5 Answer Attribution for Trustworthy Retrieval-Augmented Generation
“What makes the desert beautiful,” said the little prince, “is that it hides a well somewhere…”
– Antoine de Saint-Exupéry, Le petit prince (1943)
5.1 Introduction
Retrieval-augmented generation with large language models has become the de facto standard methodology for question answering in both academic (Lewis et al., 2020; Izacard et al., 2023) and industrial settings (Dao and Le, 2023; Ma et al., 2024). This approach is effective in mitigating hallucinations and producing factually accurate answers (Petroni et al., 2020; Lewis et al., 2020; Borgeaud et al., 2022; Ren et al., 2025). However, verifying whether the model answer is faithfully supported by the retrieved sources is often non-trivial due to the large context size and the variety of potentially correct answers (Krishna et al., 2021; Xu et al., 2023).
In light of this issue, several answer attribution1 approaches were recently proposed to ensure the trustworthiness of RAG outputs (Rashkin et al., 2023; Bohnet et al., 2022; Muller et al., 2023). Initial efforts in this area employed models trained on Natural Language Inference (NLI) to automate the identification of supporting documents (Bohnet et al., 2022; Yue et al., 2023). However, being based on an external validator, this approach does not faithfully explain the answer generation process but simply identifies plausible sources supporting model answers in a post-hoc fashion. Following recent progress in the instruction-following abilities of LLMs, self-citation (i.e. prompting LLMs to generate inline citations alongside their answers) has been proposed to mitigate the training and inference costs of external validator modules (Gao et al., 2023a). However, self-citation performance is hindered by the imperfect instruction-following capacity of modern LLMs (Mu et al., 2023; Liu et al., 2023), and resulting attributions are still predicted in an unintelligible, post-hoc fashion. This is an important limitation for these approaches, since the primary goal of answer attribution should be to ensure that the LLM is not ‘right for the wrong reasons’ (McCoy et al., 2019).
In light of these considerations, we introduce Mirage, an extension of the context-reliance evaluation PECoRe framework from the previous chapter for efficient and faithful answer attributions. Mirage first identifies context-sensitive tokens in a generated sentence by measuring the shift in LM predictive distribution caused by the added input context. Then, it attributes this shift to specific influential tokens in the context using gradient-based saliency or other input attribution techniques (Madsen et al., 2022). Finally, attributions can be aggregated at the document level to match context-dependent generated sentences with retrieved documents that contribute to their prediction. The resulting pairs can then be converted to citations using the standard answer attribution (AA) format.
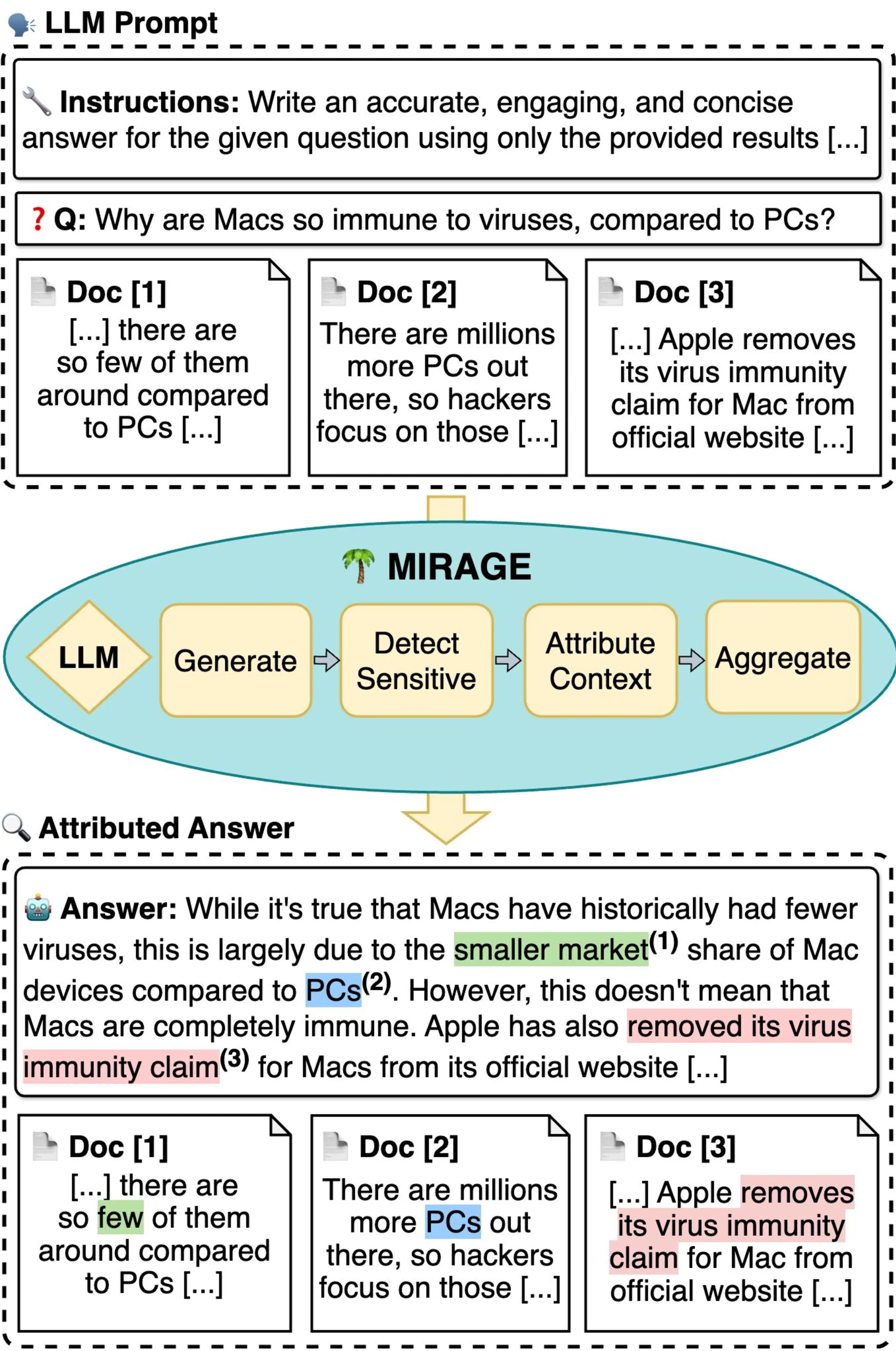
We begin our assessment of Mirage on the short-form XOR-AttriQA dataset (Muller et al., 2023), showing high agreement between Mirage results and human annotations across several languages. We then test our method on the open-ended ELI5 dataset (Fan et al., 2019), achieving AA quality comparable to or better than self-citation while ensuring a higher degree of control over attribution parameters. In summary, we make the following contributions:2
We introduce Mirage, a model internals-based answer attribution framework optimized for RAG applications.
