5 Gaze-informed Models for Cognitive Processing Prediction
This final experimental chapter aims to study the syntactic generalization capabilities of neural language models by evaluating their performances over atypical linguistic constructions. In particular, architectures pre-trained with masked and causal language modeling are evaluated in their ability to predict garden-path effects on three test suites taken from the SyntaxGym psycholinguistic benchmark. First, the results of previous studies using GPT-2 surprisal to predict garden-path effects are reproduced, and a conversion coefficient is used to evaluate GPT-2 surprisal in terms of human reading times delays. Two neural language models are fine-tuned over gaze metrics from multiple eye-tracking corpora in a multitask token-level setting. Gaze metric predictions on garden-path sentences are evaluated to see whether gaze data fine-tuning can improve garden-path effects prediction. Results highlight how GPT-2 surprisals overestimate the magnitude of MV/RR and NP/Z garden-path effects, and fine-tuning procedures on gaze metrics prediction over typical linguistic structures do not benefit the generalization capabilities of neural language models on out-of-distribution cases like garden-path sentences.
Human behavioral data collected during naturalistic reading can provide useful insights into the primary sources of processing difficulties during reading comprehension. Multiple cognitive processing theories were formulated to account for the sources of such difficulties (see Section 1.4). Notably, surprisal theory (Hale 2001; Levy 2008) suggests that processing during reading is the direct result of a single mechanism, that is, the shift in readers’ probability distribution over all possible parses. To evaluate whether this perspective holds empirically, language models defining a probability distribution over a vocabulary given previous context (RNNs in Elman (1991) and Mikolov et al. (2010), recently Transformers in Hu et al. (2020)) are commonly used to obtain accurate predictability estimates that can directly be compared to behavioral recordings (e.g. gaze metrics) acting as proxies of human cognitive processing.
A computational model that consistently mimics human processing behaviors would provide strong evidence of cognitive processing’s underlying probabilistic-driven nature. For this reason, many studies in the fields of syntax and psycholinguistics have focused on probing the abilities of language models to highlight phenomena related to reading difficulties (Linzen, Dupoux, and Goldberg 2016; Gulordava et al. 2018; Futrell et al. 2019). Peculiar constructions like garden-path sentences are often used in this context to evaluate the generalization capabilities of language models for two main reasons. First, garden-path sentences are rare in naturally-occurring text. As such, they represent out-of-distribution examples for any language model trained on conventional data and can be used to test the latter’s generalization capabilities. Secondly, researchers nowadays have access to reasonably-sized literature describing the impact of garden-path effects on cognitive processing proxies such as gaze recordings, with articles being often released alongside publicly-available resources for reproducible evaluation (Prasad and Linzen 2019a, 2019b) and recently even ad-hoc benchmarks (Gauthier et al. 2020).
This final experimental chapter evaluates the ability of neural language models in predicting garden-path effects observed on human subjects, using language modeling surprisal and eye-tracking metrics elicited respectively before and after multitask token-level eye-tracking fine-tuning for garden-path effects prediction. Specifically, an autoregressive (GPT-2, Radford et al. (2019)) and a masked language model (ALBERT, Lan et al. (2020)) are first tested over three garden-path test suites that are part of the SyntaxGym benchmark to evaluate whether their language modeling surprisal before and after eye-tracking fine-tuning (ET) can be used to predict the presence and the magnitude of garden-path effects over disambiguating regions. In particular, GPT-2 and GPT-2 XL results presented in Hu et al. (2020) are reproduced. Finally, the same procedure is repeated using predicted eye-tracking scores predicted by models after fine-tuning instead of language modeling surprisal, following the intuition that an accurate model of gaze measurements should predict such phenomena correctly.
