1 Linguistic Complexity
Defining linguistic complexity in a univocal way is challenging, despite the subjective intuition that every individual may have about what should be deemed complex in written or spoken language. Indeed, if the faculty of language allows us to produce a possibly infinite set of sentences from a finite vocabulary, there are infinitely many ways in which a sentence may appear difficult to a reader’s eyes. An accurate definition is still debated in research fields like cognitive science, psycholinguistics, and computational linguistics. Nonetheless, it is indisputable that the concept of natural language complexity is closely related to difficulties in knowledge acquisition. This property stands both for human language learners and for computational models learning the distributional behavior of words in a corpus.
This introductory chapter begins with a categorization of linguistic complexity annotations following taxonomical definitions found in the literature. Various complexity metrics are then introduced alongside corpora and resources that were used throughout this study. Finally, the focus will be put on garden-path sentences, peculiar syntactically-ambiguous constructs studied in the experiments of Chapter 5.
1.1 Categorizing Linguistic Complexity Measures
In modern literature about linguistic complexity, two positions, each trying to define the nature of linguistic complexity phenomena, can be identified. In Kusters (2008) words:
On the one hand, complexity is used as a theory-internal concept, or linguistic tool, that refers only indirectly, by way of the theory, to language reality. On the other hand, complexity is defined as an empirical phenomenon, not part of, but to be explained by a theory.
These definitions are coherent with the absolute and relative complexity terminology coined by Miestamo (2004), where relative complexity is seen as a factor characterizing the perceptual experience of specific language users. In contrast, absolute complexity is structurally-defined by language constructs and independent from user evaluation. While these two perspectives seem to identify two opposite viewpoints over linguistic complexity, the distinction between the two becomes blurred when we consider that linguistic theories underlying absolute complexity evaluation are developed by linguists, who still have a subjective perspective despite their competence (Kusters 2003). Two definitions are now introduced to operationalize absolute and relative complexity in the context of complexity measurements:
Intrinsic Perspective The intrinsic perspective on linguistic complexity is closely related to the notion of absolute complexity. From the intrinsic viewpoint, language productions are evaluated using their distributional and structural properties, without any complexity annotation derived by language users. The linguistic system is characterized by a set of elementary components (lexicon, morphology, syntax inter alia) that interact hierarchically (Cangelosi and Turner 2002), and their interactions can be measured in terms of complexity by fixing a set of rules and descriptions. The focus is on objectivity and automatic evaluation based on the intrinsic properties of language systems.
Extrinsic Perspective The extrinsic perspective connects to the concept of relative complexity and takes into account the individual perspective of users. Complexity judgments are collected during or after the processing of linguistic productions and are then evaluated in terms of cognitive effort required by language users for comprehension. The extrinsic viewpoint is partaken by cognitive processing theories in psycholinguistics such as the Dependency Locality Theory (Gibson 1998, 2000), the Surprisal Theory (Hale 2001, 2016; Levy 2008), and the more recent Lossy-context Surprisal Theory (Futrell, Gibson, and Levy 2020), aiming to disentangle the source of processing difficulties in sentence comprehension. The focus, in this case, is on the subjectivity of language users and their judgments.
Despite being different under many aspects, the two perspectives are highly interdependent: a user’s perception of complexity will be strongly influenced by the distributional and structural properties of utterances, and some of those properties will be considered complex in relation to the type of judgments they typically elicit in language users. Provided that the strength of human influence in complexity measurements can vary widely depending on data collection procedures, the two perspectives can be seen as the two ends of a spectrum. A visual representation is provided by the horizontal axis of the complexity measures compass in Figure 1.1.
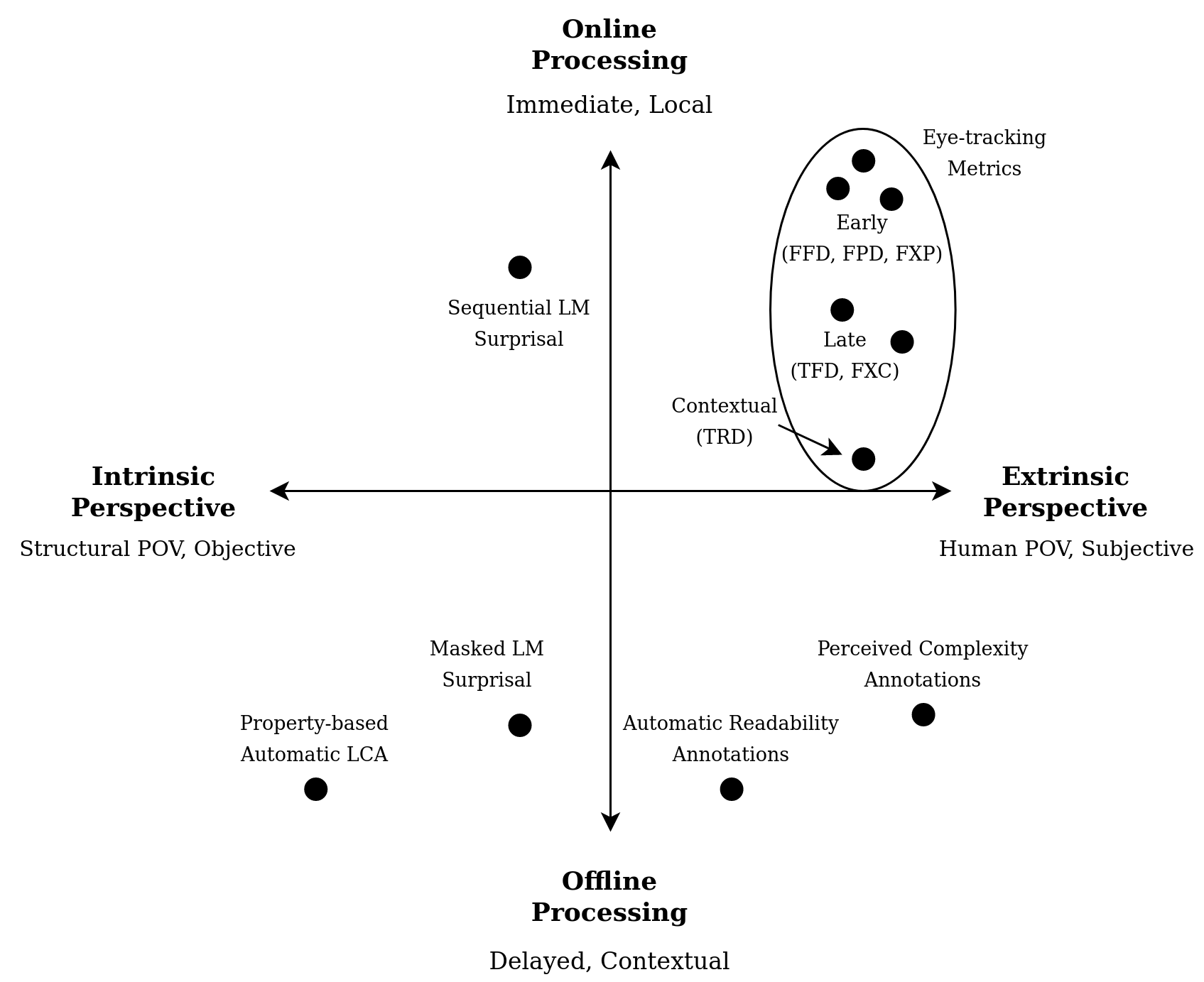
Figure 1.1: Complexity measures’ compass.
