4 Quantifying Context Usage in Neural Machine Translation
An interpretation will be meaningful to the extent that it accurately reflects some isomorphism to the real world.
– Douglas R. Hofstadter, Gödel, Escher, Bach: An Eternal Golden Braid (1979)
4.1 Introduction
Research in NLP interpretability defines various desiderata for rationales of model behaviors, i.e. the contributions of input tokens toward model predictions computed using input attribution (Madsen et al., 2022). One such property is plausibility, corresponding to the alignment between model rationales and salient input words identified by human annotators (Jacovi and Goldberg, 2020). Low-plausibility rationales typically occur alongside generalization failures or biased predictions and can be helpful in identifying cases where models are “right for the wrong reasons” (McCoy et al., 2019).
However, while plausibility has an intuitive interpretation for classification tasks involving a single prediction, extending this methodology to generative language models presents several challenges. First, LMs have a large output space in which semantically equivalent tokens (e.g. “PC” and “computer”) are competing candidates for next-word prediction (Holtzman et al., 2021). Moreover, LMs’ generations are the product of optimization pressures to ensure independent properties such as semantic relatedness, topical coherence and grammatical correctness, which can hardly be captured by a single attribution score (Yin and Neubig, 2022). Finally, since autoregressive generation involves an iterative prediction process, model rationales could be extracted for every generated token. This raises the issue of which generated tokens can have plausible contextual explanations.
Recent attribution techniques for explaining language models incorporate contrastive alternatives to disentangle different aspects of model predictions (e.g. the choice of “meowing” over “screaming” for “The cat is ___” is motivated by semantic appropriateness, but not by grammaticality) (Ferrando et al., 2023; Sarti et al., 2023). However, these studies circumvent the issues above by focusing their evaluation on a single generation step matching a phenomenon of interest. For example, given the sentence “The pictures of the cat ___”, a plausible rationale for the prediction of the word “are” should reflect the role of “pictures” in subject-verb agreement. While this approach can be helpful to validate model rationales, it confines plausibility assessment to a small set of handcrafted benchmarks where tokens with plausible explanations are known in advance. Moreover, it risks overlooking important patterns of context usage, including those that do not immediately match linguistic intuitions. In light of this, we suggest that identifying which generated tokens were most affected by contextual input information should be an integral part of plausibility evaluation for language generation tasks.
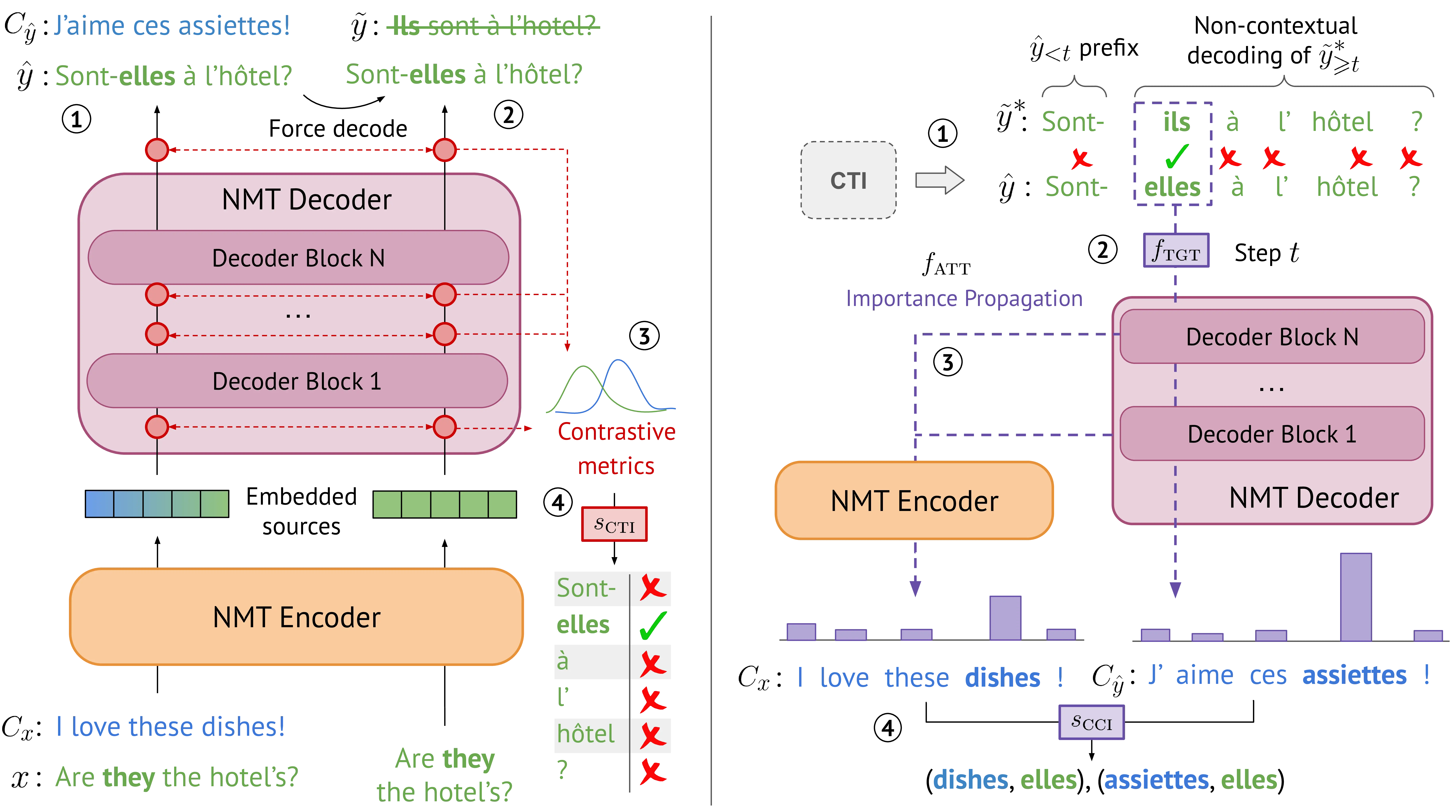
To achieve this goal, we propose a novel interpretability framework, which we dub Plausibility Evaluation of Context Reliance (PECoRe). PECoRe enables the end-to-end extraction of cue-target token pairs consisting of context-sensitive generated tokens and their respective influential contextual cues from language model generations, as shown in Figure 4.1. These pairs can uncover context dependence in naturally occurring generations and, for cases where human annotations are available, help quantify the plausibility of context usage in language models. Importantly, our approach is compatible with modern attribution methods using contrastive targets (Yin and Neubig, 2022), avoids relying on reference translations to avoid problematic distributional shifts (Vamvas and Sennrich, 2021b), and can be applied to unannotated inputs to identify context usage in model generations.