While the usage of surprisal is a common practice for garden-path effect prediction, leveraging eye-tracking scores predicted by a neural language model trained for this purpose is a novel research direction that is deemed interesting as a way to combine the predictive power of modern language models and the strong connection between cognitive processing and gaze metrics. While predicted gaze metrics for garden-path evaluation were used in concurrent studies (Schijndel and Linzen 2020), the approach adopted by this work can be regarded as complementary evidence since eye-tracking metrics predictions are produced as results of an end-to-end supervised fine-tuning procedure involving a neural language model rather than being derived from surprisal values through a conversion coefficient. Findings suggest that, while surprisal scores from autoregressive models accurately reflect garden-path structures both before and after fine-tuning, gaze metrics predictions produced by fine-tuned models do not account for the temporary syntactic ambiguity that characterizes such sentences and makes them difficult to process.
Contributions This study validates the performances of standard and gaze-informed Transformed-based neural language models for garden-path effects prediction. In particular:
It reproduces the GPT-2 performances on garden-path test suites reported by Gauthier et al. (2020) and highlights how GPT-2 overestimates reading delays caused by garden-path effects on MV/RR and NP/Z constructions.
It highlights masked language models’ inability to consistently predict garden-path effects, using language modeling surprisal and gaze metrics predictions.
It introduces a novel gaze metrics multitask token-level fine-tuning approach that, despite being accurate for predicting eye-tracking scores on standard constructions, does not improve models’ performances on garden-path effects predictions.
5.1 Experimental Setup
Fine-tuning data As for the gaze metrics model presented in the previous chapter, all eye-tracking datasets presented in Section 1.3.3 were merged and used to fine-tune neural language models using the multitask token-level approach described in Appendix C. Only the training variant without embedding concatenation (referred to as “surprisal” in the appendix) was evaluated on garden-path test suites given comparable modeling performances.
Models Two variants of GPT-2 having respectively 117 million and 1.5 billion parameters are evaluated in terms of surprisal-driven predictability, alongside an ALBERT model with 11 million parameters.22 Only the small GPT-2 model and the ALBERT model were fine-tuned for gaze metric predictions due to limited computational resources.
Evaluation data SyntaxGym (Gauthier et al. 2020) is a recently introduced online platform designed to make the targeted evaluation of language models on psycholinguistic test suites both accessible and reproducible. The MV/RR and NP/Z test suites containing garden paths from Futrell et al. (2019) are used in the context of this work. The MV/RR test suite consists of 28 groups containing a sentence with a main verb/reduced relative ambiguity and its non-ambiguous rewritings. In comparison, the NP/Z test suites consist of 24 groups containing a sentence with a nominal/zero predicate ambiguity, produced either by a misinterpreted transitive use of a verb (Verb Transitivity) or the absence of an object for the main verb (Overt Object). Examples (3), (4), and (5) from Section 1.4 follow the format used in the three SyntaxGym test suites used in this work.

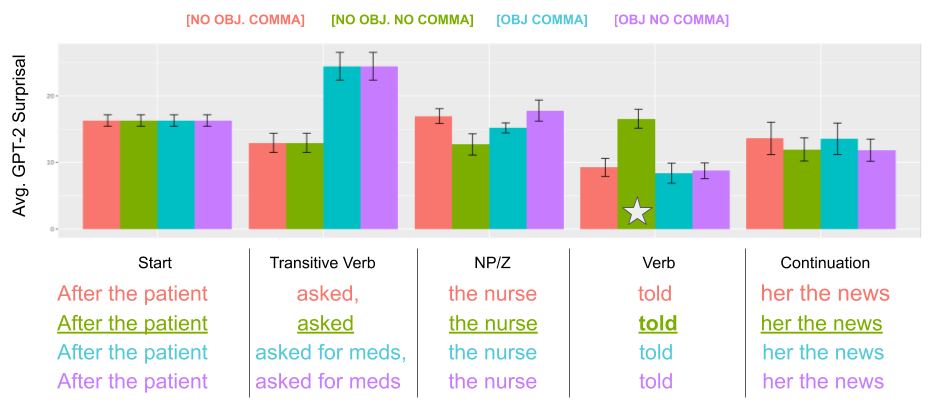
