2 Models of Linguistic Complexity
Standard linguistic complexity studies analyze complexity annotations produced by human subjects to evaluate how specific language structures influence our perception of complexity under various viewpoints. For example, one can derive insights about early cognitive processing by looking at early gaze metrics, like first pass duration and first fixation duration, or study language comprehension by evaluating perceived complexity annotations. These approaches rely on a single implicit assumption: that complexity annotations contain enough information to reflect the input’s underlying complexity properties appropriately. Without this premise, there would be a complete disconnect between human subjective perception, as reflected by annotations and linguistic structures. Given the ever-growing compelling evidence derived from carefully-planned complexity research, I argue that this is a relatively safe assumption to be made.
This work instead adopts a modeling-driven approach for the study of linguistic complexity. Annotations produced by human subjects still play a fundamental role in this context. However, instead of acting as the main subject of analysis, they are used as a source of distant supervision to create computational models of linguistic complexity. More specifically, machine learning models are trained to predict complexity annotation from raw input text by minimizing a task-specific loss function. The learning step here is fundamental, given the connection mentioned above between linguistic complexity and knowledge acquisition. After the training process, human annotations are put aside, and the model itself is studied as a complexity-sensitive subject: in particular, this study focuses on how the information encoded in the parameters of complexity-trained models is related to structural linguistic properties (Chapter 3), how this information differs when models are exposed to different complexity perspectives during training (Chapter 4) and finally how the encoded knowledge affects models’ generalization capabilities over unseen constructs (Chapter 5).
While this approach still relies on the annotation pertinence assumption stated above, it requires making a second, stronger hypothesis: that models employed can grasp a significant portion of the relations subsisting between language structures and complexity perspectives. This assumption can be further declined in two requirements. First, from a conceptual point-of-view, we must ensure that the model architecture is endowed with meaningful inductive biases concerning what is currently known about linguistic complexity. This includes having sufficient approximation capabilities to capture linguistic complexity phenomena, which are likely to be highly-nonlinear functions of the input. From a functional perspective, then, we should confirm that the quality of model predictions is sufficiently close to human-produced annotations to make their production mechanisms worth investigating.
This chapter justifies the selected modeling approach and introduces models later employed in complexity assessment experiments. Section 2.1 discusses the conceptual requirements for linguistic complexity modeling and motivates the choice of pretrained neural language models as primary subjects of this thesis work. Section 2.2 presents the architectures used in experimental sections and their desirable properties regarding the encoding of linguistic structures in latent representations. Finally, Section 2.3 presents the challenge of interpreting NLM’s representations and behaviors and introduces various interpretability approaches used throughout this study.
2.1 Desiderata for Models of Linguistic Complexity
From the in-depth analysis of Chapter 1, we can distill some general desiderata for an idealized LCA model \(M^*\). From a linguistic perspective:
\(M^*\) should distinguish between lexical forms and be informed about their probability of occurrence. This is a basic (although fundamental) step given the importance of words’ variety and frequency in determining our perception of complexity.
\(M^*\) should be aware of syntactic structures and sensitive to their properties. As we saw with garden-path sentences, atypical or ambiguous syntax constructs are among the most prominent factors for determining the magnitude of processing difficulties. An ideal model should map complex syntactic constructs to higher complexity scores and discriminate potentially ambiguous or problematic structures from regular ones, even when changes in the form are minimal (e.g., when a single comma is missing).
\(M^*\) should capture semantic information and relations between entities. Ideally, this means the ability to frame agents, patients, and actions in a semantic context and evaluate how likely or typical the latter is. For example, semantically unrelated entities occurring together in a sentence should produce an increase in processing difficulties. This includes the ability to disambiguate polysemic terms (e.g., “fly” verb vs. noun) given the surrounding context.
Then, from a technical standpoint:
\(M^*\) should not rely on hand-crafted features to represent language. This is an implicit requirement since this study aims to analyze how the model autonomously learns to represent language in its parameters while simultaneously encoding information about its complexity. Chapter 3 presents how complexity models with hand-crafted features compare to those selected for the study.
\(M^*\) should not rely too heavily on labeled data. Complexity datasets presented in Chapter 1 are usually composed of a few thousand labeled examples. While this may seem a lot to our eyes, a language model may require a lot more information to achieve sufficient generalization capabilities. A viable option in this context, as we will see with NLMs, is to prime models with general linguistic knowledge through an unsupervised pretraining procedure before training them on complexity-related tasks.