After formalizing our proposed approach in Section 4.3, we apply PECoRe to contextual machine translation to study the plausibility of context reliance in bilingual and multilingual MT models. While PECoRe can easily be used alongside encoder-decoder and decoder-only language models for interpreting context usage in any text generation task, we focus our evaluation on MT because of its constrained output space facilitating automatic assessment and the availability of MT datasets annotated with human rationales of context usage. We thoroughly test PECoRe on well-known discourse phenomena, benchmarking several context sensitivity metrics and attribution methods to identify cue-target pairs. We conclude by applying PECoRe to unannotated examples and showcasing some reasonable and questionable cases of context reliance in MT model translations.1
In sum, we make the following contributions:
- We introduce PECoRe, an interpretability framework to detect and attribute context reliance in language models. PECoRe enables a quantitative evaluation of plausibility for language generation beyond the limited artificial settings explored in previous literature.
- We compare the effectiveness of context sensitivity metrics and input attribution methods for context-aware MT, showing the limitations of metrics currently in use.
- We apply PECoRe to naturally-occurring translations to identify interesting discourse-level phenomena and discuss issues in the context usage abilities of context-aware MT models.
4.3 The PECoRe Framework
PECoRe is a two-step framework for identifying context dependence in generative language models. First, context-sensitive tokens identification (CTI) selects which tokens among those generated by the model were influenced by the presence of the preceding context (e.g. the feminine options “alla pastorella, le” in Figure 4.1). Then, contextual cues imputation (CCI) attributes the prediction of context-sensitive tokens to specific cues in the provided context (e.g. the feminine cues “she, Le pecore” in Figure 4.1). Cue-target pairs formed by influenced target tokens and their respective influential context cues can then be compared to human rationales to assess the models’ plausibility of context reliance for contextual phenomena of interest. Figure 4.2 provides an overview of the two steps applied to the context-aware MT setting discussed by this work. A more general formalization of the framework for language generation is proposed in the following sections.
4.3.1 Notation
Let \(X_\text{ctx}^{i}\) be the sequence of contextual inputs containing \(N\) tokens from vocabulary \(\mathcal{V}\), composed by current input \(x\), generation prefix \(y_{<i}\) and context \(C\). Let \(X_\text{no-ctx}^{i}\) be the non-contextual input in which \(C\) tokens are excluded.3 \(P_\text{ctx}^{i} = P\left(x,\, y_{<i},\,C,\,\theta\right)\) is the discrete probability distribution over \(\mathcal{V}\) at generation step \(i\) of a language model with \(\theta\) parameters receiving contextual inputs \(X_\text{ctx}^{i}\). Similarly, \(P_\text{no-ctx}^{i} = P\left(x,\, y_{<i},\,\theta\right)\) is the distribution obtained from the same model for non-contextual input \(X_\text{no-ctx}^{i}\). Both distributions are equivalent to vectors in the probability simplex in \(\mathbb{R}^{|\mathcal{V}|}\), and we use \(P_\text{ctx}(y_i)\) to denote the probability of next token \(y_i\) in \(P_\text{ctx}^{i}\), i.e. \(P(y_i\,|\,x,\,y_{<i},\,C)\).
4.3.2 Context-sensitive Token Identification (CTI)
CTI adapts the contrastive conditioning paradigm proposed by Vamvas and Sennrich (2021a) to detect input context influence on model predictions using the contrastive pair \(P_\text{ctx}^{i}, P_\text{no-ctx}^{i}\). Both distributions are relative to the contextual target sentence \(\hat y = \{\hat y_1 \dots \hat y_n\}\), corresponding to the sequence produced by a decoding strategy of choice in the presence of input context. In Figure 4.2, the contextual target sentence \(\hat y=\) “Sont-elles à l’hôtel?” is generated when \(x\) and contexts \(C_x, C_{\hat y}\) are provided as inputs, while non-contextual target sentence \(\tilde y =\) “Ils sont à l’hôtel?” would be produced when only \(x\) is provided. In the latter case, \(\hat y\) is instead force-decoded from the non-contextual setting to enable a direct comparison of matching outputs. We define a set of contrastive metrics \(\mathcal{M} = \{m_1, \dots, m_M\}\), where each \(m: \displaystyle \Delta_{|\mathcal{V}|} \times \Delta_{|\mathcal{V}|} \mapsto \mathbb{R}\) maps a contrastive pair of probability vectors to a continuous score. For example, the difference in next token probabilities for contextual and non-contextual settings, i.e. \(P_\text{diff}(\hat y_i) = P_\text{ctx}(\hat y_i) - P_\text{no-ctx}(\hat y_i)\), might be used for this purpose.4 Target tokens with high contrastive metric scores can be identified as context-sensitive, provided \(C\) is the only added parameter in the contextual setting. Finally, a selector function \(s_\text{cti}: \displaystyle \mathbb{R}^{| \mathcal{M} |} \mapsto \{0,1\}\) (e.g. a statistical threshold selecting salient scores) is used to classify every \(\hat y_i\) as context-sensitive or not.
4.3.3 Contextual Cues Imputation (CCI)
CCI applies the contrastive attribution paradigm (Yin and Neubig, 2022) to trace the generation of every context-sensitive token in \(\hat y\) back to the context \(C\), identifying the cues that drive model predictions.
Definition 4.1 Let \(s, s'\) be the resulting scores of two attribution target functions \(f_\text{tgt}, f'_\text {tgt}\). An attribution method \(f_\text{att}\) is if importance scores \(A\) are computed in relation to the outcome of its attribution target function, i.e. whenever the following condition is verified.
\[f_\text{att}(x, y_{<t}, C, \theta, s) \neq f_\text{att}(x, y_{<t}, C, \theta, s') \;\; \forall s \neq s'\]
In practice, common gradient-based attribution approaches (Simonyan et al., 2014; Sundararajan et al., 2017) are target-dependent as they rely on the outcome predicted by the model (typically the logit or the probability of the predicted class) as the differentiation target to backpropagate importance to model input features. Similarly, perturbation-based approaches (Zeiler and Fergus, 2014) use the variation in prediction probability for the predicted class when noise is added to some of the model inputs to quantify the importance of the noised features.