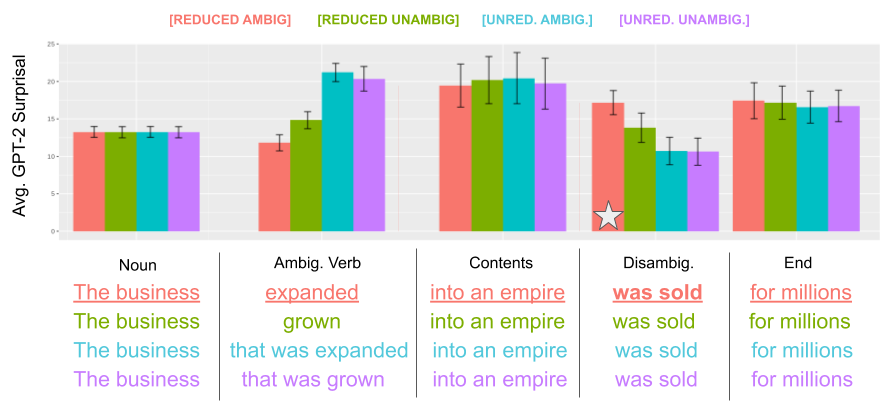
Figure 5.1: Average GPT-2 surprisal predictions and examples for the NP/Z Ambiguity with Verb Transitivity (top), the NP/Z Ambiguity with Overt Object (middle), and the MV/RR Ambiguity (bottom) SyntaxGym test suites used in this study. Star marks the garden-path disambiguator (bold in examples), and bars show 95% confidence intervals.
5.2 Experimental Evaluation
For the first part of the experiments, the smallest version of the model GPT-2 is used. Figure 5.1 reproduces the original setting tested by Hu et al. (2020), showing how predictability estimates produced by the model correctly individuate the presence of garden-path effects.23 Surprisal values are computed using a pre-trained GPT-2 for all tokens in all sentences of the three test suites. Then, those values are aggregated by summing them across all tokens composing a sentence region. For example, for the NP/Z Ambiguity test suite entry shown in example (a) the region “Start” will be associated with the sum of surprisal estimates for all subword tokens in the sequence While the students. It is important to note that the four variants of the same sentence have only minimal variations, but only one of those (the underlined one in all examples) is a garden-path sentence. After computing GPT-2 surprisal scores for all regions of all sentences in the test sets, those are averaged region-wise across sentences belonging to the same test set to obtain the three plots presented in Figure 5.1. The star symbol is used to mark the disambiguating region of garden-path sentences, making evident how predictability estimates are significantly lower (i.e., higher surprisal values) for those and correctly predict the presence of a garden-path effect in most settings and for all the three garden-path variants.
5.2.1 Estimating Magnitudes of Garden-path Delays
An important part of evaluating model predictions over garden-path sentences is determining whether the increase in surprisal scores correctly captures the effect’s magnitude. Schijndel and Linzen (2020) perform this evaluation on RNN language models, finding that they vastly underestimate garden-path effects for MV/RR and NP/Z ambiguities. In their approach, Schijndel and Linzen (2020) estimate the surprisal-to-reading-times conversion rate at 2ms per surprisal bit by fitting a linear mixed-effect model on relevant factors (surprisal, entropy, word length, among others) relative to a word and its three preceding words to account for spillover effects. The approach adopted in this work is different in that it stems from the empirical relation between surprisal scores produced by GPT-2 and reading times produced by eye-tracking experiments’ participants. Figure 5.2 presents the median values over words for the ratio between gaze metrics recorded by participants and GPT-2 surprisal estimates, with the red cross indicating the average median surprisal-to-metric ratio \(C_{\text{corpus}}^{\text{metric}}\) computed across all participants of a corpus. The following formula is used to produce the surprisal-to-reading-times conversion coefficient: \[\begin{equation} C_{S\rightarrow RT} = w_1 \cdot C_{\text{GECO}}^{\text{FPD}} + w_2 \cdot C_{\text{Dundee}}^{\text{FPD}} + w_3 \cdot C_{\text{ZuCo NR}}^{\text{FPD}} + w_4 \cdot C_{\text{ZuCo SR}}^{\text{FPD}} + w_5 \cdot C_{\text{ZuCo 2.0}}^{\text{FPD}} \end{equation}\] with \(w = [.4, .45, .05, .05, .05]\) being the weighting coefficients representing the proportion of each corpus’ tokens over the total amount of available gaze-annotated tokens.