We quantify the plausibility of Mirage attributions on two datasets, showing improvements over NLI and self-citation methods while ensuring better controllability and efficiency.
We analyze challenging attribution settings, highlighting Mirage‘s faithfulness to LLMs’ reasoning process.
5.2 Background and Related Work
In RAG settings, a set of documents relevant to a user query is retrieved from an external dataset and infilled into an LLM prompt to improve the generation process (Petroni et al., 2020; Lewis et al., 2020). Answer attribution (Rashkin et al., 2023; Bohnet et al., 2022; Muller et al., 2023) aims to identify which retrieved documents support the generated answer (answer faithfulness, Gao et al., 2023b), e.g., by exploiting the similarity between model outputs and references.3 Simplifying access to relevant sources via answer attribution is a fundamental step towards ensuring RAG trustworthiness in customer-facing scenarios (Liu et al., 2023).
5.2.1 Answer Attribution Methods
Entailment-based Answer Attribution Bohnet et al. (2022) and Muller et al. (2023) propose to approximate human AA annotations with NLI systems such as TRUE (Honovich et al., 2022), using a source document as premise and an LLM-generated sentence as entailment hypothesis. AAs produced by these systems were shown to correlate strongly with human annotations, prompting their adoption in AA studies (Muller et al., 2023; Gao et al., 2023a). Despite their effectiveness, entailment-based methods can be computationally expensive when several answer sentence-document pairs are present. Moreover, this setup assumes the NLI model’s ability to robustly detect entailment relations across all domains and languages for which the LLM generator is used. In practice, however, NLI systems were shown to be brittle in challenging scenarios, exploiting shallow heuristics (McCoy et al., 2019; Nie et al., 2020; Sinha et al., 2021; Luo et al., 2022), and require dedicated efforts for less-resourced settings (Conneau et al., 2018). For example, NLI may fail to correctly attribute answers in multi-hop QA settings when considering individual documents as premises (Yang et al., 2018; Welbl et al., 2018).
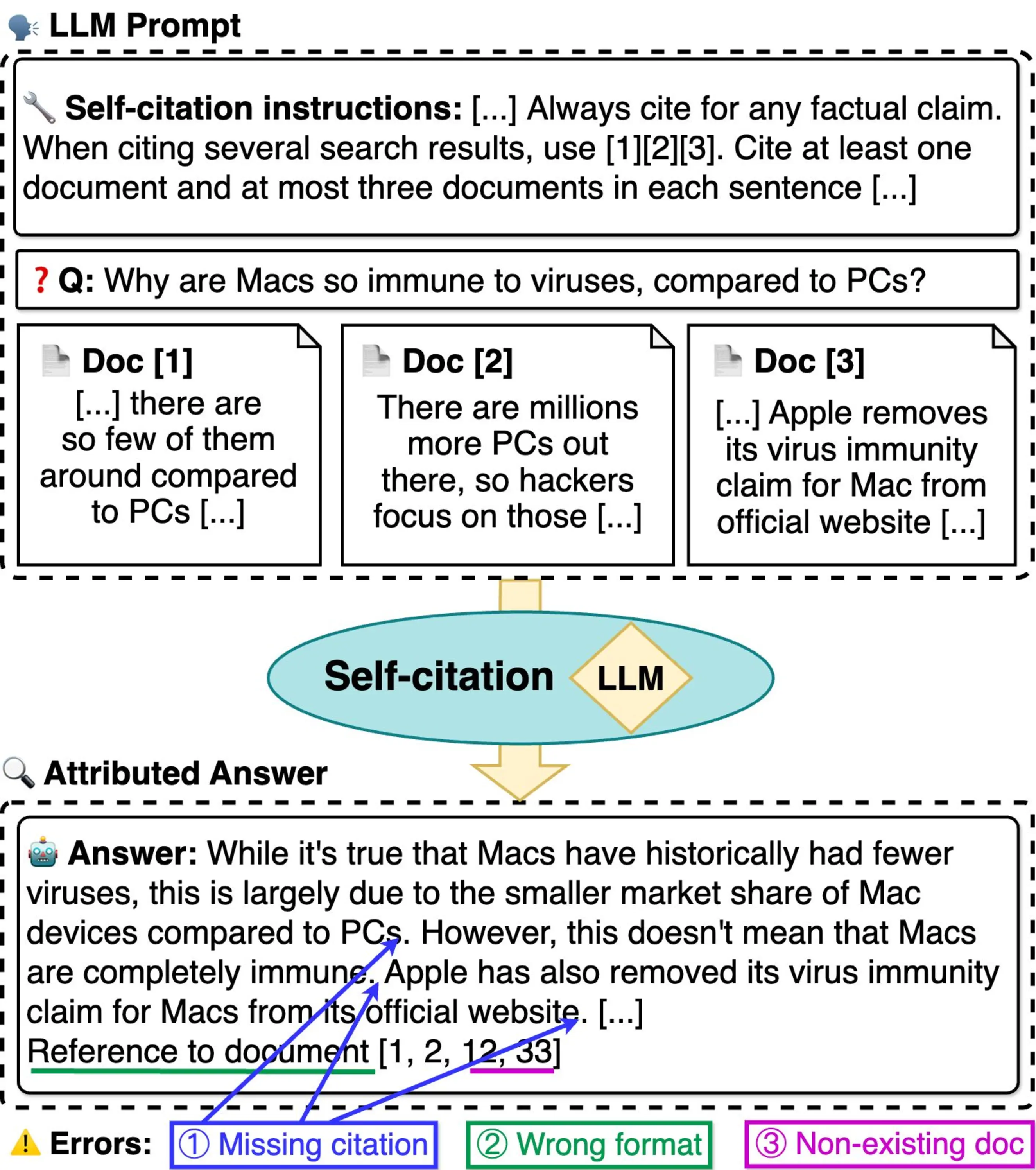
Self-citation (Gao et al., 2023a) is a recent AA approach exploiting the ability of recent LLMs to follow instructions in natural language (Raffel et al., 2020; Chung et al., 2024; Sanh et al., 2022; OpenAI, 2023), thereby avoiding the need for an external validator. Nakano et al. (2021) and Menick et al. (2022) propose citation fine-tuning for LLMs, while Gao et al. (2023a) instruct general-purpose LLMs to produce inline citations in a few-shot setting. Self-citation answers are generally more relevant to the provided sources’ contents, but can still contain unsupported statements and inaccurate citations (Liu et al., 2023). In our preliminary analysis, we find that self-citation often misses relevant citations, uses wrong formats, or refers to non-existing documents (Figure 5.2). For the ELI5 dataset (Fan et al., 2019), we find that LLaMA 2 7B Chat (Touvron et al., 2023) and Zephyr \(\beta\) 7B (Tunstall et al., 2024) fail to produce AAs matching the prompt instructions for the majority of generated sentences, with almost all answers having at least one unattributed sentence when the Gao et al. (2023a) self-citation setup is used (Table 5.1).
| Model | Missing citation (%) | |
|---|---|---|
| Sentence | Answer | |
| Zephyr 7B \(\beta\) | 54.5 | 95.7 |
| LLaMA 2 7B Chat | 62.4 | 99.3 |
Answer Attribution can be Unfaithful The aforementioned approaches do not account for attributions’ faithfulness, i.e. whether the selected documents influence the LLM during the generation. Indeed, the presence of an entailment relation or high semantic similarity does not imply that the retrieved document influenced the answer generation process. This can be true in cases where LLMs may rely on memorized knowledge while ignoring relevant, albeit unnecessary, contextual information.