On the contrary, recent approaches that rely solely on model internals to define input importance are generally target-insensitive. For example, attention weights used as model rationales, either in their raw form or after a rollout procedure to obtain a unified score (Abnar and Zuidema, 2020), are independent of the predicted outcome. Similarly, value zeroing scores (Mohebbi et al., 2023) reflect only the representational dissimilarity across model layers before and after zeroing value vectors, and as such do not explicitly account for model predictions.
Definition 4.2 Let \(\mathcal{T}\) be the set of indices corresponding to context-sensitive tokens identified by the CTI step, such that \(t \in \hat y\) and \(\forall t \in \mathcal{T}, s_\text{cti}(m_1^{t}, \dots, m_M^{t}) = 1\). Let also \(f_\text{tgt}: \Delta_{|\mathcal{V}|} \times \dots \mapsto \mathbb{R}\) be a contrastive attribution target function representing an attribution target of interest, for example, the difference in next-token probabilities between the contextual option \(\hat y_t\) and the non-contextual option \(\tilde y^*_t\) from the same contextual distribution \(P_\text{ctx}^{t}\), plus any additional required parameter. The contrastive attribution method \(f_\text{att}\) is a composite function quantifying the importance of contextual inputs to determine the output of \(f_\text{tgt}\) for a given model with \(\theta\) parameters.
\[f_\text{att}(\hat y_{t}) = f_\text{att}(x, \hat y_{<t}, C, \theta, f_\text{tgt}) = f_\text{att}\big(x, \hat y_{<t}, C, \theta, f_\text{tgt}(P_\text{ctx}^t, \dots)\big)\]
Remark 4.1. The non-contextual next token \(\tilde y^*_t\) can be computed using the contextual prefix \(\hat y_{<t} = \{ \hat y_1, \dots, \hat y_{t - 1}\}\) (e.g. \(\hat y_{<t} =\)“Sont-” in Figure 4.2) and non-contextual inputs \(X_\text{no-ctx}^{t}\). This is conceptually equivalent to predicting the next token of a new non-contextual sequence \(\tilde y^*\) which, contrary to the original \(\tilde y\), starts from a forced contextual prefix \(\hat y_{<t}\) (e.g. “ils” in \(\tilde y^* =\) “ils à l’hôtel?” in Figure 4.2).
Remark 4.2. A \(f_\text{tgt}\) making use of both \(P_\text{ctx}^{t}\) and \(P_\text{no-ctx}^{t}\), e.g. the KL divergence between the contextual and non-contextual probability distributions (Kullback and Leibler, 1951), can ultimately result in non-zero \(f_\text{att}(\hat y_t)\) scores, even when \(\hat y_t = \tilde y^*_t\), i.e. even when the next predicted token is the same, since probabilities \(P_\text{ctx}(\hat y_t), P_{no-ctx}(\tilde y^*_t)\) are likely to differ beyond top-1 predictions. This is a desirable property of \(f_\text{att}\), as it allows the attribution method to capture the influence of context on the model’s decision-making process, even in the case where the predicted token remains unchanged.
Remark 4.3. Our formalization of \(f_\text{att}\) generalizes the method proposed by Yin and Neubig (2022) to support any target-dependent attribution method, such as popular gradient-based approaches (Simonyan et al., 2014; Sundararajan et al., 2017), and any contrastive attribution target \(f_\text{tgt}\).
\(f_\text{att}\) produces a sequence of attribution scores \(A_t = \{a_1, \dots, a_N\}\) matching contextual input length \(N\). From those, only the subset \(A_{t\,\text{ctx}}\) of scores corresponding to context input sequence \(C\) are passed to selector function \(s_\text{cci}: \displaystyle \mathbb{R} \mapsto \{0,1\}\), which predicts a set \(\mathcal{C}_{t}\) of indices corresponding to contextual cues identified by CCI, such that \(\forall c \in \mathcal{C}_t, \forall a \in A_{t\,\text{ctx}}, s_\text{cci}(a_{c}) = 1\).
Having collected all context-sensitive generated token indices \(\mathcal{T}\) using CTI and their contextual cues through CCI (\(C_t\)), PECoRe ultimately returns a sequence \(S_\text{ct}\) of all identified cue-target pairs:
\[ \begin{aligned} \mathcal{T} &= \text{CTI}(C, x, \hat y, \theta, \mathcal{M}, s_\text{cti}) = \{t \;|\; s_\text{cti}(m_1^t, \dots, m_M^t) = 1 \} \\ \mathcal{C} &= \text{CCI}(\mathcal{T}, C, x, \hat y, \theta, f_\text{att}, f_\text{tgt}, s_\text{cci}) = \{ c \;|\; s_\text{cci}(a_c) = 1 \,\forall a_c \in A_{t\,\text{ctx}}, \forall t \in \mathcal{T}\} \\ S &= \texttt{PECoRe}(C, x, \theta, s_\text{cti}, s_\text{cci}, \mathcal{M}, f_\text{att}, f_\text{tgt}) = \{ (C_c, \hat y_t) \;|\; \forall t \in \mathcal{T}, \forall c \in \mathcal{C}_t, \forall \mathcal{C}_t \in \mathcal{C} \} \end{aligned} \]
A pseudocode implementation for the PECoRe algorithm is provided in Algorithm 1.
4.4 Context Reliance Plausibility in Context-aware MT
This section describes our evaluation of PECoRe in a controlled setup. We experiment with several contrastive metrics and attribution methods for CTI and CCI (Section 4.4.2, Section 4.4.5), evaluating them in isolation to quantify the performance of individual components. An end-to-end evaluation is also performed in Section 4.4.5 to establish the applicability of PECoRe in a naturalistic setting.
