That Looks Hard: Characterizing Linguistic Complexity in Humans and Language Models
Abstract
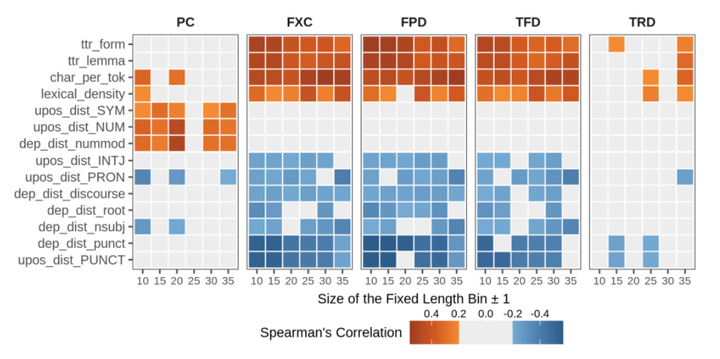
This paper investigates the relationship between two complementary perspectives in the human assessment of sentence complexity and how they are modeled in a neural language model (NLM). The first perspective takes into account multiple online behavioral metrics obtained from eye-tracking recordings. The second one concerns the offline perception of complexity measured by explicit human judgments. Using a broad spectrum of linguistic features modeling lexical, morpho-syntactic, and syntactic properties of sentences, we perform a comprehensive analysis of linguistic phenomena associated with the two complexity viewpoints and report similarities and differences. We then show the effectiveness of linguistic features when explicitly leveraged by a regression model for predicting sentence complexity and compare its results with the ones obtained by a fine-tuned neural language model. We finally probe the NLM’s linguistic competence before and after fine-tuning, highlighting how linguistic information encoded in representations changes when the model learns to predict complexity.