\(M^*\) should be sufficiently interpretable. Ideally, we would like to draw direct causal relations from input properties to complexity prediction in a consistent way across complexity perspectives. More realistically, we need at least to find coherent patterns between the model’s inputs and its predictive behaviors.
Most standard modeling approaches fail to encompass even a small subset of those non-trivial requirements. For example, one can consider modeling complexity properties with static word representations (Turian, Ratinov, and Bengio 2010) such as Word2Vec or GloVe embeddings (Mikolov et al. 2013; Pennington, Socher, and Manning 2014). In these approaches, feature vectors representing words are learned by a neural network through a pretraining procedure to model word co-occurrences. While these approaches were shown to capture a significant amount of semantic information while reducing the dependence on labeled data thanks to pretraining, static word embeddings generally yield modest results when employed for syntactic predictions (Andreas and Klein 2014). Moreover, since the model learns a direct mapping \(f: t_i \rightarrow \textbf{v}_i\) from lexical forms to vectorial representations, polysemic terms are reduced to single context-independent representation, and contextual information that often plays a crucial role in determining complexity is mixed and diluted.
Among more sophisticated modeling approaches for representing language, I argue that modern neural language models (NLMs) are the approaches that yield a better match for the requirements stated above. These models consist of multi-layer neural networks (Goodfellow et al. 2016) pretrained using standard language modeling or masked language modeling training objectives to produce contextualized word embeddings, which were shown to be very effective in downstream syntactic and semantic tasks (Peters et al. 2018) even with relatively few labeled examples. Moreover, being language models, NLMs predict a probability distribution over their vocabulary at each step, enabling us to compute information-theoretic metrics such as surprisal that we saw being conceptually close to one-stage cognitive processing accounts. Finally, their high parameter counts and the presence of self-attention mechanisms (Bahdanau, Cho, and Bengio 2015; Vaswani et al. 2017) as learned weighting functions suggests that NLMs might be capable of learning to approximate highly nonlinear functions effectively.
The most significant downside of NLMs in the context of our analysis is their opaqueness. As for most neural networks, the nonlinear multi-layer structure that characterizes NLMs makes them incredibly valid function approximators. At the same time, though, it hinders our efforts in interpreting their behaviors (Samek et al. 2019). Because of this fact, in recent years, we witnessed a surge in approaches trying to “open the black box” of neural networks by using various techniques borrowed from information theory (Shwartz-Ziv and Tishby 2017) and cognitive science (Kriegeskorte, Mur, and Bandettini 2008). Given the wide availability of these approaches, this work joins the choir of interpretability researchers and argues that studying how such performant models encode their knowledge about language complexity is still a matter of interest and worth exploring. In the next section, the architecture and training process of NLMs will be formalized, and their properties will be described in detail.
2.2 Neural Language Models: Unsupervised Multitask Learners
The objective of natural language processing applications such as summarization, machine translation, and dialogue generation is to produce text that is both fluent and contextually accurate. As we saw in Chapter 1, a text’s fluency can also be used as a significant factor in determining its complexity from a linguistic viewpoint. A possible approach to establishing a sentence’s fluency is to rely on relative frequency estimates for words in large corpora. Consider a sentence \(s\) and a large corpus \(\mathcal{C}\). We can estimate its probability of occurrence in natural language as:
\[\begin{equation} P(s) = \frac{\text{count}(s)}{|\mathcal{C}|} \end{equation}\]
While this is an unbiased estimator since it converges to the actual frequency value when the corpus size is sufficiently large, it is both very data-reliant and highly unreliable. If a sentence happens to be absent in \(\mathcal{C}\), it will be assigned probability equal to zero. Therefore, we need to rely on other approaches, such as language models, to obtain reliable estimates from limited training datasets.
As we saw in Chapter 1.2.2, language models assign probabilities to sequences of tokens. Formally, this can be framed as learning words’ conditional probability distributions given their context, either preceding or bidirectional depending on the language modeling approach. I will here refer to sequential language models unless otherwise mentioned.
