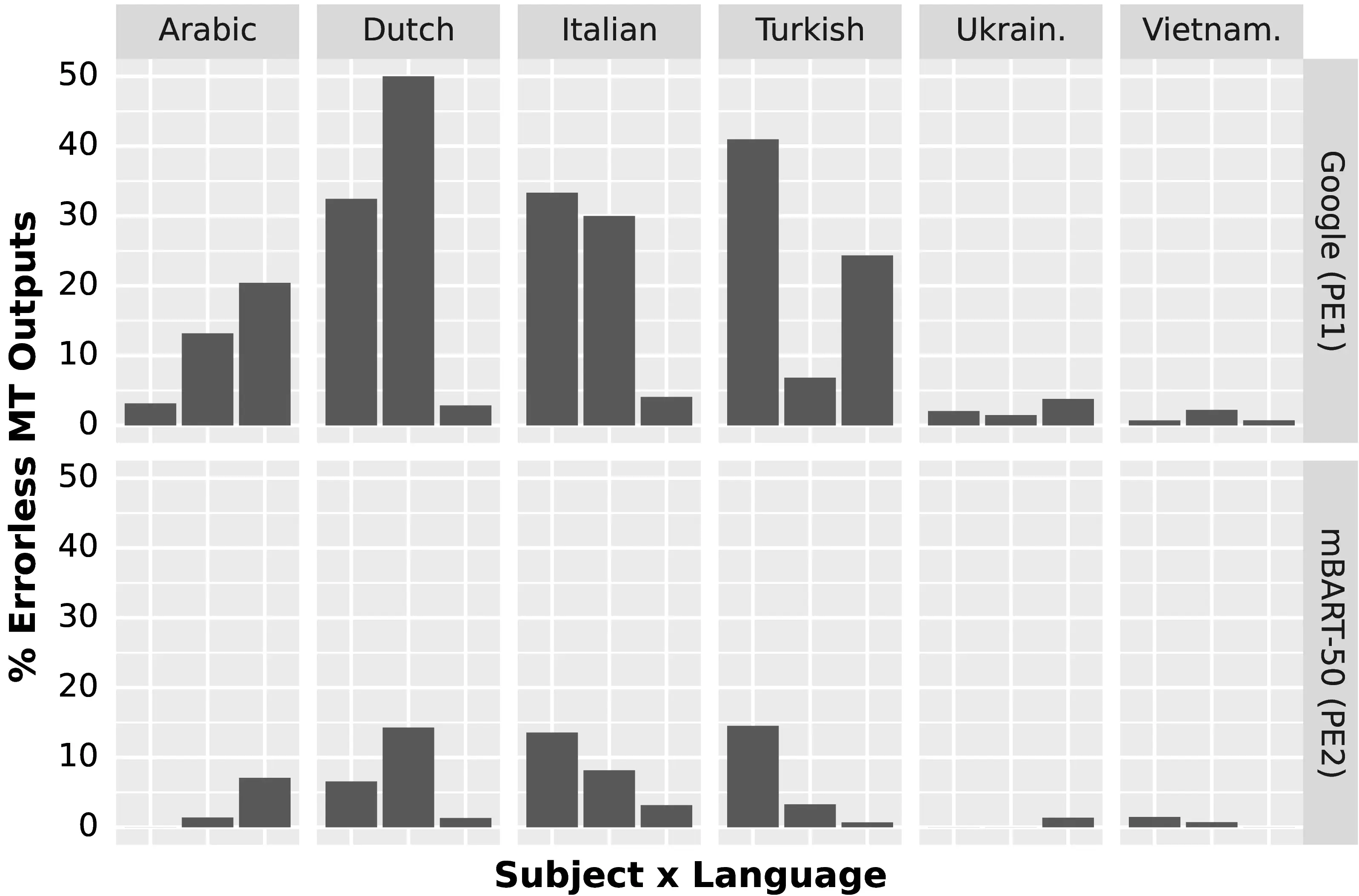
Figure 8.4 visualizes the large gap in edit rates across languages and subjects by presenting the amount of ‘errorless’ MT sentences that were accepted directly, i.e. without any post-editing. We note again how the NMT system significantly influences the rate of occurrence of such sentences, yet nonetheless shows that Dutch and Italian generally present more error-free sentences than Ukrainian and Vietnamese. In particular, for Google Translate outputs, the average rate of error-free sentences is roughly 25% for the former target languages, while for the latter, it accounts for only 3% of total translations. Surprisingly, the English-Turkish pair also fares well, despite the low relatedness between the source and target languages. We note that post-editing effort appears to correlate poorly with the automatic MT quality metrics reported in Table 8.3 (e.g., see the high scores of Vietnamese and the low scores of Dutch PE\(_1\)), highlighting a difficulty in predicting the benefits of MT post-editing over HT for new language pairs.
