Abstract
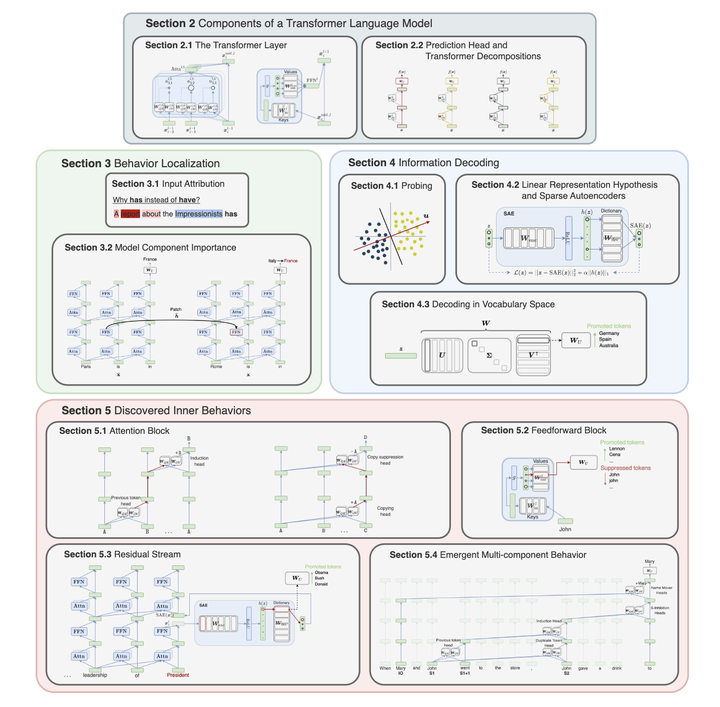
The rapid progress of research aimed at interpreting the inner workings of advanced language models has highlighted a need for contextualizing the insights gained from years of work in this area. This primer provides a concise technical introduction to the current techniques used to interpret the inner workings of Transformer-based language models, focusing on the generative decoder-only architecture. We conclude by presenting a comprehensive overview of the known internal mechanisms implemented by these models, uncovering connections across popular approaches and active research directions in this area.
Type
Publication
Arxiv Preprint