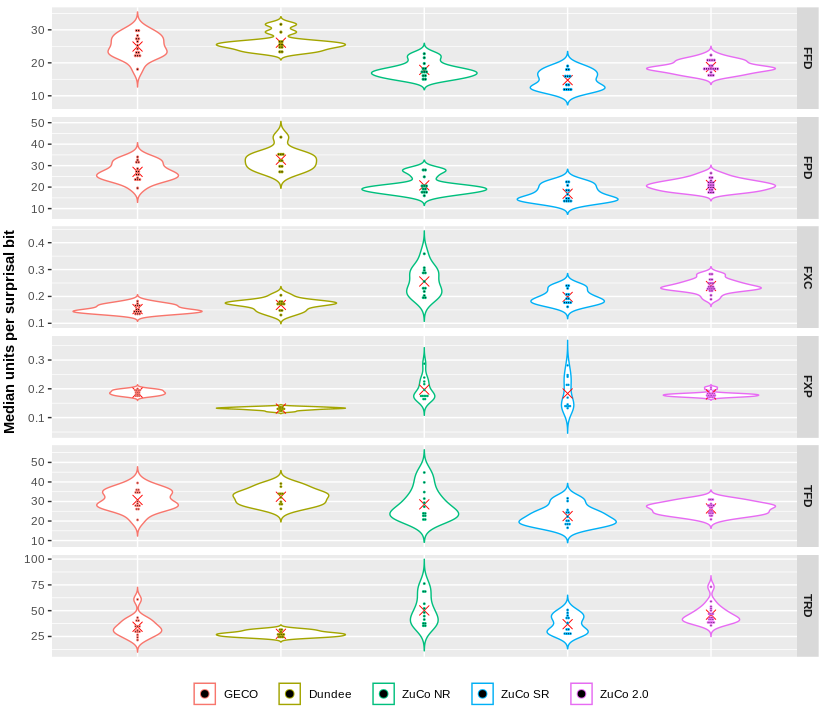
Figure 5.2: Median scores for the ratio between gaze metrics units and GPT-2 surprisal estimates across all participants of all eye-tracking datasets used in this study. The red cross shows the average across participants of a single dataset. Units are in ms for durations, % for FXP, and raw counts for FXC.
The resulting value for the conversion coefficient is \(27.7\), i.e., each surprisal bit predicted by GPT-2 accounts for roughly 27.7 milliseconds in first pass duration (30.3ms using TFD). When applied to the average effects predicted by GPT-2 in Figure 5.1, it leads to an estimated delay of roughly 64ms for the MV/RR setting and 166ms and 194ms for the NP/Z Ambiguity and NP/Z Overt Object settings, respectively. These computed delays overestimate the literature’s effects: Prasad and Linzen (2019a) and Prasad and Linzen (2019b), for example, report an average garden-path effect of 22ms and 27ms for MV/RR and NP/Z variants, respectively. However, it should be mentioned that precedent studies found higher delays for NP/Z structures: Grodner et al. (2003) find a 64ms delay on disambiguating words, and Sturt, Pickering, and Crocker (1999)‘s delays of 152ms per word are close to the estimates produced by GPT-2 surprisal predictions. Overall, using models’ surprisal on gaze-annotated sentences to directly compute a conversion coefficient produces values that correctly identify delays on disambiguating regions and overestimate the magnitude of garden-path effects conversely to what was found by Schijndel and Linzen (2020). Even with an adjustment of the conversion coefficient to match MV/RR estimates with Prasad and Linzen (2019a) findings, the NP/Z effect prediction would still be much larger than the empirically-observed values collected in comparable settings.