An additional dimension for categorizing linguistic complexity metrics can be introduced by considering the time at which measures are obtained, relative to the incremental processing paradigm that characterizes natural reading in human subjects. In this context, processing is defined as any act aimed at extracting information from linguistic forms and structures, either by employing reasoning (in humans) or through computation (in automatic systems). Again, we can identify the two ends of a spectrum concerning processing modalities, related to the concepts of local and global complexity found in linguistic literature (Edmonds 1999; Miestamo 2004, 2008):
Online processing Online complexity judgments are collected while a language user, be it a human subject or a computational system, is sequentially processing a text. Online processing is widely explored in the cognitive science literature, where behavioral metrics such are fMRI data and gaze recordings are collected from subjects exposed to locally and temporally-immediate inputs and tasks that require fast processing (Iverson and Thelen 1999). The act of reading is predominantly performed by online cognition (Meyer and Rice 1992), making online measures especially suitable for complexity evaluation for natural reading.
Offline processing Offline complexity judgments are collected at a later time when the language user has a complete and contextual view of the text in its entirety. Again, offline complexity is related to the offline cognition paradigm (Day 2004) typically used in re-evaluations and future planning. In practice, offline evaluation accounts for contextual and cultural factors closely related to individual subjectivity and is poorly captured by immediate online metrics.
Figure 1.1 situates various linguistic complexity metrics in terms of processing modalities and analyzed perspective by including the processing spectrum on the vertical axis. In the next sections, all these measures will be introduced and their use will be motivated in light of this categorization.
1.2 Intrinsic Perspective
Complexity studies where the intrinsic point of view is adopted rely on annotations describing linguistic phenomena and structures in sentences and aim to map those to complexity levels or ratings, often resorting to formulas parametrized through empirical observation. Given the scarcity of experienced human annotators and the cost of a manual annotation process, computational systems have been primarily employed to extract linguistic information from raw text in an automated yet precise way.
Another intrinsic viewpoint is based on the intuition that frequent constructs should be deemed as less complex than infrequent ones. In this case, terms’ co-occurrences are extracted from large corpora, and complexity judgments are derived from their probabilistic likelihood of appearance in a given context. Given the infeasibility of tracking co-occurrences for long sequences in large, typologically-varied corpora, computational language models are usually employed to learn approximations of co-occurrence likelihoods for specific constructs.
While this thesis work only partially addresses the use of these approaches, they will be briefly introduced to provide additional context for understanding extrinsic perspectives and their experimental evaluation.
1.2.1 Structural Linguistic Complexity
Language systems can be seen as hierarchies of rules and processes governing various aspects of utterances production and use. For each of those levels, it is possible to identify characteristics leading to higher complexity from a structural standpoint (Sinnemäki 2011):
A greater number of parts in a specific language level leads to a greater syntagmatic complexity (also known as constitutional complexity). This mode is related to the lexical and “superficial” properties of language, such as the length of words and sentences.
A greater variety of parts in a specific language level leads to a greater paradigmatic complexity (also known as taxonomic complexity). This mode characterizes, in particular, the phonological level, where the presence of an elaborated tonal system makes a language more complex (McWhorter 2001), the morphologic level, where inflectional morphology is usually associated to a higher degree of complexity (McWhorter 2001; Kusters 2003) when compared to the regularity of derivational rules, and the semantic level, where polysemic words are generally considered more complex than monosemic ones (Voghera 2001).
A greater variety of interrelation modalities and hierarchical structures leads to greater organizational and hierarchical complexities. Those complexity modes are mainly related to the syntactic level, where recursive and nested constructs are deemed more complex and possibly determinant in distinguishing human language from animal communication (Hauser, Chomsky, and Fitch 2002).
Focusing on the syntactic level, we can find multiple factors accounting for greater complexity (Berruto and Cerruti 2011):
Subordinate clauses preceding the main clause, as in If you need help, let me know" as opposed to “Let me know if you need help”.
Presence of long-range syntactic dependencies between non-contiguous elements, as in “The dog that the cat chased for days ran away” where the subject referent (dog) and its verb (ran) are far apart in the sentence.
A high degree of nesting between elements and substructures, as in “The mouse that the cat that the dog bit ate was bought at the fair” where two nested subordinate clauses introduced by the preposition that are present.
Repeated applications of recursive principles to build utterances with different meanings through the compositionality principle, as in “I am a huge fan of fans of fans of … of recursion”, where the number of recursions defines the final meaning of the sentence.
While all those properties are relevant when evaluating an utterance’s complexity, only some can be easily extracted from corpora using automatic approaches. In the specific context of this work, the analysis of complexity-related features in Chapter 3 makes use of the Profiling–UD tool2 (Brunato et al. 2020), implementing a two-stage process: first, the linguistic annotation process is automatically performed by UDPipe (Straka, Hajič, and Straková 2016), a multilingual pipeline leveraging neural parsers and taggers included in the Universal Dependencies initiative (Nivre et al. 2016). During this step, sentences are tokenized, lemmatized, POS-tagged (i.e., words are assigned lexical categories such as “Noun” and “Verb”) and parsed (i.e., the hierarchical structure of syntactic dependencies is inferred). Then, a set of about 130 linguistic features representing underlying linguistic properties of sentences is extracted from various levels of annotation. Those features account for multiple morphological, syntactic, and “superficial” properties related to linguistic complexity. A relevant subset of those features is presented in detail in Appendix A.
After deriving linguistic properties from sentences, either automatically as in this study or by manual annotations, two approaches are viable to determine their complexity while maintaining an intrinsic perspective (no human processing data involved):
Formula-based Approach This approach treats linguistic properties of input texts as components of a formula used to determine levels or readability grades. Traditional readability formulas consider multiple factors, such as word length, sentence length, and word frequency. Parameters in those formulas are carefully hand-tuned to match human intuition and correlate well with human-graded readability levels.3
Learning-based Approach This approach casts the complexity prediction problem in the supervised machine learning framework. More specifically, linguistic parsers are used to predict linguistic properties, and their accuracy on a set of gold-labeled instances is taken as an indicator of complexity. In the case of dependency parsers (i.e., models trained to extract the syntactic structure of a sentence), two evaluation metrics can be used: the Unlabeled and Labeled Attachment Scores (UAS and LAS), where the UAS is the percentage of words assigned to the right dependency head and LAS also consider if the dependency relation was labeled correctly.
Both approaches are represented in Figure 1.1 under the label “Property-based Automatic LCA” and are considered offline since the text is generally not processed incrementally but instead taken as a whole.
1.2.2 Language Modeling Surprisal
The information-theoretic concept of surprisal, also known as information content of an event, can be seen as a quantification of the level of surprise caused by a specific outcome: an event that is certain yields no information, while the less probable an event is, the more surprising it gets. Formally, an event \(x\) with probability \(p(x)\) has a surprisal value equal to:
\[\begin{equation} I(x) = - \log[p(x)] \end{equation}\]
The idea that probabilistic expectations in the context of language reading are related to greater complexity in terms of cognitive processing was formalized by surprisal theory (Hale 2001, 2016). Surprisal theory defines processing difficulties \(D\) (which can be considered as proxies of complexity) as directly proportional to the surprisal produced in readers by a word \(w\) given its previous context \(c\) (i.e., preceding words in the sentence):
\[\begin{equation} D(w_i|c) \propto -\log p(w_i|c) = -\log p(w_i|w_i-1, w_i-2,\dots, w_0) \end{equation}\]
While processing difficulties imply human subjects’ presence, language models (LM) can be used to estimate the conceptually similar information-theoretic surprisal without the need of human annotations by learning word occurrences and co-occurrences probabilities from large quantities of text. Concretely, a language model is a probabilistic classifier that learns to predict a probability distribution over words of a vocabulary \(V\) given a large number of contexts \(c\) in which those words occur (Goodman 2001):
\[\begin{equation} p(w_i|c) \quad \forall\ w_i\in V \end{equation}\]
After the training procedure it is possible to estimate the probability \(p(s)\) of a sentence \(s\) having length \(m\) as the product of the conditional probabilities assigned to individual words by the language model, given its context:
\[\begin{equation} p(s) = p(w_1, \dots, w_m) = \prod_{i=1}^m p(w_i \ |c) \tag{1.1} \end{equation}\]
We can consider the surprisal \(I(s) = -\log p(s)\) as an intrinsic measure of linguistic complexity since it is a function of the co-occurrence relations derived by the training corpora. Thus, it describes how likely a construct can be observed in a structurally-sound manner, without relying on human processing data. However, automatic surprisal estimation using language models cannot be considered purely intrinsic since it is highly dependent on a multitude of factors that are arguably “less objective” than the linguistic categories of the previous section, such as the type and dimension of the considered context and the corpora employed by the LM to learn words’ distributional behavior.