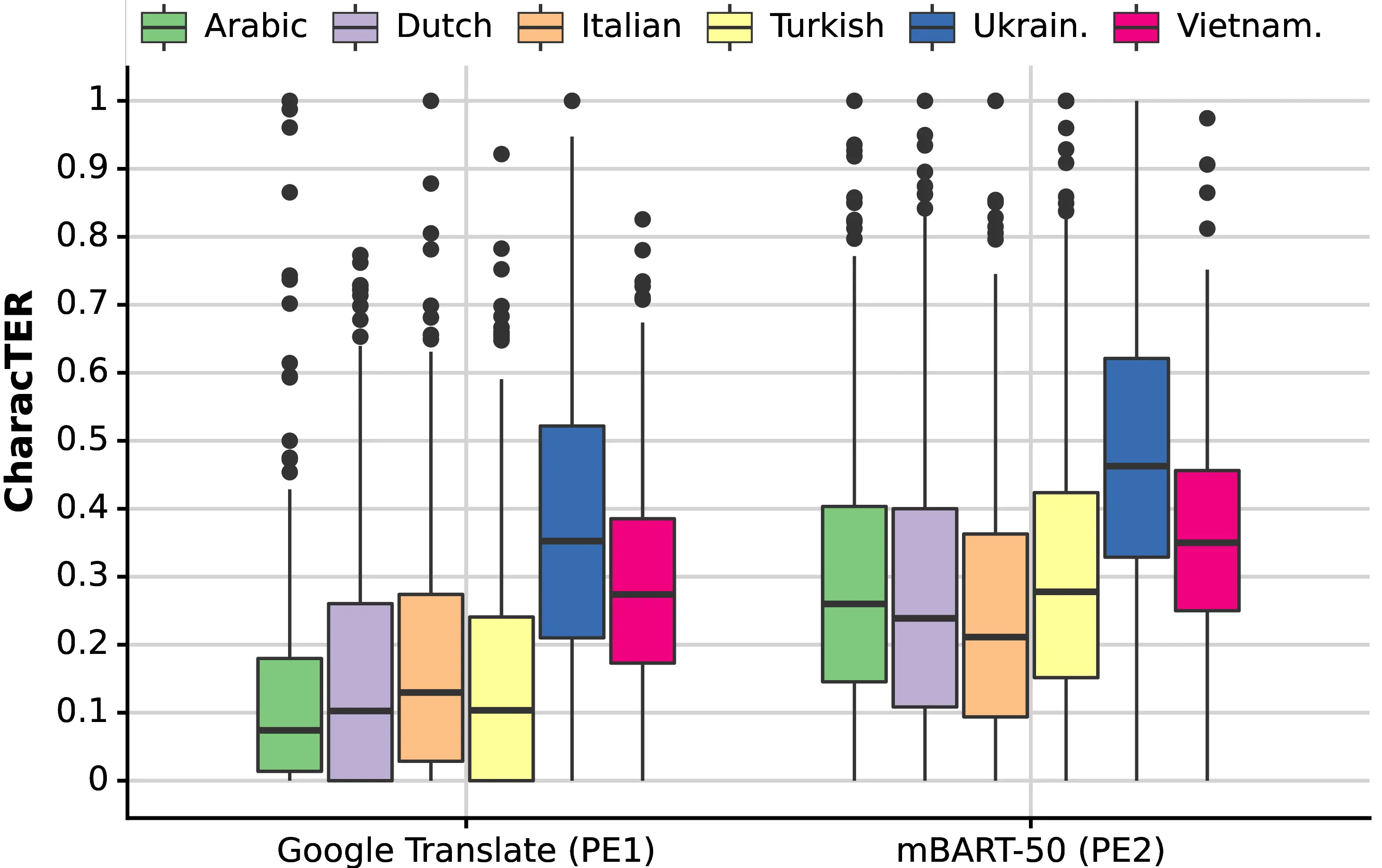
While HTER is a standard metric adopted in both academic and industrial settings, we also evaluated its character-level variant, CharacTER (Wang et al., 2016), to assess whether it could better account for the editing process of morphologically rich languages. Figure 8.5 presents the CharacTER results. When comparing this plot to the HTER one (Figure 8.3), we notice that CharacTER preserves the overall trends but slightly improves the edit rate for Arabic and Turkish compared to other languages. Nevertheless, we find that HTER correlates slightly better with productivity scores across all tested languages, both at the sentence and document levels.