5.2.2 Predicting Delays with Surprisal and Gaze Metrics
The other perspective explored in this study is evaluating whether gaze metric predicted by models fine-tuned on eye-tracking corpora annotations can correctly estimate the presence and magnitude of garden-path effects and how they compare to surprisal-driven approaches. Table 5.1 presents the accuracy of multiple pre-trained Transformer-based language models in respecting a set of three conditions taken from Hu et al. (2020) for each SyntaxGym test suite, namely: \[\begin{equation} V_d(b) < V_d(a);\qquad V_d(c) < V_d(a);\qquad V_d(c)-V_d(d) < V_d(a)-V_d(b) \end{equation}\] Where \(V_d(a)\) corresponds to the value, either in terms of surprisal or gaze metrics, assigned by a model to the disambiguating region \(d\) of sentence \(a\), and \(a,b,c,d\) are the same sentence’s variants for each test suite presented in examples (3),(4) and (5) of Section 1.4. Accuracy is computed as the proportion of items in the test suite on which the language model’s predictions conform to the respective criterion. The first three models (GPT-2, GPT-2 XL, and ALBERT) are the pre-trained variants of the three models presented in Table 5.1 without additional fine-tuning. Instead, the GPT-2 ET and ALBERT ET models correspond to the same GPT-2 and ALBERT models as before after a multitask token-level fine-tuning on gaze metrics for all the aggregated corpora. The top part of Table 5.1 shows the five models’ performances while using region-aggregated surprisals as predictors. Focusing on the GPT-2 variants, it can be observed that they all achieve considerably high scores on all evaluated conditions. Conversely, ALBERT masked language models poorly fit the specified criteria. This fact can be intuitively explained by accounting for the different training and evaluation setup used for the two architectures. GPT-2 models are likely to produce high surprisal estimates for garden-path sentences since, processing the input autoregressively and having access only to previous tokens, they incur in the same syntactic ambiguities faced by human readers.
| Cond. 1 1 | Cond. 2 2 | Cond. 3 3 | Cond. 1 a | Cond. 2 b | Cond. 3 c | Cond. 1 * | Cond. 2 † | Cond. 3 ‡ | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Surprisal | GPT-2 | 0.96 | 0.92 | 0.88 | 0.96 | 1 | 1 | 1 | 0.89 | 0.82 | |
| GPT-2 XL | 1 | 0.96 | 1 | 0.96 | 1 | 1 | 0.93 | 0.75 | 0.75 | ||
| ALBERT | 0.21 | 0.63 | 0.58 | 0.21 | 0.54 | 0.46 | 0.61 | 0.54 | 0.38 | ||
| GPT-2 ET | 0.96 | 0.88 | 0.79 | 0.96 | 1 | 0.96 | 0.96 | 0.79 | 0.82 | ||
| ALBERT ET | 0.42 | 0.42 | 0.58 | 0.42 | 0.75 | 0.62 | 0.5 | 0.64 | 0.64 | ||
| Eye-tracking metrics | GPT-2 ET | FFD | 0.29 | 0.38 | 0.46 | 0.29 | 0.54 | 0.42 | 0.86 | 0.57 | 0.5 |
| FPD | 0.13 | 0.46 | 0.67 | 0.13 | 0.5 | 0.46 | 0.86 | 0.54 | 0.36 | ||
| FXP | 0.38 | 0.5 | 0.42 | 0.42 | 0.41 | 0.42 | 0.71 | 0.43 | 0.57 | ||
| FXC | 0.75 | 0.5 | 0.42 | 0.75 | 0.63 | 0.46 | 0.92 | 0.46 | 0.54 | ||
| TFD | 0.5 | 0.33 | 0.46 | 0.5 | 0.58 | 0.75 | 0.79 | 0.43 | 0.39 | ||
| TRD | 0.67 | 0.46 | 0.54 | 0.63 | 0.25 | 0.54 | 0.29 | 0.39 | 0.5 | ||
| ALBERT ET | FFD | 0.67 | 0.33 | 0.42 | 0.42 | 0.83 | 0.67 | 0.68 | 0.61 | 0.5 | |
| FPD | 0.54 | 0.41 | 0.33 | 0.38 | 0.79 | 0.75 | 0.75 | 0.57 | 0.46 | ||
| FXP | 0.28 | 0.46 | 0.29 | 0.54 | 0.38 | 0.63 | 0.29 | 0.5 | 0.43 | ||
| FXC | 0.63 | 0.46 | 0.5 | 0.38 | 0.67 | 0.71 | 0.86 | 0.43 | 0.39 | ||
| TFD | 0.75 | 0.38 | 0.29 | 0.5 | 0.88 | 0.83 | 0.79 | 0.61 | 0.54 | ||