Language models are trained on sequences \(\textbf{x} = \langle x_1, \dots, x_n \rangle\) composed by \(n\) tokens taken from a predefined vocabulary \(\mathcal{V}\). Each token \(x_i\) can be represented as a one-hot encoded vector \(x_i \in \{0,1\}^{|\mathcal{V}|}\), and the probability of sequence \(\textbf{x}\) is factored using the chain rule:
\[\begin{equation} P(\textbf{x}) = \prod_{t=1}^{n}\,P(x_t\,|\,x_1,\dots,x_{t-1}) \end{equation}\]
After the training process, we can use the likelihood that the model assigns to held-out data \(\textbf{y}\) treated as a single stream of \(m\) tokens as an intrinsic evaluation metric for the quality of its predictions:
\[\begin{equation} \ell(\textbf{y}) = \sum_{t=1}^m \log P(x_t|x_1,\dots,x_{t-1}) \end{equation}\]
\(\ell(\textbf{y})\) can be rephrased in terms of perplexity, an information-theoretic metric independent from the size of the held-out set:
\[\begin{equation} \text{PPL}(\textbf{y}) = 2^{-\ell(\textbf{y})/m} \end{equation}\]
\(\text{PPL}\) is equal to 1 if the language model is perfect (i.e., predicts all tokens in the held-out corpus with probability 1) and matches the vocabulary size \(|\mathcal{V}|\) when the model assign a uniform probability to all tokens in the vocabulary (a “random” language model):
\[\begin{align} \log_2(\textbf{y}) = \sum_{t=1}^m \log_2 \frac{1}{|\mathcal{V}|} = - \sum_{t=1}^m \log_2 |\mathcal{V}| = -m \log_2 |\mathcal{V}| \\ \text{PPL}(\textbf{y}) = 2^{\frac{1}{m}m\log_2 |\mathcal{V}|} = 2^{\log_2 |\mathcal{V}|} = |\mathcal{V}| \end{align}\]
Perplexity represents the number of bits required to encode the average word in the corpora. For example, reporting a perplexity score of 10 over a held-out corpus means that the language model will predict on average words with the same accuracy as if it had to choose uniformly and independently across ten possibilities for each word.
While tokens used by language models generally correspond to words in most NLP pipelines, recent language modeling work highlighted the effectiveness of using subword tokens (Sennrich, Haddow, and Birch 2016; Wu et al. 2016; Kudo and Richardson 2018) or even single characters to further improve LM’s generalization performances. In particular, models used in this work rely on SentencePiece and Byte-Pair Encoding (BPE) subword tokenization (Sennrich, Haddow, and Birch 2016; Kudo and Richardson 2018). The SentencePiece algorithm derives a fixed-size vocabulary from word co-occurrences in a large corpus and treats whitespace as a normal symbol by converting it to “_”, while BPE does the same using the “Ġ” character. For example:
Input sentence: Heteroscedasticity is hard to model!
SentencePiece tokenization: _Hetero s ced astic ity _is _hard _to _model !
BPE tokenization: H eter os ced astic ity Ġis Ġhard Ġto Ġmodel !
where whitespaces correspond to separators after tokenization. From the example, we can observe that frequent words like hard, to and model are treated similarly by both tokenizers, while rare words like heteroscedasticity are split into subwords depending on their observed frequency inside the tokenizer’s training corpus.
In recent years n-gram language models, which were the most common approach to estimate probabilities from relative frequencies, have been largely supplanted by neural networks. A significant advantage of neural approaches is the overcoming of context restrictions: relevant information can be incorporated from arbitrarily distant contexts while preserving the tractability of the problem from both a statistical and a computational viewpoint.