4.4.1 Experimental Setup
Evaluation Datasets Evaluating generation plausibility requires human annotations for context-sensitive tokens in target sentences and disambiguating cues in their preceding context. To our knowledge, the SCAT dataset (Yin et al., 2021) is the only resource matching these requirements. SCAT is an English\(\rightarrow\)French corpus with human annotations of anaphoric pronouns and disambiguating context on OpenSubtitles2018 dialogue translations (Lison et al., 2018; Lopes et al., 2020). SCAT examples were extracted automatically using lexical heuristics and thus contain only a limited set of anaphoric pronouns (it, they \(\rightarrow\) il/elle, ils/elles), with no guarantees of contextual cues being found in preceding context.
The original SCAT test set contains 1000 examples with automatically identified context-sensitive pronouns it/they (marked by <p>...</p>) and human-annotated contextual cues aiding their disambiguation (marked by <hon>...</hoff>). Of these, we find 38 examples containing malformed tags and several more examples where an unrelated word containing it or they was wrongly marked as context-sensitive (e.g. the soccer ball h<p>it</p> your chest). Moreover, due to the original extraction process adopted for SCAT, there is no guarantee that contextual cues will be contained in the preceding context, as they could also appear in the same sentence, defeating the purpose of our context usage evaluation. Thus, we prefilter the entire corpus to retain only sentences with well-formed tags and inter-sentential contextual cues identified by the original annotators. Moreover, a manual inspection procedure is carried out to validate the original cue tags and discard problematic sentences, obtaining a final set of 250 examples with inter-sentential pronoun coreference, which we name SCAT+5.
Additionally, we manually annotate contextual cues in DiscEval-MT (Bawden et al., 2018), another English\(\rightarrow\)French corpus containing handcrafted examples for anaphora resolution (ana) and lexical choice (lex). In the case of DiscEval-MT, we use minimal pairs in the original dataset to automatically mark differing tokens as context-sensitive. Then, contextual cues are manually labeled separately by two annotators with good familiarity with both English and French. Cue annotations are compared across the two splits, resulting in very high agreement due the simplicity of the corpus (\(97\%\) overlap for ana, \(90\%\) for lex).6
Our final evaluation set contains 250 SCAT+ and 400 DiscEval-MT translations across two discourse phenomena. Table 4.1 provides some examples for the three data splits.
| SCAT+ |
| \(C_x\): I loathe that song. But why did you bite poor Birdie’s head off? Because I’ve heard it more times than I care to. It haunts me. Just stop, for a moment. |
| \(C_y\): Je hais cette chanson (song, feminine). Mais pourquoi avoir parlé ainsi à la pauvre Birdie ? Parce que j’ai entendu ce chant plus que de fois que je ne le peux. Elle (she) me hante. Arrêtez-vous un moment. |
| \(x\): How does it haunt you? |
| \(y\): Comment peut-elle (she) vous hanter? |
| \(C_x\): - Ah! Sven! It’s been so long. - Riley, it’s good to see you. - You, too. How’s the boat? Uh, it creaks, it groans. |
| \(C_y\): Sven ! - Riley, contente de te voir. - Content aussi. Comment va le bateau (boat, masculine)? Il (he) craque de partout. |
| \(x\): Not as fast as it used to be. |
| \(y\): Il (he) n’est pas aussi rapide qu’avant. |
| DiscEval-MT ana |
| \(C_x\): But how do you know the woman isn’t going to turn out like all the others? |
| \(C_y\): Mais comment tu sais que la femme (woman, feminine) ne finira pas comme toutes les autres? |
| \(x\): This one’s different. |
| \(y\): Celle-ci (This one, feminine) est différente. |
| \(C_x\): Can you authenticate these signatures, please? |
| \(C_y\): Pourriez-vous authentifier ces signatures (feminine), s’il vous plaît? |
| \(x\): Yes, they’re mines. |
| \(y\): Oui, ce sont les miennes (mines, feminine). |
| DiscEval-MT lex |
| \(C_x\): Do you think you can shoot it from here? |
| \(C_y\): Tu penses que tu peux le tirer (shoot) dessus à partir d’ici? |
| \(x\): Hand me that bow. |
| \(y\): Passe-moi cet arc (bow, weapon). |
| \(C_x\): Can I help you with the wrapping? |
| \(C_y\): Est-ce que je peux t’aider pour l’emballage (wrapping)? |
| \(x\): Hand me that bow. |
| \(y\): Passe-moi ce ruban (bow, gift wrap). |
Models We evaluate two bilingual Opus models (Tiedemann and Thottingal, 2020) using the transformer base architecture (Vaswani et al., 2017, Small and Large), and mBART-50 1-to-many (Tang et al., 2021), a larger multilingual MT model supporting 50 target languages, using the 🤗 transformers library (Wolf et al., 2020). We fine-tune models using extended translation units (Tiedemann and Scherrer, 2017) with contextual inputs marked by break tags such as source context <brk> source current to produce translations in the format target context <brk> target current, where context and current target sentences are generated. We perform context-aware fine-tuning on 242k IWSLT 2017 English\(\rightarrow\)French examples (Cettolo et al., 2017), using a dynamic context size of 0-4 preceding sentences to ensure robustness to different context lengths and allow contextless usage. To further improve models’ context sensitivity, we continue fine-tuning on the SCAT training split, containing 11k examples with inter- and intra-sentential pronoun anaphora.
| Model | SCAT+ | DiscEval-MT (ana) | DiscEval-MT (lex) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| bleu | ok | ok-cs | bleu | ok | ok-cs | bleu | ok | ok-cs | |
| Opus Small (def.) | 29.1 | 0.14 | - | 43.9 | 0.40 | - | 30.5 | 0.29 | - |
| Opus Small S+T\(_{\text{ctx}}\) | 39.1 | 0.81 | 0.59 | 48.1 | 0.60 | 0.24 | 33.5 | 0.36 | 0.07 |
| Opus Large (def.) | 29.0 | 0.16 | - | 39.2 | 0.41 | - | 31.2 | 0.31 | - |
| Opus Large S+T\(_{\text{ctx}}\) | 40.3 | 0.83 | 0.58 | 48.9 | 0.68 | 0.31 | 34.8 | 0.38 | 0.10 |
| mBART-50 (def.) | 23.8 | 0.26 | - | 33.4 | 0.42 | - | 24.5 | 0.25 | - |
| mBART-50 S+T\(_{\text{ctx}}\) | 37.6 | 0.82 | 0.55 | 49.0 | 0.62 | 0.32 | 29.3 | 0.30 | 0.07 |
Model Disambiguation Accuracy We estimate contextual disambiguation accuracy by verifying whether annotated (gold) context-sensitive words are found in model outputs. Results before and after context-aware fine-tuning are shown in Table 4.2. We find that fine-tuning improves translation quality and disambiguation accuracy across all tested models, with larger gains for anaphora resolution datasets that closely match the fine-tuning data. To gain further insight into these results, we use context-aware models to translate examples with and without context and identify a subset of context-sensitive translations (ok-cs) for which the correct target word is generated only when input context is provided to the model. Interestingly, we find a non-negligible amount of translations that are correctly disambiguated even in the absence of input context (corresponding to ok minus ok-cs in Table 4.2). For these examples, the correct prediction of ambiguous words aligns with model biases, such as defaulting to masculine gender for anaphoric pronouns (Stanovsky et al., 2019) or using the most frequent sense for word sense disambiguation. Provided that such examples are unlikely to exhibit context reliance, we focus particularly on the ok-cs subset results in our following evaluation.