| TRD | 0.96 | 0.42 | 0.42 | 0.63 | 0.75 | 0.5 | 0.79 | 0.5 | 0.57 | ||
| Description of the evaluated conditions | |||||||||||
| NP/Z Verb Trans.: 1 [Ambig. No Comma] > [Ambig. Comma]; 2 [Ambig. No Comma] > [Unambig. No Comma]; 3 [Ambig. No Comma] - [Ambig. Comma] > [Unambig. No Comma] - [Unambig. Comma] | |||||||||||
| NP/Z Overt Obj.: a [No Obj. No Comma] > [No Obj. Comma]; b [No Obj. No Comma] > [Obj. No Comma]; c [No Obj. No Comma] - [No Obj. Comma] > [Obj. No Comma] - [Obj. Comma] | |||||||||||
| MV/RR Ambig.: * [Reduced Ambig.] > [Unred. Ambig.]; † [Reduced Ambig.] > [Reduced Unambig.]; ‡ [Reduced Ambig.] - [Unred. Ambig.] > [Reduced Unambig.] - [Unred. Unambig.] |
Conversely, ALBERT-like masked language models have access to bidirectional contexts and are not exposed to the ambiguity. It is interesting to observe that while the eye-tracking fine-tuning procedure appears to hamper GPT-2 surprisal performances, it generally improves the ALBERT model’s accuracy. This phenomenon may be due to the sequential nature of reading that is being captured by gaze metrics and transferred to the bidirectional ALBERT model as a useful bias for sequential processing. The same procedure performs suboptimally, instead, when associated with an inherently autoregressive model like the GPT-2 decoder
The bottom part of Table 5.1 presents the two ET-trained models’ accuracy in matching criteria using predicted gaze metrics. For both GPT-2 and ALBERT, it can be observed that gaze metrics vastly underperform in accuracy terms. We can conclude that, despite the conceptual relation between gaze metrics and predictability observed in humans, the predictions of fine-tuned model cannot generalize to unseen settings, and as such eye-tracking predictions obtained after a fine-tuning on standard constructions do not appear useful to individuate or estimate the magnitude of garden-path effects. This observation suggests that fine-tuned models stick to predicting gaze metric values that are the most likely for each specific token, regardless of the surrounding context’s ambiguities. Plots in Appendix E present the region-aggregated average scores for all metrics predicted by GPT-2 ET in the same format as before and show how predictions on the disambiguator regions are unaffected by the presence of previous ambiguities.
5.3 Summary
This chapter focused on two perspectives related to the evaluation of neural language models for garden-path effects prediction. First, promising results from previous studies using GPT-2 surprisal to evaluate predictability are reproduced, and language modeling surprisal estimates are converted to reading times using a conversion coefficient. Resulting predictions vastly overestimate the magnitude of garden-path effects in all settings, suggesting the presence of additional mechanisms besides predictability in shaping cognitive processing in the presence of ambiguous constructions like garden-path sentences. This evidence is further supported by the second experimental perspective, in which reading times for garden-path sentences are predicted by models fine-tuned on eye-tracking annotations on corpora containing standard constructions. Results suggest that predicted gaze metrics poorly estimate the presence of garden-path effects over disambiguating regions, suggesting that fine-tuned models are once again incapable of out-of-the-box generalization beyond training settings.