Neural language models treat language modeling as a discriminative learning task aimed at maximizing the log conditional probability of a corpus. Formally, the probability distribution \(p(x|c)\) is reparametrized as the dot product of two dense numeric vectors \(\boldsymbol\theta_x, \boldsymbol h_c \in \mathbb{R}^H\) under a softmax transformation:
\[\begin{equation} P(x|c) = \frac{\exp(\boldsymbol\theta_x \cdot \boldsymbol h_c)}{\sum_{x'\in\mathcal{V}} \exp(\boldsymbol\theta_{x'} \cdot \boldsymbol h_c)} \tag{2.1} \end{equation}\]
In (2.1), the denominator is present to ensure that the probability distribution is properly normalized over vocabulary \(\mathcal{V}\). \(\boldsymbol\theta_x\) represent model parameters that can be learned through an iterative procedure, while \(\boldsymbol h_c\) is the contextual information that can be computed in different ways depending on the model. For example, a neural language model based on the recurrent neural network architecture (RNN; Mikolov et al. (2010)) recurrently updates context vectors initialized at random with relevant information that needs to be preserved while moving through the sequence.10
This work leverages models belonging to the most recent and influential family of neural language models at the time of writing, that is, the one based on the Transformer architecture (Vaswani et al. 2017). Transformers are deep learning models designed to handle sequential data and were conceived to compensate for a significant downside of recurrent models: the need to process data in an orderly manner to perform backpropagation through time. By replacing recurrent computations with attention mechanisms to maintain contextual information throughout the model, Transformers’ operations are entirely parallelizable on dedicated hardware and therefore lead to reduced training times. This fact is especially relevant considering the massive corpora size used to pretrain neural language models to obtain contextual representations. Self-attention was also shown to behave better than other approaches at learning long-range dependencies, avoiding the vanishing gradient problem that plagued non-gated recurrent NLMs altogether (Pascanu, Mikolov, and Bengio 2013).
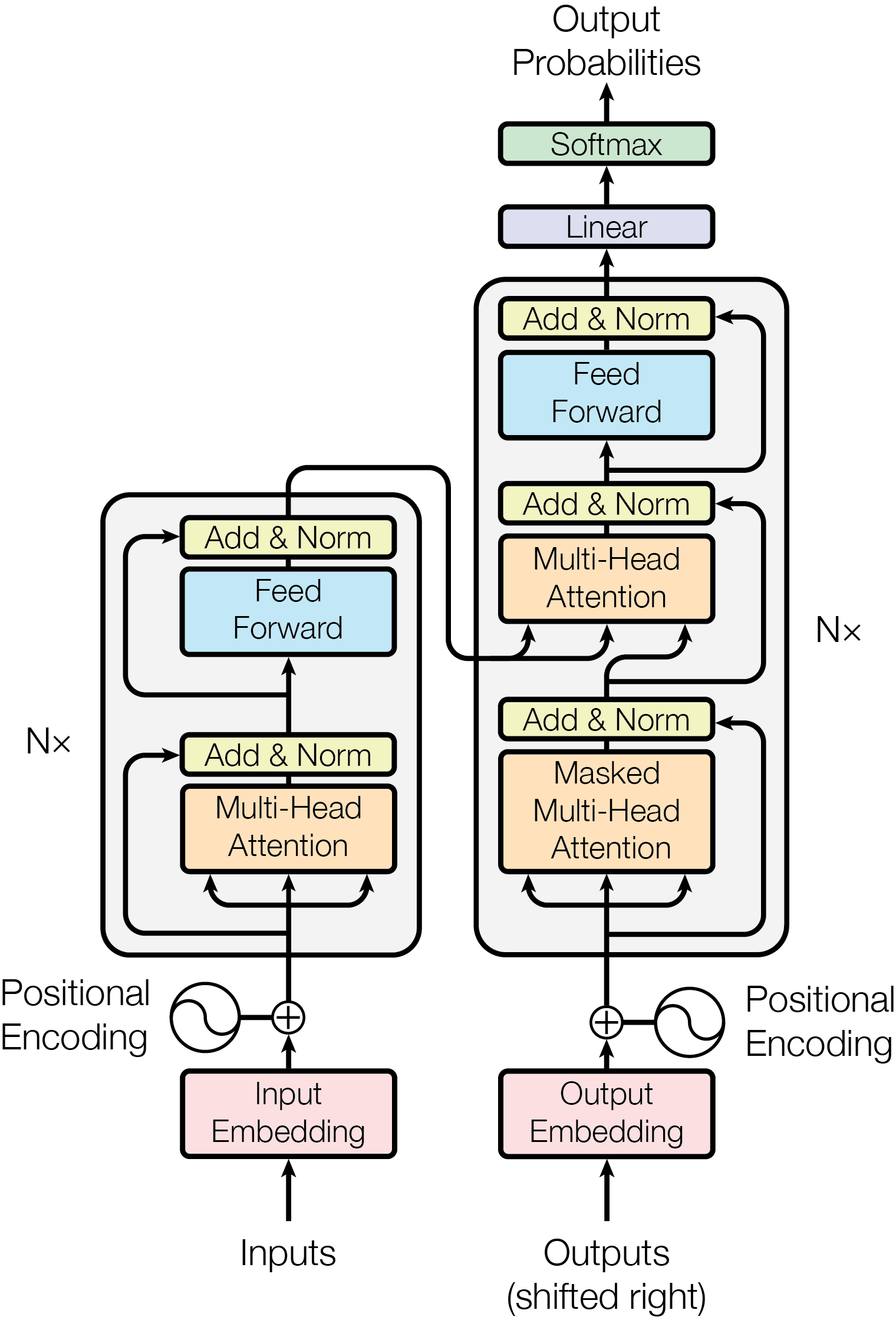
Figure 2.1: The original Transformer model architecture by Vaswani et al. (2017).