Even in the case of self-citation, recent work showed that, while the justifications of self-explaining LLMs appear plausible, they generally do not align with their internal reasoning process (Atanasova et al., 2023; Madsen et al., 2024; Agarwal et al., 2024; Randl et al., 2025), with little to no predictive efficacy (Huang et al., 2023). By contrast, approaches based on model internals are designed to faithfully reflect input importance in motivating model predictions. For instance, Alghisi et al. (2024) explores the use of gradient-based attribution to locate salient history segments for various dialogical tasks.
Concurrent to our work, Phukan et al. (2024) and Cohen-Wang et al. (2024) have proposed other internals-based methods for granular AA of LLM generations. While the two-step approaches proposed in both works are similar to Mirage, they also differ in substantial ways. Notably, Phukan et al. (2024) derive attributions from embedding similarity, which does not capture the functional influence of context usage during the generation process. ContextCite (Cohen-Wang et al., 2024) instead fits a linear surrogate model to estimate the impact of ablating context segments on downstream answer probabilities. While this procedure approximates causal context influence, it still requires a sufficiently large context and many LLM forward passes to learn the surrogate model4, ultimately providing a coarser attribution for the full generated output. On the contrary, Mirage efficiently estimates generated tokens requiring attribution via contrastive metrics to produce granular attributions at the token level, limiting computations to estimate how context impacts LLM predictions. A maximally faithful AA approach would ablate all possible combinations of context elements to counterfactually estimate their importance in relation to model predictions. Given the long-form answers and contexts in RAG settings, this is practically unfeasible. Even if based on approximations, internals-based approaches such as Mirage are intrinsically more faithful than external validators like NLI models, since they aim to exploit information functional to the predictive process rather than relying solely on the generated output.
5.3 Method
Identifying which generated spans were most influenced by preceding information is a key challenge for LM attribution. The Model Internals-based RAG Explanations (Mirage) method we propose is an extension of the Plausibility Evaluation for Context Reliance (PECoRe) framework (Sarti et al., 2024) for context-aware machine translation. Importantly, this framework requires open-weights access to the LLM generator, which is a strict but necessary requirement to provide an accurate overview of the actual context usage during generation (Casper et al., 2024). This section frames the PECoRe’s two-step procedure in the context of RAG, as illustrated in Figure 5.3, and clarifies how Mirage adapts it for RAG answer attribution.
Step 1: Context-sensitive Token Identification (CTI) For every token in an answer sentence \(\mathbf{y} = \langle y_1, \dots, y_{n} \rangle\) generated by an LM prompted with a query \(\mathbf{q}\) and a context \(\mathbf{c} = \langle c_1, \dots, c_{|\mathbf{c}|} \rangle\), a contrastive metric \(m\) such as KL divergence (Kullback and Leibler, 1951) is used to quantify the shift in the LM predictive distribution at the \(i\)-th generation step when the context is present or absent (\(P^i_\text{ctx}\) or \(P^i_\text{no-ctx}\)). Resulting scores \(\mathbf{m} = \langle m_1, \dots, m_{n} \rangle\) reflect the context sensitivity of every generated token and can be converted into binary labels using a selector function \(s_\text{cti}\):
\[ \begin{split} \text{CTI}(\mathbf{q}, \mathbf{c}, \mathbf{y}) = \{\,y_i\,|\,s_\text{cti\,}(m_i) = 1\,\forall y_i \in \mathbf{y}\} \\ \text{with}\;m_i = D_\text{KL}(P^i_\text{ctx} \| P^i_\text{no-ctx}) \end{split} \]
Step 2: Contextual Cues Imputation (CCI) For every context-sensitive token \(y_i\) identified by CTI, a contrastive alternative \(y^{\setminus \mathbf{c}}_i\) is produced by excluding \(\mathbf{c}\) from the prompt, but using the original generated prefix \(\mathbf{y}_{<i}\). Then, contrastive input attribution (Yin and Neubig, 2022) is used to obtain attribution scores \(\mathbf{a}^i = \langle a^i_1, \dots, a^i_{|\mathbf{c}|} \rangle\) for every context token \(c_j \in \mathbf{c}\):
\[ \begin{split} \mathbf{a}^i = \big\{\,\nabla_j\big(p(y_i) - p(y^{\setminus \mathbf{c}}_i)\,\big),\;\forall c_j \in \mathbf{c}\,\} \end{split} \]
where \(\nabla_j\) is the L2 norm of the gradient vector over the input embedding of context token \(c_j\), and both probabilities are computed from the same contextual inputs \((\mathbf{q}, \mathbf{c}, \mathbf{y}_{<i})\). Intuitively, this procedure identifies which tokens in \(\mathbf{c}\) influence the increment of the probability for token \(y_i\) and the decrement of that for the non-contextual option \(y^{\setminus \mathbf{c}}_i\), as shown in Step 2 in Figure 5.3. Resulting scores are once again binarized with a selector \(s_\text{CCI}\):
\[ \text{CCI}(y_i) = \{\,c_j\,|\,s_\text{cci\,}(a^i_j) = 1,\;\forall c_j \in \mathbf{c}\} \]
This results in pairs of context-sensitive generated tokens and the respective input-context tokens influencing their prediction:
\[ \mathcal{P} = \big\{ \langle\,y_i, c_j\,\rangle,\; \forall y_i \in \text{CTI}, \forall c_j \in \text{CCI}(y_i)\big\} \]
5.3.1 From Granular Attributions to Document-level Citations
CTI Filtering To obtain discrete labels from the CTI step, we set \(s_\text{cti}(m_i) = m_i \geq m^*\), where \(m^*\) is a threshold value for selecting context-sensitive generated tokens. We experiment with two variants of \(m^*\): a calibrated threshold \(m_{\text{cal}}^*\) obtained by maximizing agreement between the contrastive metric and human annotations on a calibration set with human AA annotations, and an example-level threshold \(m_\text{ex}^*\) using only within-example scores to avoid the need for calibration data. Following Sarti et al. (2024), we set \(m_\text{ex}^* = \overline{\mathbf{m}} + \sigma_\mathbf{m}\), where \(\overline{\mathbf{m}}\) and \(\sigma_\mathbf{m}\) are the average and standard deviation of \(\mathbf{m}\) scores for generated tokens.