4.4.2 Metrics for Context-sensitive Target Identification
The following contrastive metrics are evaluated for detecting context-sensitive tokens in the CTI step.
Relative Context Saliency We use contrastive gradient norm attribution (Yin and Neubig, 2022) to compute input importance towards predicting the next token \(\hat y_i\) with and without input context. Positive importance scores are obtained for every input token using the L2 gradient vectors norm (Bastings et al., 2022), and relative context saliency is obtained as the proportion between the normalized importance for context tokens \(c \in C_x, C_y\) and the overall input importance, following previous work quantifying MT input contributions (Voita et al., 2021; Ferrando et al., 2022a; Edman et al., 2024).
\[\nabla_\text{ctx} (P_\text{ctx}^{i}, P_\text{no-ctx}^{i}) = \frac{\sum_{c \in C_x, C_y} \big\| \nabla_c \big( P_\text{ctx}(\hat y_i) - P_\text{no-ctx}(\hat y_i) \big) \big\|}{\sum_{t \in X_\text{ctx}^{i}} \big\| \nabla_t \big( P_\text{ctx}(\hat y_i) - P_\text{no-ctx}(\hat y_i) \big) \big\|}\]
Likelihood Ratio (LR) and Pointwise Contextual Cross-mutual Information (P-CXMI) Proposed by Vamvas and Sennrich (2021a) and Fernandes et al. (2023), respectively, both metrics frame context dependence as a ratio of contextual and non-contextual probabilities.
\[\text{LR}(P_\text{ctx}^{i}, P_\text{no-ctx}^{i}) = \frac{P_\text{ctx}(\hat{y}_i)}{P_\text{ctx}(\hat{y}_i) + P_\text{no-ctx}(\hat{y}_i)}\]
\[\text{P-CXMI}(P_\text{ctx}^{i}, P_\text{no-ctx}^{i}) = - \log \frac{P_\text{ctx}(\hat{y}_i)}{P_\text{no-ctx}(\hat{y}_i)}\]
KL-Divergence (Kullback and Leibler, 1951) between \(P_\text{ctx}^{i}\) and \(P_\text{no-ctx}^{i}\) is the only metric we evaluate that considers the full distribution rather than the probability of the predicted token. We include it to test the intuition that the impact of context inclusion might extend beyond top-1 token probabilities.
\[D_\text{KL}(P_\text{ctx}^{i} \| P_\text{no-ctx}^{i}) = \sum_{\hat{y}_i \in \mathcal{V}} P_\text{ctx}(\hat{y}_i) \log \frac{P_\text{ctx}(\hat{y}_i)}{P_\text{no-ctx}(\hat{y}_i)}\]
4.4.3 Plausibility Evaluation Metrics
In practice, the CTI and CCI steps in PECoRe produce a sequence of continuous scores that are later binarized using selectors \(s_\text{cti}, s_\text{cci}\), introduced in Section 4.3. To evaluate their validity, those are compared to a sequence \(I_h\) of the same length containing binary values, where 1s correspond to the cues identified by human annotators, while the rest are set to 0. In our experiments, we use two standard plausibility metrics introduced by DeYoung et al. (2020):
Token-level Macro F1 is the harmonic mean of precision and recall at the token level, using \(I_h\) as the ground truth and the post-selector binarized scores as predictions. Macro-averaging is used to account for the sparsity of cues in \(I_h\). We use this metric in our primary analysis, as the discretization step is more likely to reflect realistic plausibility performance, since it matches more closely the annotation process used to derive \(I_h\). We note that Macro F1 can be considered a lower bound for plausibility, as the results depend heavily on the choice of the selector used for discretization.
Area Under Precision-Recall Curve (AUPRC) is computed as the area under the curve obtained by varying a threshold over token importance scores and computing the precision and recall for resulting discretized \(I_m\) predictions while keeping \(I_h\) as the ground truth. Contrary to Macro F1, AUPRC is selector-independent and accounts for tokens’ relative ranking and degree of importance. Consequently, it acts as an upper bound for plausibility, as if the optimal selector was used. Results using AUPRC are presented in Section A.2.2 for completeness, but we focus on Macro F1 in the primary analysis.
4.4.4 CTI Plausibility Results
Figure 4.3 presents our metrics evaluation for CTI, with results for the full test sets and the subsets of context-sensitive sentences (ok-cs) highlighted in Table 4.2. To keep our evaluation simple, we use a naive \(s_\text{cti}\) selector tagging all tokens with metric scores one standard deviation above the per-example mean as context-sensitive. We also include a stratified random baseline matching the frequency of occurrence of context-sensitive tokens in each dataset. Datapoints in Figure 4.3 are sentence-level macro F1 scores computed for every dataset example.