The original Transformer architecture comprises an encoder and a decoder, each composed of a stacked sequence of identical layers that transform input embeddings in outputs with the same dimension (hence the name). First, the encoder maps the sequence \((x_1, \dots, x_n)\) to a sequence of embeddings \(\boldsymbol z = (z_1, \dots, z_n)\). Given \(\boldsymbol z\), the decoder then autoregressively produces an output token sequence \((y_1, \dots, y_m)\). Each layer of the Transformer encoder comprises two sublayers, a multi-head self-attention mechanism and a feed-forward network, surrounded by residual connections and followed by layer normalization. The decoder includes a third layer that performs multi-head self-attention over the encoder output and modifies the original self-attention sublayer to prevent attending to future context, as required by the language modeling objective. Figure 2.1 presents the original architecture for a \(N\)-layer Transformer. I will now proceed to describe the main components of the Transformer model.
Positional Encodings The original Transformer relies on two sets of embeddings to represent the input sequence: learned word embeddings, used as vector representations for each token in the vocabulary, and fixed positional encodings (PEs) used to inject information about the position of tokens in the sequence. Those are needed since no information about the sequential nature of the input would otherwise be preserved. For position \(pos\) and dimension \(i\), PEs correspond to sinusoidal periodic functions that were empirically shown to perform on par with learned embeddings, and were chosen to enable extrapolation for longer sequences:
\[\begin{align} PE_{pos, 2i} = \sin(\text{pos}/10000^{2i/|h|}) \\ PE_{pos, 2i + 1} = \cos(\text{pos}/10000^{2i/|h|}) \end{align}\]
where \(|h|\) is the model’s hidden layer size. Embeddings and PEs are summed and passed to the attention layer.
Self-Attention The scaled dot-product self-attention mechanisms is the driving force of the Transformer architecture. Given an input embedding matrix \(X\), we multiply it by three weight matrices \(W^Q, W^K, W^V\) obtaining the projections \(Q\) (queries), \(K\) (keys) and \(V\) (values). Those are then combined by the self-attention function as follows:
\[\begin{equation} \text{Attention(Q,K,V)} = \text{softmax}\Big ( \frac{QK^T}{\sqrt{d_k}}\Big)V \end{equation}\]
where \(d_k\) is the size of individual query and key vectors. The output of this operation is a matrix \(Z\) which will be passed to the feed-forward layer. The self attention mechanism is further extended to multi-head self-attention in Transformer architectures. In the multi-head variant, the attention function is applied in parallel to \(n\) version of queries, keys and values projected with learned parameter matrices, and outputs are finally concatenated and projected again to obtain final values:
\[\begin{align} \text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1,\dots, \text{head}_n)W^O \\ \text{where } \text{head}_i = \text{Attention}(QW_i^Q,KW_i^K,VW_i^V) \end{align}\]
Where \(W_i^Q \in \mathbb{R}^{|h| \times d_k}\), \(W_i^K \in \mathbb{R}^{|h| \times d_k}\), \(W_i^V \in \mathbb{R}^{|h| \times d_v}\) and \(W^O \in \mathbb{R}^{nd_v \times |h|}\). In multi-head attention layers of Figure 2.1, each position can attend to all position from the previous layer, while in the masked multi-head attention layer only previous positions in the sequence can be attended by applying a triangular mask to attention matrices. This additional step is needed to preserve the autoregressive property during decoding.