We can categorize modern language models in two broad categories: sequential models (also known as autoregressive or causal LMs) consider as context only preceding words, while bidirectional models (also known as masked LMs) consider both preceding and following words when estimating occurrence probabilities, much like the well-established cloze test (Taylor 1953) in psycholinguistics. Equations (1.2) show how the sentence surprisal equation (1.1) is adapted in both cases, using the product rule for logarithms:
\[\begin{equation} \begin{split} I_{\mathrm{sequential}}(s) & = - \sum_{i=1}^m \log p(w_i \ | w_1, w_2, \dots, w_{i-1})\\ I_{\mathrm{bidirectional}}(s) & = - \sum_{i=1}^m \log p(w_i \ | w_1, \dots, w_{i-1}, w_{i+1}, \dots, w_m) \end{split} \tag{1.2} \end{equation}\]
If the LM used to estimate surprisal was sequential, then surprisal estimation could be considered part of the online processing paradigm despite the absence of a human subject.4 In the bidirectional case, the estimation of surprisals from the whole context can be assimilated with offline processing practices.
The relation between co-occurrence frequencies estimated by a language model and perception of complexity is one of the aspects that make language models especially suitable for predicting extrinsic complexity metrics, as it will be discussed in Chapter 2.
1.3 Extrinsic Perspective
Extrinsic complexity measures elicited from human-produced signals and annotations are the main focus of this thesis work. In this section, three different viewpoints on linguistic complexity assessment from a human perspective are introduced:
The readability point-of-view, as intended in the context of the automatic readability assessment (ARA) task, is concerned with collocating similar textual inputs into difficulty levels that are often predetermined by writers and given a clear semantic interpretation (e.g., easy, medium, hard).
The perceptual point-of-view, represented by the perceived complexity prediction (PCP) task, is based on human annotations of complexity on a numeric scale, taking into account disparate textual inputs presented sequentially to obtain more generalizable complexity annotations. Unlike ARA, PCP annotations are produced by readers after sentence comprehension.
The cognitive point-of-view, employing cognitive signals collected by specialized machinery (e.g., electrodes, MRI scanners, eye-trackers) as proxies for the linguistic complexity experienced by users. In this work, the focus will be on the gaze metrics prediction task, using gaze data collected from subjects during natural reading.
All three complexity-related tasks will be introduced alongside recent results in the literature. The corpora on which each task relies upon will also be presented in their respective sections.
1.3.1 Automatic Readability Assessment
While the term readability assessment is often broadly employed to denote the task of predicting the general reading difficulty of a text, here it is used to describe the typical approach in ARA, relying on corpora categorized by the writer’s perception of what is difficult for readers.
We can take as an example the OneStopEnglish (OSE) corpus (Vajjala and Lučić 2018), which will be used later to study the ARA relation with other complexity tasks in Chapter 4. OSE contains 567 weekly articles from The Guardian newspaper rewritten by language teachers to suit three adult English learners’ levels. Each text can be divided into passages spanning one or multiple sentences, each labeled with a readability level (“Elementary”, “Intermediate” or “Advanced”) based on the original writers’ judgment. An example of the same passage at different reading levels is provided in Table 1.1.
| Reading Level | Example |
|---|---|
| Advanced (Adv) | Amsterdam still looks liberal to tourists, who were recently assured by the Labour Mayor that the city’s marijuana-selling coffee shops would stay open despite a new national law tackling drug tourism. But the Dutch capital may lose its reputation for tolerance over plans to dispatch nuisance neighbours to scum villages made from shipping containers. |
| Intermediate (Int) | To tourists, Amsterdam still seems very liberal. Recently the city’s Mayor assured them that the city’s marijuana-selling coffee shops would stay open despite a new national law to prevent drug tourism. But the Dutch capitals plans to send nuisance neighbours to scum villages made from shipping containers may damage its reputation for tolerance. |
| Elementary (Ele) | To tourists, Amsterdam still seems very liberal. Recently the city’s Mayor told them that the coffee shops that sell marijuana would stay open, although there is a new national law to stop drug tourism. But the Dutch capital has a plan to send antisocial neighbours to scum villages made from shipping containers, and so maybe now people wont think it is a liberal city any more. |
From Table 1.1 example, it is evident that the reading level of a specific text should be interpreted only in relation to its other versions, i.e., elementary passages are not necessarily straightforward in absolute terms, but rather less complicated than their intermediate and advanced counterparts. This affirmation holds for the OSE corpus and other widely-used readability corpora such as the Newsela corpus (Xu, Callison-Burch, and Napoles 2015), which contains newspaper articles rewritten by experts to match eleven school grade reading levels. For this reason, and because of its writer-centric perspective relying only on readability judgments formulated by the same writers who composed the passages, readability assessment is fundamentally different from the other extrinsic approaches.5 ARA can be framed as a machine learning task in which a computational model \(m\) is trained to predict the readability level \(y \in \mathcal{Y}\) over a set of labeled examples \(\mathcal{S} = (s_1, s_2, \dots, s_n)\) in two possible ways:
A simple multiclass classification setting, where the model predicts the level of a single sentence \(s\). In this case, the model outputs a prediction \(m(s) = \hat y \in \mathcal{Y}\). We can then minimize the categorical cross-entropy \(H(y, \hat y)\) between gold and predicted labels during the training process and evaluate the model’s performances with standard classification metrics such as precision and recall. This approach is similar to the ones used for other extrinsic metrics but does not account for readability levels’ relative nature.
A multiple-choice scenario, where the model is provided with two semantically equivalent sentences \(s_1, s_2\) at different readability levels (\(s_1 \equiv s_2, y_1 \neq y_2\)) and needs to predict which of the sentences has the highest readability level. In this case, which is more coherent with the relative nature of readability judgments, the model is trained to minimize the binary cross-entropy between gold and predicted labels \(y, \hat y \in \mathcal{Y}_{bin} = \{0,1\}\) corresponding to the position of the more complex sentence in the pair.
Expert annotations’ effectiveness in determining readers’ comprehension was recently questioned, as automatic readability scoring did not show a significant correlation to comprehension scores of participants, at least for the OSE Corpus (Vajjala and Lucic 2019). However, measuring if this observation holds for other corpora and extrinsic approaches is beyond this thesis’s scope.