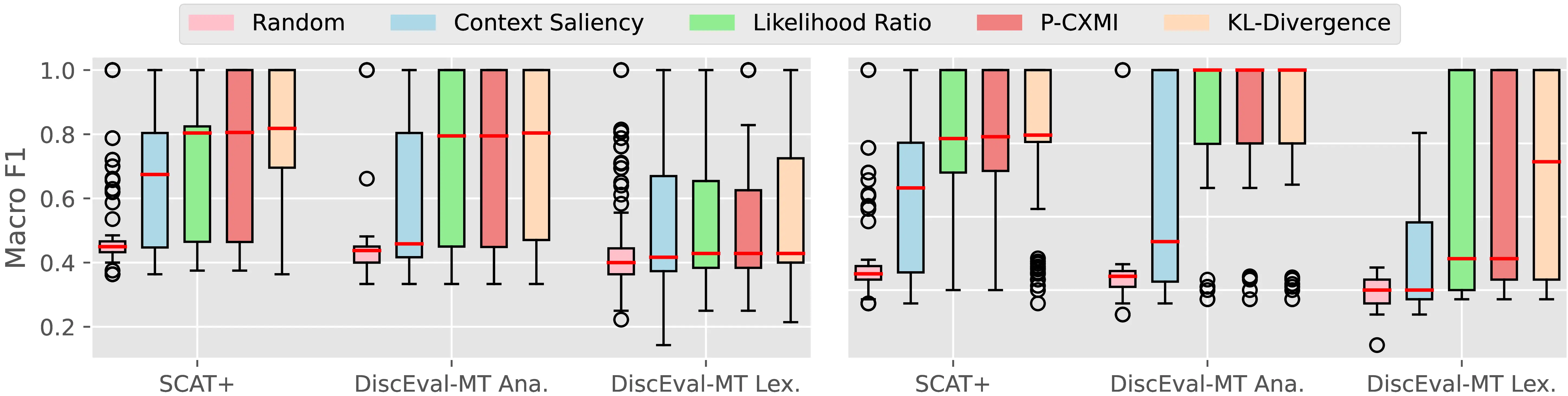
Pointwise metrics (LR, P-CXMI) show high plausibility for the context-sensitive subsets ok-cs across all datasets and models, but achieve lower performances on the full test set, especially for lexical choice phenomena less present in MT models’ training. KL-Divergence performs on par with or better than pointwise metrics, suggesting that distributional shifts beyond top prediction candidates can provide helpful information for detecting context sensitivity. On the contrary, the poor performance of context saliency suggests that aggregate context reliance cannot reliably predict context sensitivity. A manual examination of misclassified examples reveals several context-sensitive tokens that were not annotated as such, as they did not match the dataset’s phenomena of interest, but were still identified by CTI metrics. Table 4.3 presents several examples illustrating the contextual influence of French pronoun formality, whereas SCAT+ examples focus solely on gender disambiguation for anaphoric pronouns. This suggests that our evaluation of CTI metrics’ plausibility can be considered a lower bound for actual method accuracy, as it is restricted to the two phenomena available in the datasets we used (anaphora resolution and lexical choice), rather than the broad set of contextual dependence phenomena. These results further underscore the importance of data-driven, end-to-end approaches like PECoRe in limiting the influence of selection bias during evaluation.
| Pronoun Grammatical Formality, SCAT+ |
| \(C_x\): […] That demon that was in you, it wants you. But not like before. I think it loves you. |
| \(C_y\): […] Ce démon qui était en vous, il vous veut. Mais pas comme avant. Je pense qu’il vous aime. |
| \(x\): And it’s powerless without you. |
| \(y\): Et il est impuissant sans vous (you, 2nd p. plur., formal). |
| \(C_x\): You threaten my father again, I’ll kill you myself… on this road. You hear me? |
| \(C_y\): Tu menaces encore mon père, je te tuerai moi-même… sur cette route. Tu m’entends? |
| \(x\): Now it is with you as well. |
| \(y\): Maintenant elle est aussi avec toi (you, 2nd p. sing., informal). |
| \(C_x\): She went back to Delhi. What do you think? […] Girls, I tell you. |
| \(C_y\): Elle est revenue à Delhi. Qu’en penses-tu? […] Les filles, je te le dis. |
| \(x\): I wish they were all like you. |
| \(y\): J’aimerais qu’elles soient toutes comme toi (you, 2nd p. sing., informal). |
4.4.5 Methods for Contextual Cues Imputation
The following attribution methods are evaluated for detecting contextual cues in the CCI step.
Contrastive Gradient Norm (Yin and Neubig, 2022) estimates the input tokens’ contributions towards predicting a target token, rather than a contrastive alternative. We use this method to explain the generation of context-sensitive tokens in the presence and absence of context.
\[A_{t\,\text{ctx}} = \{\,\| \nabla_c \big(f_\text{tgt}(P_\text{ctx}^{i}, \dots) \big)\|\,|\, \forall c \in C\}\]
For the choice of \(f_\text{tgt}\), we evaluate both probability difference \(P_\text{ctx}(\hat y_i) - P_\text{no-ctx}(\hat y_i)\), conceptually similar to the original formulation, and the KL-Divergence of contextual and non-contextual distributions \(D_\text{KL}(P_\text{ctx}^{i} \| P_\text{no-ctx}^{i})\). We use \(\nabla_\text{diff}\) and \(\nabla_\text{KL}\) to identify gradient norm attribution in the two settings. \(\nabla_\text{KL}\) scores can be seen as the contribution of input tokens towards the shift in probability distribution caused by the presence of input context.7
Attention Weights Following previous work, we use the mean attention weight across all heads and layers (Attention Mean, Kim et al. (2019)) and the weight for the head obtaining the highest plausibility per-dataset (Attention Best, Yin et al. (2021)) as importance measures for CCI. Attention Best can be seen as a best-case estimate of attention performance but is not a viable metric in real settings, provided that the best attention head to capture a phenomenon of interest is unknown beforehand. Since attention weights are model byproducts unaffected by predicted outputs, we use only attention scores for the contextual setting \(P_\text{ctx}^{i}\) and ignore the contextless alternative when using these metrics.