Feed-forward Layer Each block in the encoder and the decoder contains an independent fully connected 2-layer feed-forward network with a ReLU nonlinearity applied separately to each position of the sequence:
\[\begin{equation} \text{FFN}(Z) = \max(0,Z\,\Theta_1 + b_1)\Theta_2 + b_2 \end{equation}\]
where \(Z\) are the representations passed forward from the attention sublayer, \(\Theta_1, \Theta_2\) are two learned independent parameter matrices for each layer and \(b_1, b_2\) are their respective bias vectors.
Now that the main concepts regarding the Transformer architecture have been introduced, the two Transformer-based models used in this study will be presented.
GPT-2 GPT-2 (Radford et al. 2019) is a transformer model built using only the decoder blocks with masked self-attention, alongside BPE tokenization. The latter’s autoregressive capabilities, i.e. being able to iteratively add a newly predicted token to the existing sequence in the next steps, make it especially suitable for text generation and related tasks. The learning of model parameters is performed in two stages. First, an unsupervised pretraining is carried out to learn a high capacity language model on a large corpus: in particular, here the model is trained to maximize the likelihood of sequential language modeling over WebText, a corpus containing roughly 8 million documents (40GB of text), by adapting its parameters using stochastic gradient descent. The purpose of this step is to learn contextual word embeddings encoding both low and high-level information that can be recycled in downstream tasks, following the transfer learning approach inspired by the field of computer vision and initially proposed by Howard and Ruder (2018) for NLP. The second step is a supervised fine-tuning, where the language modeling softmax layer is replaced by a task-specific layer (called head) with parameters \(W_y\) receiving final transformer activations \(h_l\) and predicting a label \(y\) (e.g. in a classification task) as:
\[\begin{equation} P(y|x_1,\dots, x_m) = \text{softmax}(h^{sent}_lW_y) \end{equation}\]
where \(h_l^{sent}\) is the sentence-level representation for \((x_1, \dots, x_m)\). The parameters of the whole model, including transformer blocks and task-specific heads, can then be tuned by minimizing the loss \(\mathcal{L}\) over the whole supervised corpus \(\mathcal{C}\):
\[\begin{equation} \mathcal{L}(\mathcal{C}) = - \sum_{(x,y)} \log P(y|x_1, \dots, x_m) \end{equation}\]
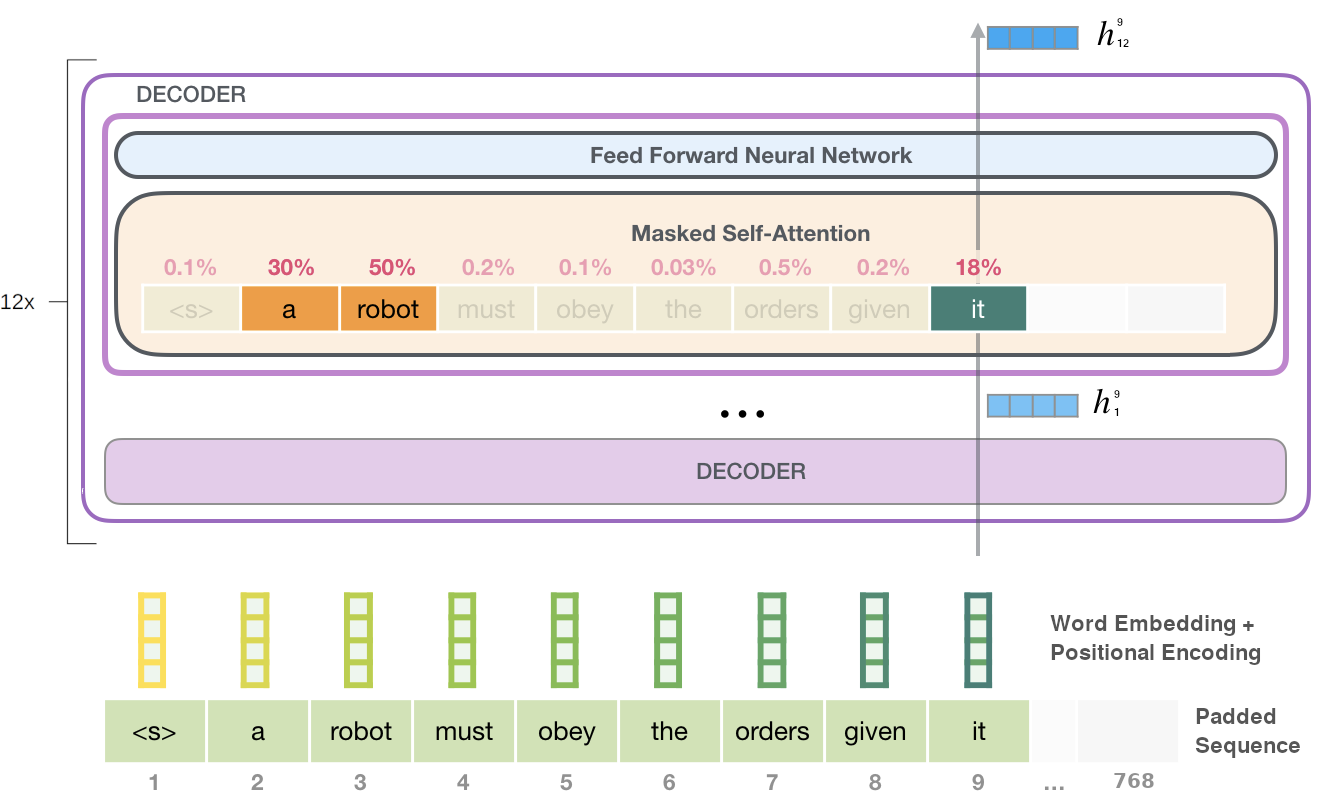
Figure 2.2 visualizes the forward pass through the GPT-2 architecture. We see from the figure that attention patterns learned during pre-trained are often interpretable. Here, the token it is correctly identified as the pronoun referring to the subject a robot. Authors show how large NLMs such as GPT-2 become strong unsupervised multitask learners when trained on sufficiently large corpora, providing the initial motivation for choosing pretrained Transformer models for experiments throughout this study. GPT-2 will be specifically be employed in the experiments of Chapter 5, where its autoregressive nature is ideal for replicating human surprisal estimates during sequential reading on garden-path sentences.