1.3.2 Perceived Complexity Prediction
While ARA measures linguistic complexity in a context-relative and writer-centric sense, the perceived complexity prediction (PCP) approach focuses on eliciting absolute complexity judgments directly from target readers, aiming at evaluating difficulties in comprehension rather than production. This approach was pioneered by Brunato et al. (2018), who collected crowdsourced complexity ratings from native speakers for Italian and English sentences and evaluated how different structural linguistic properties contribute to human complexity perception. The use of annotators recruited on a crowdsourcing platform was intended to better grasp the layman’s perspective on linguistic complexity, as opposed to ARA expert writers. If collected properly, crowdsourced annotations were shown to be highly reliable for linguistics and computational linguistics research by the survey of Munro et al. (2010).
Brunato et al. (2018) extracted 1200 sentences from both the newspaper sections of the Italian Universal Dependency Treebank (IUDT) (Simi, Bosco, and Montemagni 2014) and the Penn Treebank (McDonald et al. 2013), such that those are equally distributed in term of length. To collect human complexity judgments, twenty native speakers were recruited for each language on a crowdsourcing platform. Annotators had to rate each sentence’s difficulty on a Likert 7-point scale, with 1 meaning “very simple” and 7 “very complex”. Sentences were randomly shuffled and presented in groups of five per web page, with annotators being given a minimum of ten seconds to complete each page to prevent skimming. The quality of annotations was measured using the Krippendorff alpha reliability, obtaining 26% and 24% for Italian and English. Table 1.2 presents an example of English sentences labeled with multiple annotators’ perceived complexity judgments.
| Sentence | A1 | A2 | A3 | … | A20 |
|---|---|---|---|---|---|
| In other European markets, share prices closed sharply higher in Frankfurt and Zurich and posted moderate rises in Stockholm, Amsterdam and Milan. | 4 | 6 | 7 | … | 1 |
| The pound strengthened to $ 1.5795 from $ 1.5765. | 2 | 1 | 2 | … | 1 |
| In Connecticut, however, most state judges are appointed by the governor and approved by the state legislature. | 1 | 3 | 3 | … | 5 |
| When the market stabilized, he added, the firm sold the bonds and quickly paid the loans back. | 2 | 3 | 3 | … | 3 |
| Paribas already holds about 18.7 % of Navigation Mixte, and the acquisition of the additional 48 % would cost it about 11 billion francs under its current bid. | 5 | 2 | 3 | … | 6 |
As can be expected, PC judgments show significant variability across participants since they cannot be easily framed in a relative setting. Since this work’s focus is related to a general notion of complexity, PC judgments are averaged and filtered to obtain a score reflecting the mean perception of complexity of all participants in experimental chapters. The averaged score is later treated as the gold label in a regression task, with machine learning models trained to minimize the mean square error between their predictions and gold average annotations. Another possibility, which is not explored in this thesis work, would be to consider only single participants’ judgments to model their linguistic complexity perception.
1.3.3 Gaze Metrics Prediction
Gaze data collected from human subjects during reading can provide us with useful insights from an online extrinsic complexity perspective. Patterns found in both saccades, i.e., eye movements from one location to another, and fixations, where eyes are relatively stable while fixating a specific region, were shown to be reliably linked to a multitude of linguistic factors (Demberg and Keller 2008). Because of this, a linking assumption between overt attention and mental processing can be reasonably established, and gaze metrics can be considered as proxies of cognitive effort, and thus of complexity, at various processing levels.6
Gaze metrics are widely employed in cognitive processing research because of their multiple benefits: optical eye-tracking systems are non-invasive and relatively inexpensive compared to other approaches that directly measure brain activity, such as electroencephalography (EEG) and all magnetic resonance imaging (MRI) variants. Moreover, gaze data generally have high spatial and temporal precision, limited only by sampling rates, which are generally in the order of few milliseconds. This aspect is crucial for reading research since it allows us to directly associate gaze measures to specific areas of interest (AOI, also called region), i.e., small portions of the visual input provided to participants.
Gaze data for NLP Eye-tracking data and other cognitive signals were effectively used in many NLP applications such as POS tagging (Barrett et al. 2016), sentiment analysis (Mishra, Dey, and Bhattacharyya 2017), native language identification (Berzak, Katz, and Levy 2018), and dependency parsing (Strzyz, Vilares, and Gómez-Rodríguez 2019) inter alia, often providing modest yet consistent improvements across models and tasks through the combination of gaze features and linguistic features or distributed representations.7 In the context of linguistic complexity assessment, eye-tracking data were applied to the ARA task for both monolingual and bilingual participants, obtaining meaningful results for sentence-level classification in easy and hard-to-read categories (Vasishth, Malsburg, and Engelmann 2013; Ambati, Reddy, and Steedman 2016). For example, Singh et al. (2016) first use a set of linguistic features to learn a reading times model from a set of gaze-annotated sentences and then use models’ predicted times over a second set of sentences to perform multiple-choice ARA. González-Garduño and Søgaard (2018) extend this approach in a multitask learning setting (Caruana 1997; Ruder 2017), using eye-movement prediction tasks to produce models able to predict readability levels both from a native speaker and foreign language learner perspective.
Collecting Eye-tracking Data A typical procedure to collect gaze data for reading research, as described by Schotter (2020), usually includes the following steps:
Textual inputs are selected and split by experiment designers, first in areas of interest directly mapped to pixels (for natural reading, usually word boundaries), then over multiple rows, and finally in screens presented to participants. This step should take into account calibration errors to determine the correct level of tolerance for off-word fixations.
A participant is placed in a room with a display computer used to present visual inputs and a host computer used to record data from the eye-tracker setup. Optical eye-trackers use infrared light beams, which are reflected differently by different parts of the eye, to measure pupil and corneal reflection and track gaze movements at each timestep. The setup is calibrated and validated for each participant to ensure the quality of results.
Each participant follows the on-screen instructions to complete a reading task trial while remaining at a fixed distance from the screen. A fixation report containing events (saccades, fixations, blinks) is produced for each individual on the host computer.
Finally, a data preprocessing step is taken for each trial to identify and remove artifacts and possibly decide to reject the trial. Some examples of standard practices are the merge of fixations below 80ms due to eye jittering, the exclusion of fixations caused by track loss after blinks, and vertical drift correction (Carr et al. 2020). An AOI report containing gaze metrics grouped at AOI level can be produced.
Eye-tracking Metrics Metrics derived from the AOI report contain information about the processing phases in which subjects incur during sentence comprehension. Early gaze measures capture information about lexical access and early processing of syntactic structures, while late measures are more likely to reflect comprehension and both syntactic and semantic disambiguation (Demberg and Keller 2008). The third kind of measures, referred to as contextual following the categorization in Hollenstein and Zhang (2019), capture information from surrounding content. Table 1.3 presents a subset of metrics, spanning the three categories, that will be used in the experimental section.8 These metrics represent a minimal group spanning various stages of the reading process and are leveraged to study differences between online and offline processing among extrinsic metrics. In the experimental part, gaze scores are often averaged across participants to reduce noise in measurements and obtain a single label for each metric that can later be used as a reference in a regression setting. The average fixation probability across participants for each AOI is a value comprised in the range \([0,1]\) and represents the proportion of subjects that accessed the region during their first gaze pass.
| Type | Metric Name | Description |
|---|---|---|
| Early | First Fixation Duration (FFD) | Duration of the first fixation over the region, including single fixations. |
| First Pass Duration (FPD) | Duration of the first pass over a region. | |
| Fixation Probability (FXP) | Boolean value reflecting if the region was fixated or skipped during the first pass. | |
| Late | Fixation Count (FXC) | Number of total fixations over a region. |
| Total Fixation Duration (TFD) | Sum of all fixation durations over a region. | |
| Contextual | Total Regression Duration (TRD) | Duration of regressive saccades performed after a region’s first access and before going past it. |
Eye-tracking Corpora The experimental part of this thesis work leverages four widely used eye-tracking resources: the Dundee corpus (Kennedy, Hill, and Pynte 2003), the GECO corpus (Cop et al. 2017), the ZuCo corpus (Hollenstein et al. 2018), and ZuCo 2.0 (Hollenstein, Troendle, et al. 2020). There are multiple reasons behind the choice of using multiple gaze-annotated corpora for this study. First, those corpora span different domains and provide us with a better intuition of what structures are perceived as complex in different settings and by different pools of subjects. Secondly, neural-network-based complexity models used in this work greatly benefit from a broader availability of annotated data to achieve higher performances in predicting eye-tracking metrics. Finally, while all corpora relied on different procedures and instrumentation, they are all derived from very similar experimental settings (i.e., natural reading on multiple lines), and can be easily merged after an individual normalization procedure (Hollenstein and Zhang 2019). Table 1.4 presents some descriptive statistics of the four corpora.