4.4.6 CCI Plausibility Results
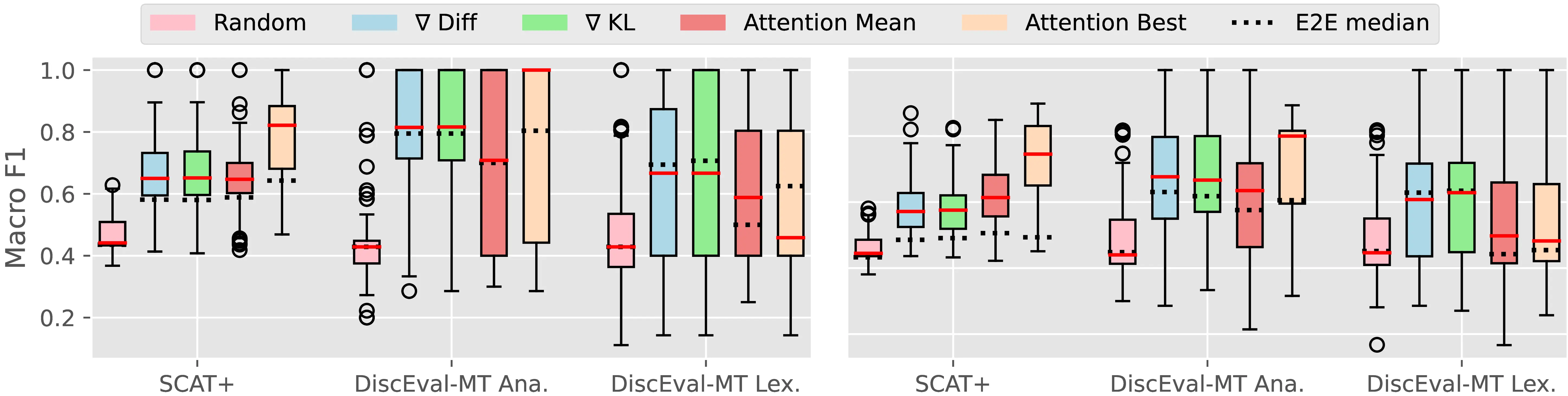
We conduct a controlled CCI evaluation using gold context-sensitive tokens as the starting point to attribute contextual cues. Provided that gold context-sensitive tokens are only available in annotated reference translations, a simple option when applying CCI to those would involve using references as model generations. However, this was shown to be problematic by previous research, as it would induce a distributional discrepancy in model predictions (Vamvas and Sennrich, 2021b). For this reason, we let the model generate a natural translation and instead try to align tags to this new sentence using the awesome aligner (Dou and Neubig, 2021) with labse multilingual embeddings (Feng et al., 2022). While this process is not guaranteed to always result in accurate tags, it provides a good approximation of gold CTI annotations for model generation, which is suitable for our assessment. This corresponds to the baseline plausibility evaluation described in Section 2.2.2, allowing us to evaluate attribution methods in isolation, assuming perfect identification of context-sensitive tokens. Figure 4.4 presents our results. Scores in the right plot are relative to the context-aware Opus Large model of Section 4.4.4 using both source and target context. Instead, the left plot presents results for an alternative version of the same model that was fine-tuned using only the source context (i.e., translating \(C_x, x \rightarrow y\) without producing the target context \(C_y\)). Source-only context was used in previous context-aware MT studies (Fernandes et al., 2022), and we include it in our analysis to assess how the presence of target context impacts model plausibility. We finally validate the end-to-end plausibility of PECoRe-detected pairs using context-sensitive tokens identified by the best CTI metric from Section 4.4.4 (KL-Divergence) as the starting point for CCI, and using a simple statistical selector equivalent to the one used for CTI evaluation.
First, contextual cues are more easily detected for the source-only model using all evaluated methods. This finding corroborates previous evidence highlighting how context usage issues might emerge when lengthy context is provided (Fernandes et al., 2021; Shi et al., 2023). When moving from gold CTI tags to the end-to-end setting (E2E) we observe a larger drop in plausibility for the SCAT+ and DiscEval-MT ana datasets that more closely match the fine-tuning data of analyzed MT models. This suggests that standard evaluation practices may overestimate model plausibility for in-domain settings and that our proposed framework can effectively mitigate this issue. Interestingly, the Attention Best method suffers the most from end-to-end CCI application, while other approaches are more mildly affected. This can result from attention heads failing to generalize to other discourse-level phenomena at test time, providing further evidence of the limitations of attention as an explanatory metric (Jain and Wallace, 2019; Bastings and Filippova, 2020). While \(\nabla_\text{diff}\) and \(\nabla_\text{KL}\) appear as the most robust choices across the two datasets, per-example variability remains high across the board, leaving space for improvement for more plausible attribution methods in future work.
4.5 Detecting Context Reliance in the Wild
We continue our analysis by applying the PECoRe method to the popular Flores-101 MT benchmark (Goyal et al., 2022), containing groups of 3-5 contiguous sentences from English Wikipedia. While previous sections used labeled examples to evaluate the effectiveness of PECoRe components, here we apply our framework end-to-end to unannotated MT outputs and inspect the resulting cue-target pairs to identify the successes and failures of context-aware MT models.
Specifically, we apply PECoRe to the context-aware Opus Large and mBART-50 models of Section 4.4.1, using KL-Divergence as CTI metric and \(\nabla_\text{KL}\) as CCI attribution method. We set \(s_\text{cti}\) and \(s_\text{cci}\) to two standard deviations above the per-example average score to focus our analysis on very salient tokens.