8.4.3 Perception of Productivity Gain
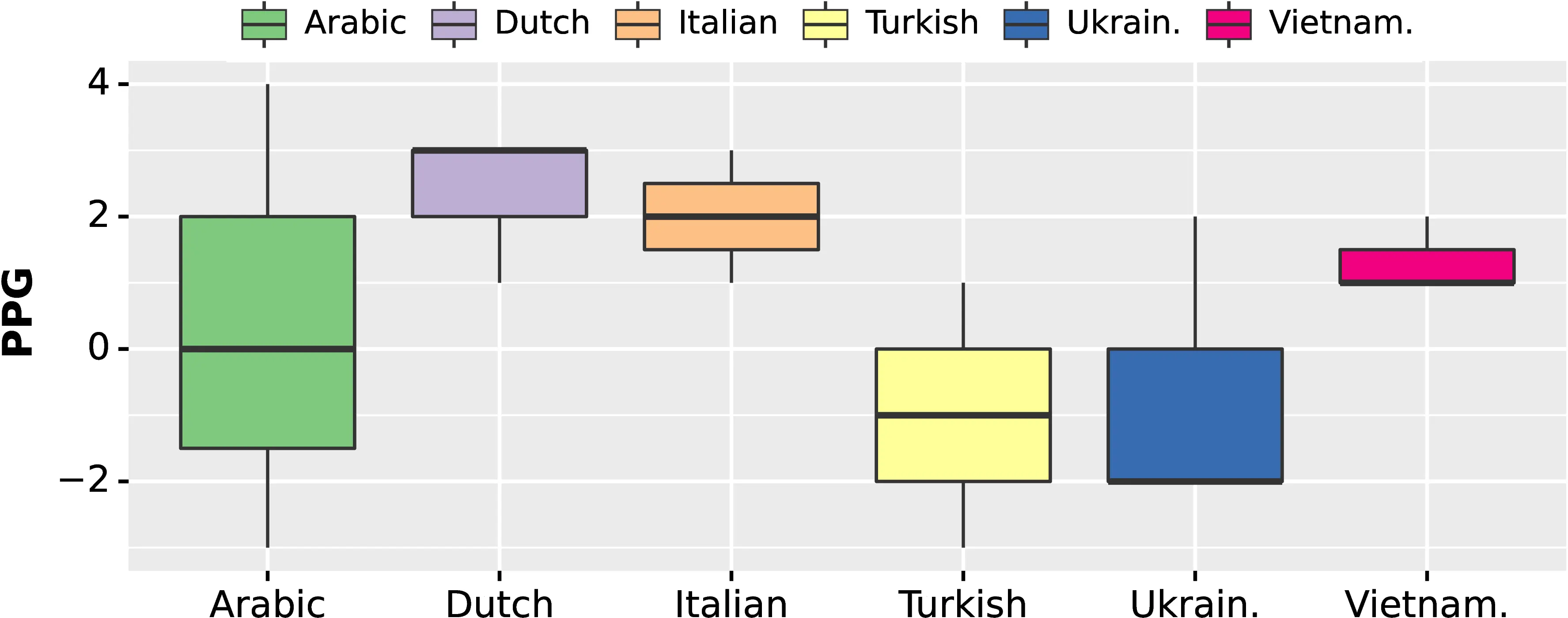
We conclude our analysis by examining the post-task questionnaires, in which participants expressed their perceptions of MT quality and translation speed across HT and PE modalities (HT\(_s\), PE\(_s\))9 using a 1-7 Likert scale (where 1 is the slowest and 7 is the fastest). We use these to compute the Perceived Productivity Gain (PPG) as \(\textrm{PPG} = \textrm{PE}_s - \textrm{HT}_s\) and visualize it in Figure 8.6. We observe that Italian and Dutch, the only target languages with marked productivity gains (\(\Delta\)HT) regardless of the PE system in Table 8.5, are also the only ones having consistently high (\(\geq 2\)) PPG scores across all subjects. Moreover, we remark how PPG for target languages with a wide gap in \(\Delta\)HT scores between high-PE\(_1\) and low-PE\(_2\) (Arabic, Ukrainian) are hardly distinguishable from those of languages in which \(\Delta\)HT is low for both PE systems (Turkish, Vietnamese). Notably, 4 out of 18 subjects attribute negative PPGs to the PE modality, despite productivity gains being reported across all subjects and languages. These results suggest that worst-case usage scenarios may play an important role in driving PPG, i.e. that subjects’ perception of quality is shaped mainly by particularly challenging or unsatisfying interactions with the NMT system, rather than the average case. Finally, from the post-task questionnaire, PPG scores exhibit a strong positive correlation with the perception of MT adequacy (\(\rho\)=0.66), fluency (\(\rho\)=0.46) and overall quality (\(\rho\)=0.69), and more generally with a higher enjoyability of PE (\(\rho\)=0.60), while being inversely correlated with the perception of problematic mistranslations (\(\rho\)=-0.60).
8.5 Limitations
The subjective component introduced by the presence of multiple translators is an important confounding factor in our setup, particularly given the relatively small number of subjects for each language. In our study, we aimed to strike a balance between thorough control of other noise components and faithful reproduction of a realistic translation scenario. However, we recognize that the combination of the limited document context provided by FLORES-101, the variety of topics covered in the texts, and the experimental nature of the PET platform constitutes an atypical setting that may have impacted the translators’ natural productivity. Moreover, variability in the content of mBART-50 fine-tuning data, despite their comparable sizes, may have played a role in the observed variability in automatic MT evaluation and PE gains across languages.