CCI Filtering To extract granular document citations (i.e., colored spans with document indices in Figure 5.1), we set \(s_\text{cci} = a^i_j \geq a^{i*}\), where \(a^{i*}\) is either the Top-K or Top-% highest attribution value in \(\mathbf{a}^i\), to filter attributed context tokens \(c_j \in \text{CCI}(y_i)\). Then, we use the identifier \(\text{docid}(c_j)\) of the documents they belong to as citation indices for context-sensitive token \(y_i\). Highlights for consecutive tokens citing the same documents are collated into a single span and mapped from subword to word level to facilitate interpretation.
Sentence-level Aggregation Following standard sentence-level AA practices, we aggregate token-level citations as the union over all cited documents \(\text{docid}(\cdot)\) across context-sensitive tokens in \(\mathbf{y}\):
\[ \begin{gathered} \text{Mirage}(\mathbf{y}) = \bigcup_{y_i \in \text{CTI}(\mathbf{y})} \text{docid}(c_j)\;\forall c_j \in \text{CCI}(y_i) \\ \text{with}\;s_\text{cti} = m_i \geq m^*, s_\text{cci} = a^i_j \geq a^{i*} \end{gathered} \]
In the following sections, we use Mirage\(_{\text{cal}}\) and Mirage\(_{\text{ex}}\) to refer to sentence-level answer attribution using \(m_{\text{cal}}^*\) and \(m_{\text{ex}}^*\) thresholds, respectively.
5.4 Agreement with Human Answer Attribution Annotations
We begin our evaluation by comparing Mirage predictions to human-produced answer attributions. Importantly, our aim is not to compare several AA approaches to claim optimal faithfulness, but rather to evaluate how our proposed framework fares against existing approaches at the task of producing answer attributions from model internals. We employ the XOR-AttriQA dataset (Muller et al., 2023), which, to our knowledge, is the only open dataset with human annotations over RAG outputs produced by a publicly accessible LM.5
We limit our assessment to open-weights LLMs to ensure that Mirage answer attribution can faithfully reflect the model’s inner processing towards the natural production of the annotated answer used for evaluation. While these answers could be force-decoded from an open-source model to enable usage, such a procedure would likely impact the validity of AA, as the selected model would not naturally generate the forced answers. Moreover, while cross-linguality is not the focus of our work, XOR-AttriQA allows us to assess the robustness of Mirage across several languages and its agreement with human annotations compared to an entailment-based system.
5.4.1 Experimental Setup
XOR-AttriQA consists of 500/4720 validation/test tuples, each containing a concise factual query \(\mathbf{q}\), a set of retrieved documents that we use as context \(\mathbf{c} = \langle \text{doc}_1, \dots, \text{doc}_k \rangle\), and a single-sentence answer \(\mathbf{y}\) produced by an mT5-base model (Xue et al., 2021) fine-tuned on cross-lingual QA in a RAG setup (CORA; Asai et al. (2021)). Queries and documents span five languages —Bengali (BN), Finnish (FI), Japanese (JA), Russian (RU), and Telugu (TE)—and cross-lingual retrieval is allowed.
Although the RAG generator employs a set of retrieved documents during generation, human annotators were asked to label tuples \((\mathbf{q}, \text{doc}_i, \mathbf{y})\) to indicate whether the information in \(\text{doc}_i\) supports the generation of \(\mathbf{y}\).
| Dataset | BN | FI | JA | RU | TE | Total |
|---|---|---|---|---|---|---|
| Orig. | 1407 | 659 | 1066 | 954 | 634 | 4720 |
| Match | 274 | 214 | 232 | 254 | 170 | 1144 |
Notably, Mirage requires extracting model internals in the naturalistic setting that leads to the generation of the desired answer, i.e., the one assessed by human annotators. Hence, we perform a selection procedure to identify XOR-AttriQA examples where the answer produced by filling in the concatenated documents \(\mathbf{c}\) in the LM prompt matches the one provided. The resulting subset, which we dub XOR-AttriQA\(_{\text{match}}\), contains 142/1144 calibration/test examples and is used for our evaluation. Replicating the original answer generation process is challenging since the original ordering of the documents \(\text{doc}_i\) in \(\mathbf{c}\) is unavailable.6 To maximize the chances of replication, we attempt to restore the original document sequence by randomly shuffling the order of \(\text{doc}_i\)s until LLM can naturally predict the answer \(\mathbf{y}\). The procedure adopted is described in Algorithm 1. The statistics of the original XOR-AttriQA and XOR-AttriQA\(_{\text{match}}\) are shown in Table 5.2.
5.4.2 Entailment-based Baselines
Muller et al. (2023) use an mT5 XXL model fine-tuned on NLI for performing answer attribution on XOR-AttriQA. Since neither the tuned model nor the tuning data are released, we opt to use TRUE (Honovich et al., 2022), a fine-tuned T5 11B model (Raffel et al., 2020), which was shown to highly overlap with human annotation on English answer attribution tasks (Muller et al., 2023; Gao et al., 2023a). We evaluate TRUE agreement with human annotation in two setups. In NLI\(_\text{orig}\), we evaluate the model directly on all examples, including non-English data. While this leads the English-centric TRUE model out of distribution, it accounts for real-world scenarios with noisy data, and can be used to assess the robustness of the method in less-resourced settings. Instead, in NLI\(_\text{mt}\), all queries and documents are machine translated to English using the Google Translate API. While this simplifies the task by ensuring all TRUE inputs are in English, it can lead to information loss due to imprecise translation.
5.4.3 Results and Analysis
Mirage agrees with human answer attribution Table 5.3 presents our results. Mirage is found to largely agree with human annotations on XOR-AttriQA\(_{\text{match}}\), with scores on par or slightly better than those of the ad-hoc NLI\(_\text{mt}\) system augmented with automatic translation. Although calibration appears to generally improve Mirage’s agreement with human annotators, we note that the uncalibrated Mirage\(_{\text{ex}}\) achieves strong performances despite having no access to external modules or tuning data. These findings confirm that the inner workings of LMs can be used to perform answer attribution, yielding performances on par with supervised answer attribution approaches even in the absence of annotations for calibration.