References
Elman, Jeffrey L. 1991. “Distributed Representations, Simple Recurrent Networks, and Grammatical Structure.” Machine Learning 7 (2-3). Springer: 195–225.
Futrell, Richard, Ethan Wilcox, Takashi Morita, Peng Qian, Miguel Ballesteros, and Roger Levy. 2019. “Neural Language Models as Psycholinguistic Subjects: Representations of Syntactic State.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 32–42. Minneapolis, Minnesota: Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1004.
Gauthier, Jon, Jennifer Hu, Ethan Wilcox, Peng Qian, and Roger Levy. 2020. “SyntaxGym: An Online Platform for Targeted Evaluation of Language Models.” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, 70–76. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-demos.10.
Grodner, Daniel, Edward Gibson, Vered Argaman, and Maria Babyonyshev. 2003. “Against Repair-Based Reanalysis in Sentence Comprehension.” Journal of Psycholinguistic Research 32 (2). Springer: 141–66.
Gulordava, Kristina, Piotr Bojanowski, Edouard Grave, Tal Linzen, and Marco Baroni. 2018. “Colorless Green Recurrent Networks Dream Hierarchically.” In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 1195–1205. New Orleans, Louisiana: Association for Computational Linguistics. https://doi.org/10.18653/v1/N18-1108.
Hale, John. 2001. “A Probabilistic Earley Parser as a Psycholinguistic Model.” In Second Meeting of the North American Chapter of the Association for Computational Linguistics.
Hu, Jennifer, Jon Gauthier, Peng Qian, Ethan Wilcox, and Roger Levy. 2020. “A Systematic Assessment of Syntactic Generalization in Neural Language Models.” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 1725–44. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.158.
Lan, Zhenzhong, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2020. “ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations.” In International Conference on Learning Representations. https://openreview.net/forum?id=H1eA7AEtvS.
Levy, Roger. 2008. “Expectation-Based Syntactic Comprehension.” Cognition 106 (3). Elsevier: 1126–77.
Linzen, Tal, Emmanuel Dupoux, and Yoav Goldberg. 2016. “Assessing the Ability of Lstms to Learn Syntax-Sensitive Dependencies.” Transactions of the Association for Computational Linguistics 4. MIT Press: 521–35.
Mikolov, Tomas, M. Karafiát, L. Burget, J. Cernocký, and S. Khudanpur. 2010. “Recurrent Neural Network Based Language Model.” In INTERSPEECH.
Prasad, Grusha, and Tal Linzen. 2019a. “Do Self-Paced Reading Studies Provide Evidence for Rapid Syntactic Adaptation?” PsyArXiv Pre-Print. https://tallinzen.net/media/papers/prasad_linzen_2019_adaptation.pdf.
Prasad, Grusha, and Tal Linzen. 2019b. “How Much Harder Are Hard Garden-Path Sentences Than Easy Ones?” OSF Preprint syh3j. https://osf.io/syh3j/.
Radford, A., Jeffrey Wu, R. Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. “Language Models Are Unsupervised Multitask Learners.” OpenAI Blog. OpenAI.
Schijndel, Marten van, and Tal Linzen. 2020. “Single-Stage Prediction Models Do Not Explain the Magnitude of Syntactic Disambiguation Difficulty.” PsyArXiv Pre-Print sgbqy. https://psyarxiv.com/sgbqy/.
Sturt, Patrick, Martin J Pickering, and Matthew W Crocker. 1999. “Structural Change and Reanalysis Difficulty in Language Comprehension.” Journal of Memory and Language 40 (1). Elsevier: 136–50.
The
gpt2,gpt2-xlandalbert-base-v2pre-trained models from 🤗transformers(Wolf et al. 2020).↩Similar plots are available on the SyntaxGym website: http://syntaxgym.org/viz/individual↩