8.6 Conclusions
We introduced DivEMT, the outcome of a post-editing study that spanned two state-of-the-art NMT systems, involved 18 professional translators, and employed six typologically diverse target languages under a unified setup. We leveraged DivEMT’s behavioral data to perform a controlled cross-language analysis of NMT post-editing effort along its temporal and editing effort dimensions. The analysis reveals that NMT drives significant improvements in productivity across all evaluated languages; however, the magnitude of these improvements depends heavily on the language and the underlying NMT system. In this setting, productivity measurements across modalities were found to be generally consistent with the recorded editing patterns. Our results indicate that translators working on language pairs with significant post-editing productivity gains, on average, perform fewer edits and accept more machine-generated translations without any editing. We have also observed a disconnect between post-editing productivity gains and MT quality metrics collected for the same NMT systems. Finally, low source-language relatedness and target morphological complexity seem to hinder productivity when NMT is adopted, even in settings where system architecture and training data are controlled for.
In our qualitative analysis, translators’ perception of post-editing usefulness was found to be strongly shaped by problematic mistranslations. Languages showing large productivity gains for both NMT systems were the only ones associated with a positive perception of PE-mediated gains, as opposed to mixed or negative opinions for other translation directions.
Overall, our findings reveal significant variation in post-editing effectiveness across languages and systems, highlighting the need for fine-grained quality assessment tools. In the next chapter, we build upon these insights by conducting a second study with professional post-editors, assessing the impact of word-level error detection methods—including unsupervised approaches that leverage model internals—on the quality and productivity of human post-editing.
Warm-up data are excluded from the analysis of Section 8.4.↩︎
Additional subjects’ details are available in Section C.1.1.↩︎
A summary of our translation guidelines is provided in Section C.1.2.↩︎
We use a balanced sample of articles sourced from WikiNews, WikiVoyage and WikiBooks.↩︎
Evaluation performed in October 2021.↩︎
See Section C.1.4 for automatic MT quality results by five different models over a larger set of 10 target languages.↩︎
We reemphasize that subjects were unaware of the presence of two distinct MT systems.↩︎