| Method | Extra Req. | CCI Filter | BN | FI | JA | RU | TE | Avg. / Std |
|---|---|---|---|---|---|---|---|---|
| NLI\(_{\text{orig}}\) | 11B NLI model | -- | 33.8 | 83.7 | 86.5 | 85.8 | 50.0 | 68.0 / 21.9 |
| NLI\(_{\text{mt}}\) | 11B NLI model + MT | 82.6 | 83.7 | 90.5 | 81.7 | 82.5 | 84.2 / 3.2 | |
| Mirage\(_{\text{cal}}\) (Ours) | 142 annotated AA ex. | Top 3 | 81.7 | 84.2 | 87.8 | 83.3 | 87.0 | 84.8 / 2.3 |
| Top 5% | 84.4 | 83.0 | 91.4 | 85.8 | 88.9 | 86.7 / 3.1 | ||
| Mirage\(_{\text{ex}}\) (Ours) | -- | Top 3 | 80.2 | 78.5 | 83.8 | 77.2 | 75.2 | 79.0 / 2.9 |
| Top 5% | 81.7 | 80.1 | 89.2 | 84.4 | 81.8 | 83.4 / 3.2 |
Mirage is robust across languages and filtering procedures Table 5.3 shows that NLI\(_\text{orig}\) answer attribution performances are largely language-dependent due to the unbalanced multilingual abilities of the TRUE NLI model. This highlights the brittleness of entailment-based approaches in OOD settings, as discussed in Section 5.2.1. Instead, Mirage variants perform similarly across all languages by exploiting the internals of the multilingual RAG model. Mirage’s performance across languages is comparable to that of NLI\(_\text{mt}\), which requires an extra translation step to operate on English inputs.
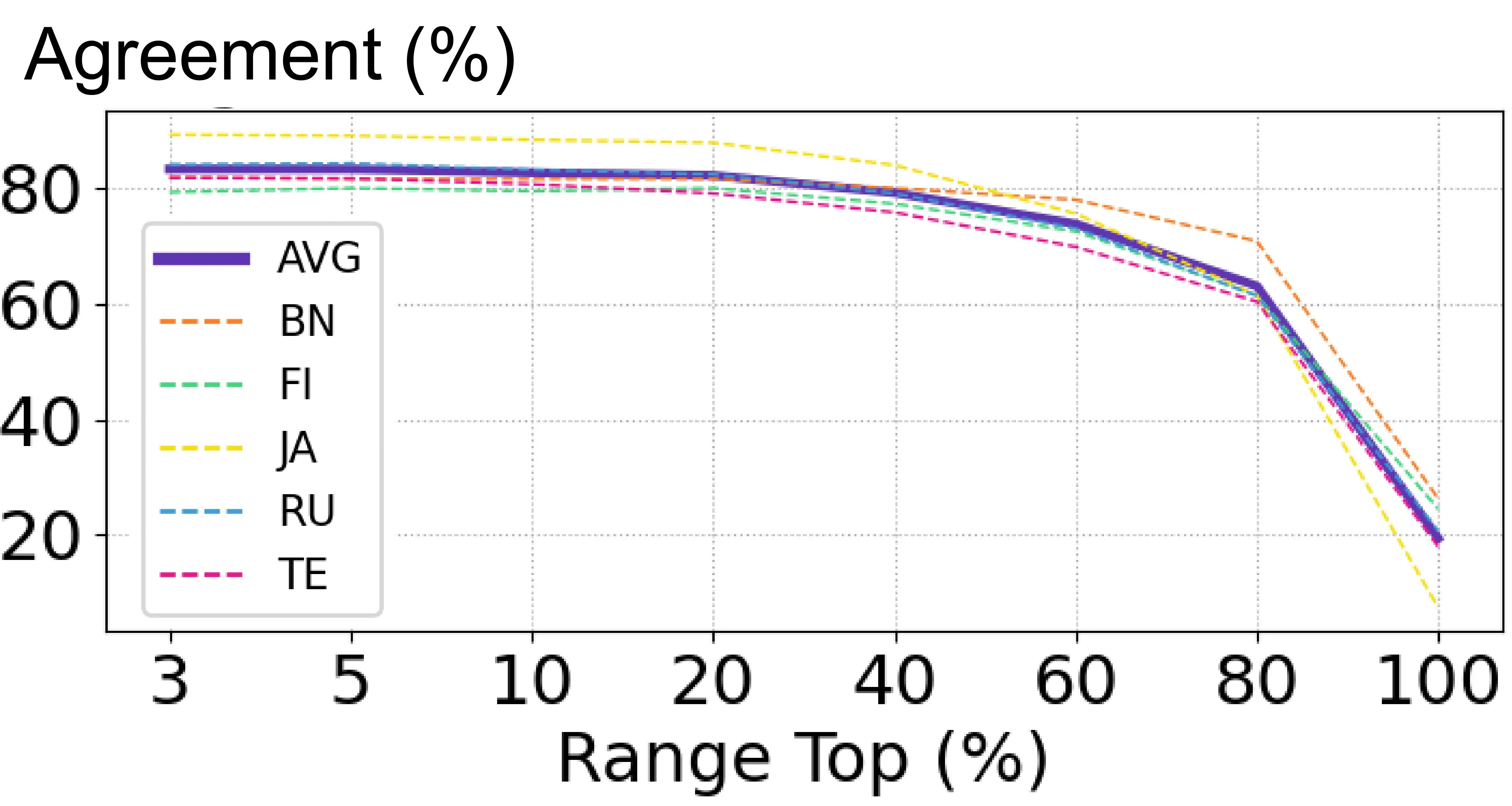
We further validate the robustness of the CCI filtering process by testing percentile values between Top 3-100% for the Mirage\(_{\text{ex}}\) setting. Figure 5.4 shows that Top % values between 3 and 20% lead to a comparably high agreement with human annotation, suggesting this filtering threshold can be selected without ad-hoc parameter tuning.
5.5 Answer Attribution for Long-form QA
XOR-AttriQA can only provide limited insights for real-world answer attribution evaluation, as its examples are sourced from Wikipedia articles and its answers are very concise. In this section, we extend our evaluation to ELI5 (Fan et al., 2019), a challenging long-form QA dataset that was recently employed to evaluate LLM self-citation capabilities (Gao et al., 2023a). Different from XOR-AttriQA, ELI5 answers are expected to contain multiple sentences of variable length, making it especially fitting to assess Mirage context-sensitive token identification capabilities before document attribution. Alongside our quantitative assessment of Mirage in relation to self-citation baselines, we conduct a qualitative evaluation of the disagreement between the two methods.
5.5.1 Experimental Setup
Dataset The ELI5 dataset contains open-ended why/how/what queries \(\mathbf{q}\) from the “Explain Like I’m Five” subreddit eliciting long-form multi-sentence answers. For our evaluation, we use the RAG-adapted ELI5 version by Gao et al. (2023a), containing top-5 matching documents \(\mathbf{c} = \langle \text{doc}_1, \dots, \text{doc}_5 \rangle\) retrieved from a filtered version of the Common Crawl (Sphere; Piktus et al. (2021)) for every query. The answer attribution task is performed by generating a multi-sentence answer \(\mathbf{ans} = \langle \mathbf{y}_1, \dots, \mathbf{y}_m \rangle\) with an LLM using \((\mathbf{q}, \mathbf{c})\) as inputs, and identifying documents in \(\mathbf{c}\) supporting the generation of answer sentence \(\mathbf{y}_i,\,\forall \mathbf{y}_i \in \mathbf{ans}\).