| 1. Acronym Translation (English → French, correct but more generic) |
| \(C_x\): Across the United States of America, there are approximately 400,000 known cases of Multiple Sclerosis (MS) […] |
| \(C_y\): Aux États-Unis, il y a environ 400 000 cas connus de sclérose en plaques […] |
| \(x\): MS affects the central nervous system, which is made up of the brain, the spinal cord and the optic nerve. |
| \(\tilde y\): La SEP affecte le système nerveux central, composé du cerveau, de la moelle épinière et du nerf optique. |
| \(\hat y\): La maladie affecte le système nerveux central, composé du cerveau, de la moelle épinière et du nerf optique. |
| 2. Anaphora Resolution (English → French, incorrect) |
| \(C_x\): The terrified King and Madam Elizabeth were forced back to Paris by a mob of market women. |
| \(C_y\): Le roi et Madame Elizabeth ont été forcés à revenir à Paris par une foule de femmes du marché. |
| \(x\): In a carriage, they traveled back to Paris surrounded by a mob of people screaming and shouting threats […] |
| \(\tilde y\): Dans une carriole, ils sont retournés à Paris entourés d’une foule de gens hurlant et criant des menaces […] |
| \(\hat y\): Dans une carriole, elles sont retournées à Paris entourées d’une foule de gens hurlant et criant des menaces […] |
| 3. Numeric format cohesion (English → French, incorrect) |
| \(C_x\): The game kicked off at 10:00am with great weather apart from mid morning drizzle […] |
| \(C_y\): Le match a commencé à 10:00 du matin avec un beau temps à part la nuée du matin […] |
| \(x\): South Africa started on the right note when they had a comfortable 26-00 win against Zambia. |
| \(\tilde y\): L’Afrique du Sud a commencé sur la bonne note quand ils ont eu une confortable victoire de 26 contre le Zambia. |
| \(\hat y\): L’Afrique du Sud a commencé sur la bonne note quand ils ont eu une confortable victoire de 26:00 contre le Zambia. |
| 4. Lexical cohesion (English → Turkish, correct) |
| \(C_x\): The activity of all stars in the system was found to be driven by their luminosity, their rotation, and nothing else. |
| \(C_y\): Sistemdeki bütün ulduzların faaliyetlerinin, parlaklıkları, rotasyonları ve başka hiçbir şeyin etkisi altında olduğunu ortaya çıkardılar. |
| \(x\): The luminosity and rotation are used together to determine a star’s Rossby number, which is related to plasma flow. |
| \(\tilde y\): Parlaklık ve döngü, bir akışıyla ilgili Rossby sayısını belirlemek için birlikte kullanılıyor. |
| \(\hat y\): Parlaklık ve rotasyon, bir akışıyla ilgili Rossby sayısını belirlemek için birlikte kullanılıyor. |
Table 4.4 and Table 4.5 show some examples annotated with PECoRe outputs. In the first example, the acronym MS, standing for Multiple Sclerosis, is translated generically as la maladie (the illness) in the contextual output, but as SEP (the French acronym for MS, i.e. sclérose en plaques) when context is not provided. PECoRe shows how this choice is mostly driven by the MS mention in source context \(C_x\) while the term sclérose en plaques in target context \(C_y\) is not identified as influential, possibly motivating the choice for the more generic option.
In the second example, the prediction of pronoun elles (they, feminine) depends on the context noun phrase mob of market women (foule de femmes du marché in French). However, the correct pronoun referent is Le roi et Madame Elizabeth (the king and Madam Elizabeth), so the pronoun should be the masculine default ils, commonly used for mixed-gender groups in French. PECoRe identifies this as a context-dependent failure due to an issue with the MT model’s anaphora resolution.
The third example presents an interesting case of erroneous numeric format cohesion that would typically go undetected when relying on pre-defined linguistic hypotheses. In this sentence, the score 26-00 is translated as 26 in the contextless output and as 26:00 in the context-aware translation. The 10:00 time indications found by PECoRe in the contexts suggest this is a case of problematic lexical cohesion.
Finally, we include an example of context usage for English\(\rightarrow\)Turkish translation to test the contextual capabilities of the default mBART-50 model without context-aware fine-tuning. Again, PECoRe shows how the word rotasyon (rotation) is selected over döngü (loop) as the correct translation in the contextual case due to the presence of the lexically similar word rotasyonları in the previous context.
4.6 Integrating PECoRe in Inseq
To facilitate the use of PECoRe in future research, a flexible implementation of the framework was incorporated into the Inseq toolkit presented in Chapter 3. Since its v0.6.0 Inseq offers the CLI command attribute-context, supporting all contrastive step functions and attribution methods in the library, and compatible with any decoder-only and encoder-decoder generative language model. Figure 4.5 provides an example employing the Inseq API to attribute a language model answer to input context paragraphs, similarly to the retrieval-augmented generation task we discuss in Chapter 5.8 In the example, the StableLM 2 Zephyr 1.6B language model9 is prompted with contexts retrieved from Wikipedia to provide a long-form answer to a query about population in the Hawaiian islands. When referring to “the information provided” in ⓵, PECoRe identifies the indices of the two documents containing relevant information as salient. The name of Ni’ihau, a small island with barely any population, is also found important when the model produces an additional remark on their population in ⓶. However, we observe that the answer in the context is not identified as salient by PECoRe during generation, suggesting that the model might be relying on memorization. We test the hypothesis by prompting the model in a closed-book setting without context paragraphs, finding that the model can indeed respond correctly without context. Moreover, as expected, the island of Ni’ihau is never mentioned in the contextless response. Additional examples of PECoRe usage for other generation tasks are provided in Section A.2.3.

4.7 Conclusion
We introduced PECoRe, a novel interpretability framework for detecting and attributing context usage in language models’ generations. PECoRe extends the standard plausibility evaluation procedure adopted in interpretability research by proposing a two-step procedure to identify context-sensitive generated tokens and match them to contextual cues contributing to their prediction. We applied PECoRe to context-aware MT, finding that context-sensitive tokens and their disambiguating rationales can be detected consistently and with reasonable accuracy across several datasets, models and discourse phenomena. Moreover, an end-to-end application of our framework without human annotations revealed incorrect context usage, leading to problematic MT model outputs.
While our evaluation is mainly focused on the machine translation domain, thanks to its generality and its integration in the Inseq framework PECoRe can easily be applied to other context-dependent language generation tasks such as question answering and summarization, as also demonstrated in the previous section. Future applications of our methodology could investigate the usage of in-context demonstrations and chain-of-thought reasoning in large language models (Brown et al., 2020; Wei et al., 2022), and explore PECoRe usage for different model architectures and input modalities. In the next chapter, we extend PECoRe for attributing context usage in retrieval-augmented generation tasks, where the model is expected to rely on external knowledge sources to produce answers to user queries.
We avoid using the term faithfulness due to its ambiguous usage in interpretability research.↩︎
In the contextual MT example of Figure 4.2, \(C\) includes source context \(C_x\) and target context \(C_y\).↩︎
We use \(m^i\) to denote the result of \(m(P_\text{ctx}^{i}, P_\text{no-ctx}^{i})\). Several metrics are presented in Section 4.4.2.↩︎
SCAT+ is available on the Hugging Face Hub:
inseq/scat↩︎Our modified version of DiscEval-MT is available on the Hugging Face Hub:
inseq/disc_eval_mt.↩︎Provided that \(P_\text{no-ctx}(\hat y_i)\) does not depend on context, the \(\nabla_\text{KL}\) gradient is functionally equivalent to the gradient for the cross-entropy function \(H(P_\text{ctx}, P_\text{no-ctx}) = - \sum_{\hat{y}_i \in \mathcal{V}} P_\text{ctx}(\hat{y}_i) \log P_\text{no-ctx}(\hat{y}_i)\)).↩︎
The interface is available at: https://huggingface.co/spaces/gsarti/pecore.↩︎