The Dundee Corpus developed by Kennedy, Hill, and Pynte (2003) contains gaze data for ten native English speakers tasked with reading twenty newspaper articles from The Independent. The English section of the Dundee corpus includes 51,240 tokens in 2368 sentences. Texts were presented to subjects on a screen five lines at a time and recorded using a Dr. Bois Oculometer Eyetracker with 1 kHz monocular (right) sampling. Dundee corpus data are the oldest among selected corpora and have been extensively used in psycholinguistic research about naturalistic reading.
The Ghent Eye-tracking Corpus (GECO) by Cop et al. (2017) was created more recently to study eye movements of both monolingual and bilingual subjects during naturalistic reading of the novel The Mysterious Affair at Styles by Agatha Christie (2003). In the context of this work, only the monolingual portion collected from 14 native English speakers is used, comprising 56,409 tokens in 5,387 sentences. Eye movements were recorded with an EyeLink 1000 system with 1 kHz binocular sampling (only right eye movements were considered), and the text was presented one paragraph at a time.
The Zurich Cognitive Language Processing Corpus (ZuCo) by Hollenstein et al. (2018) is a dataset including both eye-tracking and EEG measurements collected simultaneously during both natural and task-oriented reading. The corpus contains 1100 English sentences from the Stanford Sentiment Treebank (Socher et al. 2013) and the Wikipedia dump used in Culotta, McCallum, and Betz (2006) with gaze data for 12 adult native speakers. Only the first two portions are used for the present work since they contain natural reading data, totalizing 700 sentences and 13,630 tokens. The text was presented on-screen one sentence at a time, and data were collected with an EyeLink 1000 as for GECO.
ZuCo 2.0 is an extension of ZuCo, including 739 sentences extracted from the Wikipedia corpus by Culotta, McCallum, and Betz (2006). Only the 349 sentences for which natural reading data were collected are used, and the 100 duplicates shared with ZuCo to evaluate differences in setup and participants are removed. Data were collected from 18 native English speakers using an EyeLink 1000 Plus with 500 kHz sampling.
| Dundee | GECO | ZuCo | ZuCo 2.0 | Total | |
|---|---|---|---|---|---|
| domain(s) | news | literature | movie reviews, Wiki articles | Wiki articles |
|
| # of sentences | 2368 | 5387 | 700 | 349 | 8804 |
| mean sent. length | 21.64 | 10.47 | 19.47 | 19.51 | 17.77 |
| # of tokens | 51240 | 56409 | 13630 | 6810 | 128089 |
| unique token types | 9928 | 6155 | 4650 | 2521 | 16320 |
| mean token length | 4.88 | 4.6 | 5.05 | 5.01 | 4.89 |
| mean fix. duration | 200 | 210 | 117 | 117 | 161 |
| mean gaze duration | 280 | 234 | 139 | 134 | 197 |
Tokens are obtained using whitespace tokenization, which is the same approach used to perform gaze annotations across all eye-tracking corpora. Mean sentence length is expressed in number of tokens, and the number of unique types is computed as the size of the vocabulary after removing punctuation from all tokens. Approximately 128,000 tokens annotated with gaze recordings from multiple participants were used in the experiments of Chapters 4 and 5, while only GECO was used for the analysis of Chapter 3. Similarly to the PCP task, scores were averaged across subjects to reduce noise and obtain general estimates: in particular, reading times that were missing due to skipping were considered as having the lowest duration across annotators, which is a practice commonly used in literature. Again, considering individual participants’ scores is deemed attractive in a personalization perspective but far beyond this work’s scope.
1.4 Garden-path Sentences
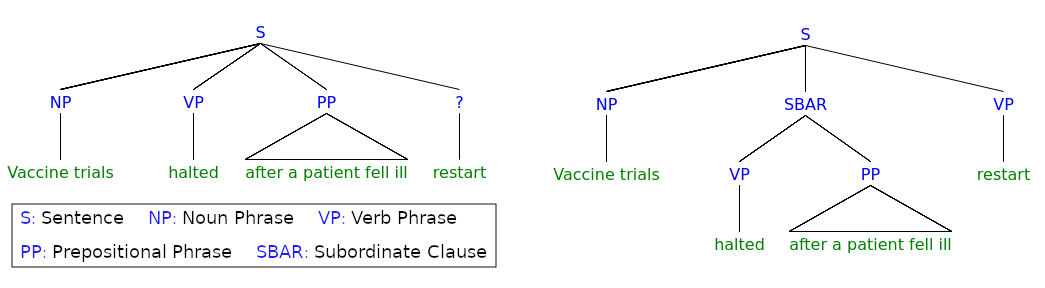
Figure 1.2: Syntax trees for the initial and complete parse of garden-path example (1).
Garden-path sentences, named from the expression “leading down the garden path” implying deception, are grammatically correct sentences that create a momentarily ambiguous interpretation in readers. The initial interpretation is later falsified by words encountered during sequential reading, becoming a significant source of processing difficulties. For this reason, garden-path constructions are used to evaluate models of linguistic complexity in the experiments of Chapter 5. Consider the following recent headline by the newspaper The Guardian:9
- Vaccine trials halted after patient fell ill restart.
Readers exposed to (1) tend to initially prefer the interpretation in which halted acts as the main verb of the sentence in simple past, i.e., “Vaccine trials halted after patient fell ill.” is interpreted as a well-formed and semantically meaningful sentence. When the verb restart is reached, it suddenly becomes evident that the original parse would lead to an ungrammatical sentence, and a reanalysis requiring nontrivial cognitive processing is triggered. In conclusion, one understands that halted is used as a passive participle, and Vaccine trials are the subordinate clause’s direct object, as shown in Figure 1.2. We can rephrase the sentence with minimal changes to make it unambiguous:
- Vaccine trials that were halted after patient fell ill restart.
The choice for the initial parse can be explained in terms of frequency of occurrence: subject-verb-object sentences are encountered much more frequently than ones containing reduced relatives in everyday settings, making the first parse more likely (Fine et al. 2013). We refer to the verb causing the reanalysis as disambiguator, and to the difference in cognitive processing between (1) and (2), measured using proxies such as gaze metrics, as garden-path effect (Bever 1970).
Schijndel and Linzen (2020) present two families of cognitive processing theories trying to motivate the underlying difficulties in which humans incur with garden-path sentences:
Two-stage accounts assume that readers consider only one or a subset of possible parses for each sentence that it is reading (Gibson 1991; Jurafsky 1996), and processing difficulties arise as a consequence of the reanalysis process need to reconstruct parses that were initially disregarded or not considered (Frazier and Fodor 1978).