Models and Answer Attribution Procedure We select LLaMA 2 7B Chat (Touvron et al., 2023) and Zephyr \(\beta\) 7B (Tunstall et al., 2024) for our experiments since they are high-quality open-source LLMs of manageable size. To enable a fair comparison between the tested attribution methods, we first generate answers with inline citations using the self-citation prompt by Gao et al. (2023b). Then, we remove citation tags and use Mirage to attribute the resulting answers to retrieved documents. This process ensures that citation quality is compared over the same set of answers, controlling for the variability that a different prompt could produce. For more robust results, we perform generation three times using different sampling seeds, and report the averaged scores. Since human-annotated data is not available, we only assess the calibration-free Mirage\(_{\text{ex}}\).
Entailment-based Evaluation Differently from the XOR-AttriQA dataset used in Section 5.4, ELI5 does not contain human annotations of AA. For this reason, and to ensure consistency with Gao et al. (2023a) self-citation assessment, we adopt the TRUE model as a high-quality approximation of expected annotation behavior. Despite the potential OOD issues of entailment-based AA highlighted in Section 5.4, we expect TRUE to perform well on ELI5 since it closely matches the general/scientific knowledge queries in TRUE’s fine-tuning corpora and contains only English sentences. To overcome the multi-hop issue when using single documents for entailment-based answer attribution, we follow the ALCE evaluation (Gao et al., 2023a) to measure citation quality as NLI precision and recall (summarized by F1 scores) over the concatenation of retrieved documents. The ALCE framework for RAG QA evaluation assesses the LLMs’ responses from three viewpoints: citation quality, correctness, and fluency. Citation quality evaluates the answer attribution performance with recall and precision scores. The recall score calculates if the concatenation of the cited documents entails the generated sentence. The precision measures whether each document is cited precisely by verifying if the concatenated text still entails the generation whenever one of the documents is removed. We further calculate F1 scores to summarize the overall performance.
5.5.2 Results
Results in Table 5.4 show that Mirage provides a significant boost in answer attribution precision and recall for the Zephyr \(\beta\) model. At the same time, it greatly improves citation recall at the expense of precision for LLaMA 2, resulting in an overall higher F1 score for the Mirage\(_{\text{ex}}\) Top 5% setting. These results confirm that Mirage can produce effective answer attributions in longer and more complex settings while employing no external resources like the self-citation approach.
| Model | Answer Attrib. | Citation | ||
|---|---|---|---|---|
| Prec. | Rec. | F1 | ||
| Zephyr \(\beta\) | Self-citation | 41.4 | 24.3 | 30.6 |
| Mirage\(_{\text{ex}}\) Top 3 | 38.3 | 46.2 | 41.9 | |
| Mirage\(_{\text{ex}}\) Top 5% | 44.7 | 46.5 | 45.6 | |
| LLaMA 2 | Self-citation | 37.9 | 19.8 | 26.0 |
| Mirage\(_{\text{ex}}\) Top 3 | 21.8 | 29.6 | 25.1 | |
| Mirage\(_{\text{ex}}\) Top 5% | 26.2 | 29.1 | 27.6 | |
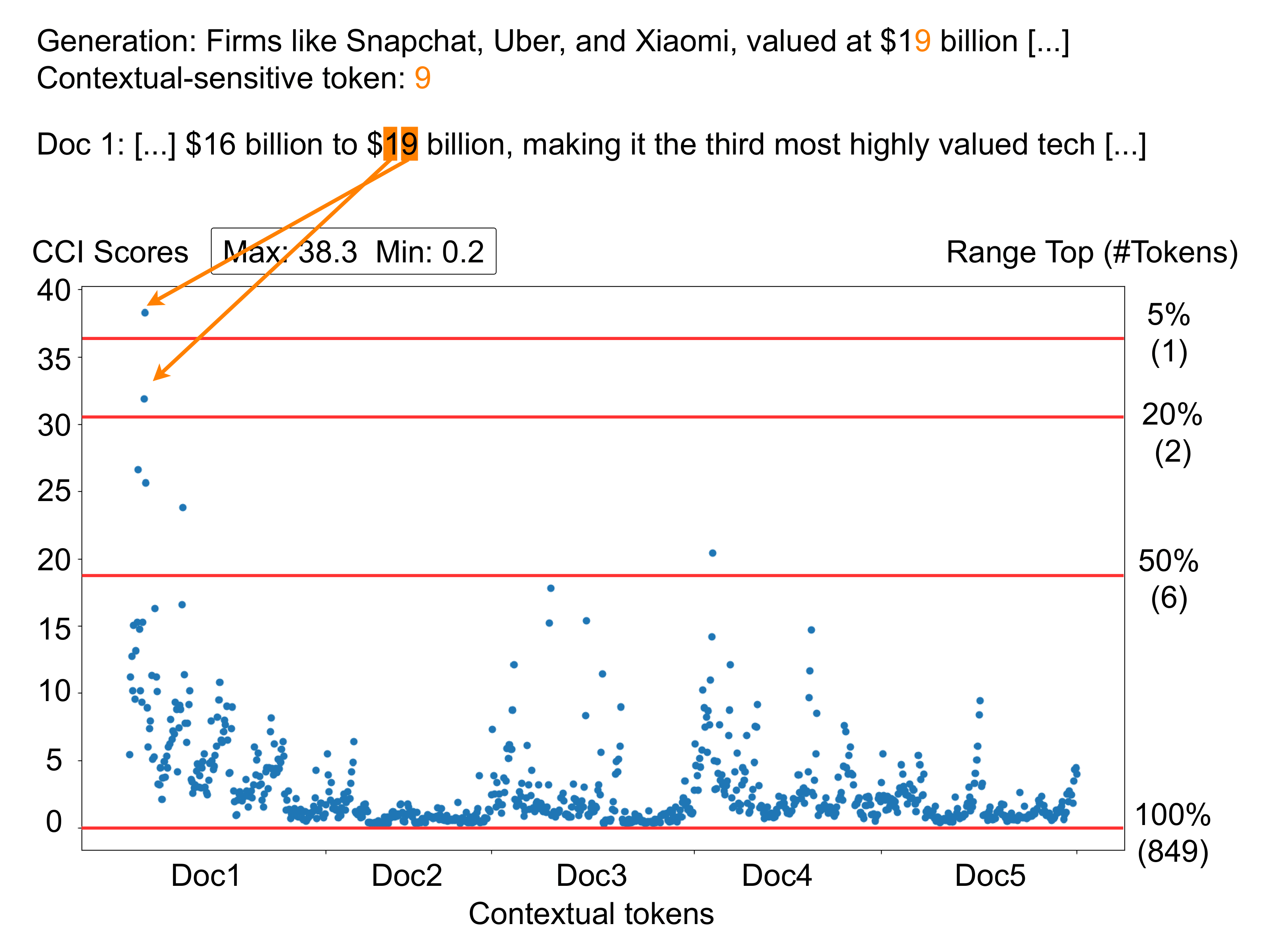
From the comparison between Top 3 and Top 5% CCI filtering strategies, we note that the latter generally results in better performance. This intuitively supports the idea that an adaptive selection strategy is more suitable for accommodating the wide variability of attribution scores across different examples. Figure 5.5 visualizes the distributions of attribution scores \(a^i_j\) for an answer produced by Zephyr \(\beta\), showing that most context tokens in retrieved documents receive low attribution scores, with only a handful of them contributing to the prediction of the context-sensitive token ‘9’ in the generation. This example also provides an intuitive explanation of the robustness of Top-% selection thresholds discussed in Section 5.4.3. Ultimately, the Top 5% threshold is sufficient to select the document containing the direct mention of the generated token.