One-stage accounts such as surprisal theory (Hale 2001; Levy 2008) instead consider difficulties produced by garden paths as the products of a single processing mechanism. Dispreferred parses are not discarded, but rather associated with a lower probability compared to that of likely ones: “processing difficulty on every word in the sentence, including the disambiguating words in garden-path sentences, arises from the extent to which the word shifts the reader’s subjective probability distribution over possible parses” (Schijndel and Linzen 2020).
There are multiple types of garden-path sentences, usually categorized based on their respective syntactic ambiguities (Frazier 1978). In this work, two classic garden-path families are studied in three different settings using examples taken from Futrell et al. (2019). The first type is the MV/RR ambiguity presented in example (1), and repeated in (3a):
- The woman brought the sandwich fell in the dining room. [RED., AMBIG.]
- The woman who was brought the sandwich fell in the dining room. [UNRED., AMBIG.]
- The woman given the sandwich fell in the dining room. [RED., UNAMBIG.]
- The woman who was given the sandwich fell in the dining room. [UNRED., UNAMBIG.]
The label MV/RR indicates that brought can be initially parsed either as the main verb (MV) in the past tense of the clause or as a passive participle introducing a reduced relative (RR) clause, which postmodifies the subject. It is possible to rewrite the sentence by changing the ambiguous verb to an equivalent one having different forms for simple past and past participle (such as gave vs. given). In this case, we expect that the difference in cognitive processing for the disambiguator fell between the reduced (3c) and the unreduced (3d) version is smaller since the ambiguity is ruled out from the beginning.
The second type of ambiguity is the NP/Z ambiguity presented in (4a):
- As the criminal shot the woman yelled at the top of her lungs. [TRANS., NO COMMA]
- As the criminal fled the woman yelled at the top of her lungs. [INTRANS., NO COMMA]
- As the criminal shot, the woman yelled at the top of her lungs. [TRANS., COMMA]
- As the criminal fled, the woman yelled at the top of her lungs. [INTRANS., COMMA]
The label NP/Z is used to indicate that the transitive verb shot can initially be understood to have either have a noun phrase (NP) object like the woman or a zero (Z), i.e., null object if used intransitively as it is the case for (4a). The sentence can be rewritten by substituting the transitive verb generating the ambiguity with an intransitive one, e.g., replacing shot with fled in (4b), by adding a disambiguating comma to force the null-object parse as in (4c), or by doing both as in (4d). We expect that the cognitive processing difference for the disambiguator yelled between the ambiguous (4a) and the unambiguous (4b) is smaller since the ambiguity is ruled out from the beginning.
As an additional NP/Z setting evaluation, consider the case in which an overt object is added to the verb introducing the ambiguity:
- As the criminal shot the woman yelled at the top of her lungs. [NO OBJ., NO COMMA]
- As the criminal shot his gun the woman yelled at the top of her lungs. [OBJ., NO COMMA]
- As the criminal shot, the woman yelled at the top of her lungs. [NO OBJ., COMMA]
- As the criminal shot his gun, the woman yelled at the top of her lungs. [OBJ., COMMA]
Again, we expect that the difference in cognitive processing for yelled is higher in the non-object pair (5a)-(5c), where the first item is a garden-path sentence, rather than in the pair (5b)-(5d) where both sentences are unambiguous.
Gaze metrics and Garden-path Sentences As can be intuitively assumed, garden-path effects are reflected in gaze metrics collected during natural reading. Multiple studies have focused on quantifying the difference between garden-path sentences and their unambiguous counterparts on reading times in human subjects. Sturt, Pickering, and Crocker (1999) found a massive delay of 152ms for each word in the disambiguating region of NP/Z sentences. Grodner et al. (2003) estimate an average delay of 64ms over the disambiguating region for NP/Z constructs using 53 college students’ reading times over a set of 20 ambiguous sentences. More recently, Prasad and Linzen (2019b) recorded eye measurements for 224 participants recruited through Amazon Mechanical Turk on the same set of NP/Z sentences as Grodner et al. (2003), finding a much lower average delay of 28ms, and suggesting an overestimation in previous studies due to small sample size and publication contingency to significant results. Prasad and Linzen (2019a) collected self-paced reading times from 73 participants recruited on the Prolific Academic crowdsourcing platform and measured an average delay of 22ms over the disambiguating region for MV/RR constructs.
Given the high variability in results across studies, it can be hypothesized that the way in which stimuli were presented to subjects plays a significant role in determining the magnitude of garden-path effects (Van Schijndel and Linzen 2018). For example, a sentence presented word-by-word to subjects may yield more ecologically valid reading times estimates than a sentence presented region-by-region. Another problematic factor involves constraining the impact of garden-path effects to the disambiguating region: first, because parafoveal preview effects may slightly anticipate the start of the effect (Schotter, Angele, and Rayner 2012; Schotter 2018); and second, because due to spillover (Mitchell 1984), a phenomenon in which the surprisal of a word influences the reading times for itself and at least three subsequent words (Smith and Levy 2013), reading times of the disambiguating region are influenced by preceding words, and influence subsequent ones, spreading the garden-path effect on a much broader context. For this reason, eye-tracking metrics are studied for all sentence regions in the experiments of Chapter 5.
References
Ambati, Bharat Ram, Siva Reddy, and Mark Steedman. 2016. “Assessing Relative Sentence Complexity Using an Incremental CCG Parser.” In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 1051–7. San Diego, California: Association for Computational Linguistics. https://doi.org/10.18653/v1/N16-1120.
Barrett, Maria, Joachim Bingel, Frank Keller, and Anders Søgaard. 2016. “Weakly Supervised Part-of-Speech Tagging Using Eye-Tracking Data.” In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 579–84. Berlin, Germany: Association for Computational Linguistics. https://doi.org/10.18653/v1/P16-2094.
Berruto, Gaetano, and Massimo Simone Cerruti. 2011. La Linguistica. Un Corso Introduttivo. De Agostini.
Berzak, Yevgeni, Boris Katz, and Roger Levy. 2018. “Assessing Language Proficiency from Eye Movements in Reading.” In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 1986–96. New Orleans, Louisiana: Association for Computational Linguistics. https://doi.org/10.18653/v1/N18-1180.
Bever, Thomas G. 1970. “The Cognitive Basis for Linguistic Structures.” Cognition and the Development of Language. Wiley.
Brunato, Dominique, Andrea Cimino, Felice Dell’Orletta, Giulia Venturi, and Simonetta Montemagni. 2020. “Profiling-UD: A Tool for Linguistic Profiling of Texts.” In Proceedings of the 12th Language Resources and Evaluation Conference, 7145–51. Marseille, France: European Language Resources Association. https://www.aclweb.org/anthology/2020.lrec-1.883.
Brunato, Dominique, Lorenzo De Mattei, Felice Dell’Orletta, Benedetta Iavarone, and Giulia Venturi. 2018. “Is This Sentence Difficult? Do You Agree?” In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2690–9. Brussels, Belgium: Association for Computational Linguistics. https://doi.org/10.18653/v1/D18-1289.
Cangelosi, Angelo, and Huck Turner. 2002. “L’emergere Del Linguaggio.” Scienze Della Mente.
Carr, Jon W, Valentina N Pescuma, Michele Furlan, Maria Ktori, and Davide Crepaldi. 2020. “Algorithms for the Automated Correction of Vertical Drift in Eye Tracking Data.” OSF Preprints, June. osf.io/jg3nc.
Caruana, Rich. 1997. “Multitask Learning.” Machine Learning 28: 41–75. https://www.cs.utexas.edu/~kuipers/readings/Caruana-mlj-97.pdf.
Christie, Agatha. 2003. The Mysterious Affair at Styles: A Detective Story. Modern Library.
Cop, Uschi, Nicolas Dirix, Denis Drieghe, and Wouter Duyck. 2017. “Presenting Geco: An Eyetracking Corpus of Monolingual and Bilingual Sentence Reading.” Behavior Research Methods 49 (2). Springer: 602–15.
Culotta, Aron, Andrew McCallum, and Jonathan Betz. 2006. “Integrating Probabilistic Extraction Models and Data Mining to Discover Relations and Patterns in Text.” In Proceedings of the Human Language Technology Conference of the NAACL, Main Conference, 296–303. New York City, USA: Association for Computational Linguistics. https://www.aclweb.org/anthology/N06-1038.
Day, Matthew. 2004. “Religion, Off-Line Cognition and the Extended Mind.” Journal of Cognition and Culture 4 (1). Brill: 101–21.
Demberg, Vera, and Frank Keller. 2008. “Data from Eye-Tracking Corpora as Evidence for Theories of Syntactic Processing Complexity.” Cognition 109 (2). Elsevier: 193–210.
Edmonds, Bruce M. 1999. “Syntactic Measures of Complexity.” PhD thesis, University of Manchester Manchester, UK.
Fine, Alex B, T Florian Jaeger, Thomas A Farmer, and Ting Qian. 2013. “Rapid Expectation Adaptation During Syntactic Comprehension.” PloS One 8 (10). Public Library of Science: e77661.
Frazier, Lyn. 1978. “On Comprehending Sentences: Syntactic Parsing Strategies.” PhD thesis, University of Connecticut.
Frazier, Lyn, and Janet Dean Fodor. 1978. “The Sausage Machine: A New Two-Stage Parsing Model.” Cognition 6 (4). Elsevier: 291–325.
Futrell, Richard, Edward Gibson, and Roger P Levy. 2020. “Lossy-Context Surprisal: An Information-Theoretic Model of Memory Effects in Sentence Processing.” Cognitive Science 44 (3). Wiley Online Library: e12814.
Futrell, Richard, Ethan Wilcox, Takashi Morita, Peng Qian, Miguel Ballesteros, and Roger Levy. 2019. “Neural Language Models as Psycholinguistic Subjects: Representations of Syntactic State.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 32–42. Minneapolis, Minnesota: Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1004.
Gibson, Edward. 1991. “A Computational Theory of Human Linguistic Processing: Memory Limitations and Processing Breakdown.” PhD thesis, Pittsburgh, PA: Carnegie Mellon University.
Gibson, Edward. 1998. “Linguistic Complexity: Locality of Syntactic Dependencies.” Cognition 68 (1). Elsevier: 1–76.
Gibson, Edward. 2000. “The Dependency Locality Theory: A Distance-Based Theory of Linguistic Complexity.” Image, Language, Brain 2000: 95–126.
González-Garduño, Ana Valeria, and Anders Søgaard. 2018. “Learning to Predict Readability Using Eye-Movement Data from Natives and Learners.” AAAI Conference on Artificial Intelligence.
Goodman, Joshua. 2001. “A Bit of Progress in Language Modeling.” arXiv Preprint Cs/0108005.
Grodner, Daniel, Edward Gibson, Vered Argaman, and Maria Babyonyshev. 2003. “Against Repair-Based Reanalysis in Sentence Comprehension.” Journal of Psycholinguistic Research 32 (2). Springer: 141–66.
Hale, John. 2001. “A Probabilistic Earley Parser as a Psycholinguistic Model.” In Second Meeting of the North American Chapter of the Association for Computational Linguistics.
Hale, John. 2016. “Information-Theoretical Complexity Metrics.” Language and Linguistics Compass 10 (9). Wiley Online Library: 397–412.
Hauser, Marc D, Noam Chomsky, and W Tecumseh Fitch. 2002. “The Faculty of Language: What Is It, Who Has It, and How Did It Evolve?” Science 298 (5598). American Association for the Advancement of Science: 1569–79.
Hollenstein, Nora, Jonathan Rotsztejn, Marius Troendle, Andreas Pedroni, Ce Zhang, and Nicolas Langer. 2018. “ZuCo, a Simultaneous Eeg and Eye-Tracking Resource for Natural Sentence Reading.” Scientific Data 5 (1). Nature Publishing Group: 1–13.
Hollenstein, Nora, Marius Troendle, Ce Zhang, and Nicolas Langer. 2020. “ZuCo 2.0: A Dataset of Physiological Recordings During Natural Reading and Annotation.” In Proceedings of the 12th Language Resources and Evaluation Conference, 138–46. Marseille, France: European Language Resources Association. https://www.aclweb.org/anthology/2020.lrec-1.18.
Hollenstein, Nora, and Ce Zhang. 2019. “Entity Recognition at First Sight: Improving NER with Eye Movement Information.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 1–10. Minneapolis, Minnesota: Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1001.
Iverson, Jana M, and Esther Thelen. 1999. “Hand, Mouth and Brain. The Dynamic Emergence of Speech and Gesture.” Journal of Consciousness Studies 6 (11-12). Imprint Academic: 19–40.
Jurafsky, Daniel. 1996. “A Probabilistic Model of Lexical and Syntactic Access and Disambiguation.” Cognitive Science 20 (2). Wiley Online Library: 137–94.
Kennedy, Alan, Robin Hill, and Joël Pynte. 2003. “The Dundee Corpus.” In Proceedings of the 12th European Conference on Eye Movement.
Kusters, Wouter. 2003. “Linguistic Complexity.” PhD thesis, Netherlands Graduate School of Linguistics.
Kusters, Wouter. 2008. “Complexity in Linguistic Theory, Language Learning and Language Change.” In Language Complexity: Typology, Contact, Change, 3–22. John Benjamins Amsterdam, The Netherlands.
Levy, Roger. 2008. “Expectation-Based Syntactic Comprehension.” Cognition 106 (3). Elsevier: 1126–77.
McDonald, Ryan, Joakim Nivre, Yvonne Quirmbach-Brundage, Yoav Goldberg, Dipanjan Das, Kuzman Ganchev, Keith Hall, et al. 2013. “Universal Dependency Annotation for Multilingual Parsing.” In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 92–97. Sofia, Bulgaria: Association for Computational Linguistics. https://www.aclweb.org/anthology/P13-2017.
McWhorter, John H. 2001. “The Worlds Simplest Grammars Are Creole Grammars.” Linguistic Typology 5 (2-3). De Gruyter Mouton: 125–66.
Meyer, Bonnie JF, and G Elizabeth Rice. 1992. “12 Prose Processing in Adulthood: The Text, the Reader, and the Task.” Everyday Cognition in Adulthood and Late Life. Cambridge Univ Pr, 157.
Miestamo, Matti. 2004. “On the Feasibility of Complexity Metrics.” In FinEst Linguistics, Proceedings of the Annual Finnish and Estonian Conference of Linguistics, 11–26. Tallin, Finland.
Miestamo, Matti. 2008. “Grammatical Complexity in a Cross-Linguistic Perspective.” In Language Complexity: Typology, Contact, Change, 41. John Benjamins Amsterdam, The Netherlands.
Mishra, Abhijit, Kuntal Dey, and Pushpak Bhattacharyya. 2017. “Learning Cognitive Features from Gaze Data for Sentiment and Sarcasm Classification Using Convolutional Neural Network.” In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 377–87. Vancouver, Canada: Association for Computational Linguistics. https://doi.org/10.18653/v1/P17-1035.