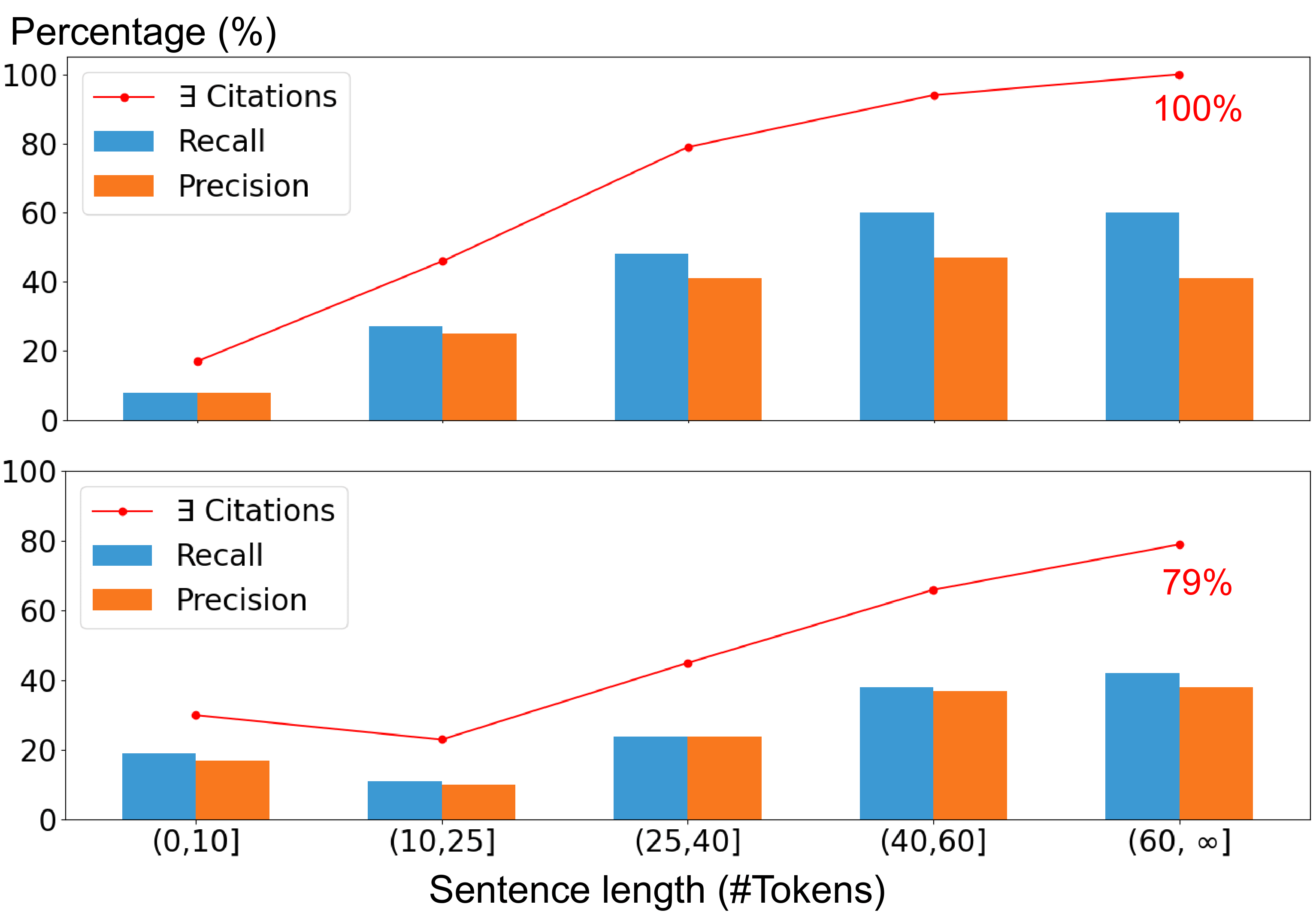
Since the \(m^*_\text{ex}\) threshold used to select context-sensitive tokens by Mirage\(_{\text{ex}}\) depends on the mean and standard deviation of generated answer’s scores, we expect that the length of the generated answer might play a role in citation quality. As shown in Figure 5.6, Mirage citation quality is indeed lower for shorter answer sentences. However, a similar trend is observed for self-citation, which is outperformed by Mirage for all but the shortest length bin (\(\leq 10\) tokens). The proportion of non-attributed sentences (red line) suggests that the lower quality could be a byproduct of the ALCE evaluation protocol, where non-attributed sentences receive zero precision/recall. Future availability of human-annotated RAG datasets may shed more light on this effect.
5.5.3 Qualitative Analysis of Disagreements
To better understand Mirage’s performance, we examine some ELI5 examples where Mirage disagrees with self-citation on Zephyr \(\beta\)’s generations. Table 5.5 and Table 5.6 illustrate two cases in which the entailment-based TRUE model results agree with either Mirage or self-citation.