Mitchell, Don C. 1984. “An Evaluation of Subject-Paced Reading Tasks and Other Methods for Investigating Immediate Processes in Reading.” New Methods in Reading Comprehension Research, 69–89.
Munro, Robert, Steven Bethard, Victor Kuperman, Vicky Tzuyin Lai, Robin Melnick, Christopher Potts, Tyler Schnoebelen, and Harry Tily. 2010. “Crowdsourcing and Language Studies: The New Generation of Linguistic Data.” In Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, 122–30. Los Angeles: Association for Computational Linguistics. https://www.aclweb.org/anthology/W10-0719.
Nivre, Joakim, Marie-Catherine de Marneffe, Filip Ginter, Yoav Goldberg, Jan Hajič, Christopher D. Manning, Ryan McDonald, et al. 2016. “Universal Dependencies V1: A Multilingual Treebank Collection.” In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), 1659–66. Portorož, Slovenia: European Language Resources Association (ELRA). https://www.aclweb.org/anthology/L16-1262.
Prasad, Grusha, and Tal Linzen. 2019a. “Do Self-Paced Reading Studies Provide Evidence for Rapid Syntactic Adaptation?” PsyArXiv Pre-Print. https://tallinzen.net/media/papers/prasad_linzen_2019_adaptation.pdf.
Prasad, Grusha, and Tal Linzen. 2019b. “How Much Harder Are Hard Garden-Path Sentences Than Easy Ones?” OSF Preprint syh3j. https://osf.io/syh3j/.
Ruder, Sebastian. 2017. “An Overview of Multi-Task Learning in Deep Neural Networks.” ArXiv Pre-Print 1706.05098. https://arxiv.org/abs/1706.05098.
Schijndel, Marten van, and Tal Linzen. 2020. “Single-Stage Prediction Models Do Not Explain the Magnitude of Syntactic Disambiguation Difficulty.” PsyArXiv Pre-Print sgbqy. https://psyarxiv.com/sgbqy/.
Schotter, Elizabeth R. 2018. “Reading Ahead by Hedging Our Bets on Seeing the Future: Eye Tracking and Electrophysiology Evidence for Parafoveal Lexical Processing and Saccadic Control by Partial Word Recognition.” In Psychology of Learning and Motivation, 68:263–98. Elsevier.
Schotter, Elizabeth R. 2020. Eye Tracking for Cognitive Science. SISSA Course.
Schotter, Elizabeth R, Bernhard Angele, and Keith Rayner. 2012. “Parafoveal Processing in Reading.” Attention, Perception, & Psychophysics 74 (1). Springer: 5–35.
Simi, Maria, Cristina Bosco, and Simonetta Montemagni. 2014. “Less Is More? Towards a Reduced Inventory of Categories for Training a Parser for the Italian Stanford Dependencies.” In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), 83–90. Reykjavik, Iceland: European Language Resources Association (ELRA). http://www.lrec-conf.org/proceedings/lrec2014/pdf/818_Paper.pdf.
Singh, Abhinav Deep, Poojan Mehta, Samar Husain, and Rajkumar Rajakrishnan. 2016. “Quantifying Sentence Complexity Based on Eye-Tracking Measures.” In Proceedings of the Workshop on Computational Linguistics for Linguistic Complexity (CL4LC), 202–12. Osaka, Japan: The COLING 2016 Organizing Committee. https://www.aclweb.org/anthology/W16-4123.
Sinnemäki, Kaius. 2011. “Language Universals and Linguistic Complexity: Three Case Studies in Core Argument Marking.” PhD thesis, University of Helsinki.
Smith, Nathaniel J, and Roger Levy. 2013. “The Effect of Word Predictability on Reading Time Is Logarithmic.” Cognition 128 (3). Elsevier: 302–19.
Socher, Richard, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. 2013. “Recursive Deep Models for Semantic Compositionality over a Sentiment Treebank.” In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 1631–42. Seattle, Washington, USA: Association for Computational Linguistics. https://www.aclweb.org/anthology/D13-1170.
Straka, Milan, Jan Hajič, and Jana Straková. 2016. “UDPipe: Trainable Pipeline for Processing CoNLL-U Files Performing Tokenization, Morphological Analysis, POS Tagging and Parsing.” In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), 4290–7. Portorož, Slovenia: European Language Resources Association (ELRA). https://www.aclweb.org/anthology/L16-1680.
Strzyz, Michalina, David Vilares, and Carlos Gómez-Rodríguez. 2019. “Towards Making a Dependency Parser See.” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (Emnlp-Ijcnlp), 1500–1506. Hong Kong, China: Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1160.
Sturt, Patrick, Martin J Pickering, and Matthew W Crocker. 1999. “Structural Change and Reanalysis Difficulty in Language Comprehension.” Journal of Memory and Language 40 (1). Elsevier: 136–50.
Taylor, Wilson L. 1953. “‘Cloze Procedure’: A New Tool for Measuring Readability.” Journalism Quarterly 30 (4). SAGE Publications Sage CA: Los Angeles, CA: 415–33.
Vajjala, Sowmya, and Ivana Lucic. 2019. “On Understanding the Relation Between Expert Annotations of Text Readability and Target Reader Comprehension.” In Proceedings of the Fourteenth Workshop on Innovative Use of Nlp for Building Educational Applications, 349–59. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/W19-4437.
Vajjala, Sowmya, and Ivana Lučić. 2018. “OneStopEnglish Corpus: A New Corpus for Automatic Readability Assessment and Text Simplification.” In Proceedings of the Thirteenth Workshop on Innovative Use of NLP for Building Educational Applications, 297–304. New Orleans, Louisiana: Association for Computational Linguistics. https://doi.org/10.18653/v1/W18-0535.
Van Schijndel, Marten, and Tal Linzen. 2018. “Modeling Garden Path Effects Without Explicit Hierarchical Syntax.” In Proceedings of the 40th Annual Conference of the Cognitive Science Society, 2600–2605.
Vasishth, Shravan, Titus von der Malsburg, and Felix Engelmann. 2013. “What Eye Movements Can Tell Us About Sentence Comprehension.” Cognitive Science 4 2. Wiley interdisciplinary reviews: 125–34. https://onlinelibrary.wiley.com/doi/full/10.1002/wcs.1209.
Voghera, Miriam. 2001. “Riflessioni Su Semplificazione, Complessità E Modalità Di Trasmissione: Sintassi E Semantica.” Scritto E Parlato. Metodi, Testi E Contesti. Aracne, 65–78.
Xu, Wei, Chris Callison-Burch, and Courtney Napoles. 2015. “Problems in Current Text Simplification Research: New Data Can Help.” Transactions of the Association for Computational Linguistics 3: 283–97. https://doi.org/10.1162/tacl_a_00139.
Available at http://linguistic-profiling.italianlp.it↩
This motivates the previous claim about the interdependence of intrinsic and extrinsic approaches. See Section 2.1 of Martinc, Pollak, and Robnik-Sikonja (2019) for an overview of the most popular metrics for English.↩
This is an admittedly simplistic reduction, given the importance of parafoveal processing in reading (Schotter, Angele, and Rayner 2012; Schotter 2018)↩
See Collins-Thompson (2014) for a thorough review of ARA approaches.↩
See Rayner (1998) for a comprehensive survey on findings related to eye-tracking research.↩
See Hollenstein, Barrett, and Beinborn (2020) for an exhaustive overview of current approaches and best practices.↩
Appendix B contains information about deriving metric values for all corpora.↩