In Table 5.5, the answer provided by the model is directly supported by Document [1], as also identified by TRUE. However, self-citation fails to cite the related document at the end of the two sentences. By contrast, Mirage attributes several spans to Document [1], resulting in the correct answer attribution for both sentences.
| Input: Prompt + Retrieved docs (N=5) + Query |
| Document [1] […] Q. What does it mean for books to be Sensitized or Desensitized? A security strip is embedded into each library book. When a book is checked out, it must be ‘desensitized’ so that it will not set off the alarm when it leaves or enters the library. When the book is returned, it is ‘sensitized’ so that the alarm will be set off should someone attempt to take the book from the library without going through the proper borrowing procedure. |
| Document [2] […] |
| Query: How does a small paper library bar code set off the security alarm when you haven’t checked a book out? |
| Answer attribution results |
| Self-citation: […] When a book is checked out, it is ‘desensitized’ to prevent the alarm from going off. [\(\varnothing\)] When the book is returned, it is ‘sensitized’ so the alarm will sound if the item is taken without authorization. [\(\varnothing\)] […] |
| Mirage: […] When a book is checked\(^{(1)}\) out, it\(^{(1)}\) is ‘desensitized’\(^{(1)}\) to prevent the alarm from going off. [1] When the book\(^{(1)}\) is returned, it is ‘sensitized’\(^{(1)}\) so the alarm will sound if the item is taken without authorization. [1] […] |
| NLI (True model): [1] entails both answer sentences. |
While TRUE achieves high consistency with human judgment (e.g., for the example in Table 5.5), NLI-based AA can still prove unreliable in cases of high lexical overlap between the answer and supporting documents. Table 5.6 illustrates one such case, where both self-citation and TRUE attribute the answer to Document [3], whereas Mirage does not label any context document as salient for the answer. Here, the answer wrongly states that the bar code can be used to prevent the alarm, while Document [3] mentions that the code can be used to cancel the alarm after an accidental activation. Thus, despite the high lexical and semantic relatedness, the answer is not supported by Document [3]. The failure of TRUE in this setting highlights the sensitivity of entailment-based systems to surface-level similarity, making them brittle in cases where the model’s context usage is not straightforward. Using another sampling seed for the same query produces the answer “[…] the individual can cancel the alarm by providing their password at the keypad”, which Mirage correctly attributes to Document [3].
| Input: Prompt + Retrieved docs (N=5) + Query |
| Document [2] […] |
| Document [3] […] What will happen if you accidentally set off your security system? The siren will sound and it will be loud, but you should be able to stop the siren by entering your code into your keypad. […] |
| Document [4] […] |
| Query: How does a small paper library bar code set off the security alarm when you haven’t checked a book out? |
| Answer attribution results |
| Self-citation: […] False alarms can be prevented by entering the code on the keypad, as documented in [3]. […] |
| Mirage: […] False alarms can be prevented by entering the code on the keypad [\(\varnothing\)] […] |
| NLI (True model): [3] entails the answer sentence. |
5.6 Limitations
We now highlight some limitations of the Mirage method and our experimental evaluation, which should be addressed in future work.
LLMs Optimized for Self-citation Our analysis focuses specifically on models that are not explicitly trained to perform self-citation and can provide citations only when prompted to do so. While recent systems incorporate self-citation into their optimization scheme for RAG applications, incorporating model internals into the attribution process will remain a valuable and inexpensive method to ensure faithful answer attributions.
Brittleness of NLI-based Evaluation Following Gao et al. (2023a), the evaluation of Section 5.5 employs the NLI-based system TRUE due to the lack of AA-annotated answers produced by open-source LLMs. However, using the predictions of NLI models as AA references is far from ideal, given their brittleness in challenging scenarios and their tendency to exploit shallow heuristics. While the ELI5 dataset is reasonably in-domain for the TRUE model, this factor might still undermine the reliability of some of our quantitative evaluation results. Future work should produce a wider variety of annotated datasets for reproducible answer attribution using open-source LLMs, enabling us to extend our analysis to a broader set of languages and model sizes and ultimately enhance the robustness of our findings.
Applicability to Other Domains and Models Our evaluation is conducted on relatively homogeneous QA datasets and does not include language models with >7B parameters. This limits the generalizability of our findings to other domains and larger models. Future work should extend our analysis to a broader range of domains and model sizes to further validate the robustness and applicability of Mirage. This said, we expect Mirage to be less vulnerable to language and quality shifts compared to existing AA methods that depend on external validators or on the model’s instruction-following abilities.
Scalability on Longer Context The computational cost for the simple gradient-based version of Mirage we propose is \(2O(F)+|\text{CTI}(\mathbf{y})| \cdot O(B)\), where \(O(F), O(B)\) are respectively the costs of a forward and a backward pass with the LLM, and \(|\text{CTI}(\mathbf{y})|\) is the number of tokens selected by the CTI step. While CTI effectively limits the expensive backward component in the Mirage computation, its cost is bound to increase significantly for larger models and context sizes. When applying Mirage to LLMs with <10B parameters, we note that its cost can be comparable or lower to supervised models like TRUE, requiring several forward passes using a large 11B LLM. Importantly, Mirage is a flexible framework that can be implemented using different input attribution methods in the CCI step, including lightweight techniques that require only forward passes, such as Attention Rollout (Abnar and Zuidema, 2020), Value Zeroing (Mohebbi et al., 2023), or ALTI-Logit (Ferrando et al., 2023). Finally, a promising perspective for scaling to larger LLMs could be to assess whether Mirage-produced AAs remain accurate when force-decoding the original model’s answer from a different LLM with fewer parameters.
Parametrization and Choice of Attribution Method While Section 5.4 highlights the robustness of Mirage to various CCI filtering thresholds, the method still requires non-trivial parametrization. In particular, we emphasize that the choice of the attribution method employed to generate attribution scores in the CCI step can significantly impact the faithfulness of the resulting answer attributions. Although we used a relatively simple gradient-based approach, our proposed framework is method-agnostic. We leave the evaluation of modern input attribution techniques, such as the ones mentioned in the previous paragraph, to future work to further improve Mirage applicability in real-world settings.
5.7 Conclusion
In this chapter, we introduced Mirage, a novel approach to enhance the faithfulness of answer attribution in RAG systems. By leveraging model internals, Mirage effectively addresses the limitations of previous methods based on prompting or external NLI validators. Our experiments demonstrate that Mirage produces outputs that strongly agree with human annotations while being more efficient and controllable than its counterparts. Our qualitative analysis shows that Mirage can produce faithful attributions that reflect actual context usage during generation, reducing the risk of false positives motivated by surface-level similarity. Overall, Mirage represents a promising first step in exploiting interpretability insights to develop faithful answer attribution methods, paving the way for the usage of LLM-powered question-answering systems in real-world, user-facing applications.
In the next part of this thesis, we will move beyond analysis-driven methods to study how prompting (Chapter 6) and interpretability-based methods (Chapter 7) can be used to effectively condition the machine translation generation process.
We use the term answer attribution (AA) when referring to the task of citing relevant sources to distinguish it from the input attribution methods used in Mirage.↩︎
Code and data released at https://github.com/Betswish/MIRAGE. A demo for Mirage using the Inseq
attribute-contextAPI is available at https://hf.co/spaces/gsarti/mirage.↩︎Popular frameworks such as
LangChainandLlamaIndexsupport similarity-based citations using vector databases.↩︎Authors suggest a minimum of 32 different ablations.↩︎
E.g., the human-annotated answers in Bohnet et al. (2022) were generated by PALM 540B (Anil et al., 2023), whose internals are inaccessible. See Section A.3.1 for a comparison.↩︎
Muller et al. (2023) only provide the split documents without the original ordering.↩︎