ALBERT ALBERT (Lan et al. 2020) is an efficient variant of the Bidirectional Encoder Representations from Transformers (BERT) approach by Devlin et al. (2019). BERT was built following the intuition that many sentence-level tasks would greatly benefit from an approach capable of incorporating bidirectional context inside language representations. This is not the case for decoder-based approaches like GPT-2 that, being aimed at generation-oriented tasks, could only leverage the previous context using masked self-attention. BERT tackles the unidirectional constraint by introducing masked language modeling (MLM, see Equation (1.2)) and using a stack of transformer encoder layers with GELU nonlinearities (Hendrycks and Gimpel 2016).
As for GPT-2, the pretraining and fine-tuning steps are taken to provide the model with general language knowledge and subsequently adapt it to specific downstream tasks. At each pretraining step, a fixed portion of input tokens get masked, and the model predicts the original vocabulary id of masked tokens. Moreover, a sentence-level task is used to improve discourse coherence. For BERT, the next sentence prediction (NSP) task is adopted, i.e. determining whether, given two sentences, they are consecutive or not in the original text using both positive and negative pairs. NSP was found unreliable by subsequent studies and was replaced in ALBERT by a sentence ordering prediction loss that is more challenging for the model. A third set of segment embeddings is added to initial representations to distinguish input sentences in multi-sentence tasks. Special tokens [CLS] and [SEP] are added as sentence-level representations.
ALBERT introduces two main contributions aimed at reducing the final number of model parameters inside BERT:
Factorized embedding parametrization: a projection layer is introduced between the embedding matrix \(E\) and the hidden layer \(H\) of the model so that the dimensions of the two are untied. This approach modifies embedding parameter count from \(O(|V| \times |E|)\) to \(O(|\mathcal{V}| \times |E| + |E| \times |h|)\), with \(|\mathcal{V}|, |E|, |h|\) being respectively the sizes of vocabulary, embedding vectors and hidden layers. A significant reduction in model parameters is therefore produce when \(|h| \gg |E|\), which is desirable since \(H\) contains context-dependent representations that encode more information than the context-independent ones of \(E\).
Cross-layer parameter sharing: All layers of ALBERT share the same set of feed-forward and self-attention parameters. Therefore, we can see ALBERT as an iterated function \(f_A^n: h \rightarrow h'\), where \(n\) is the number of encoder layers present in the model (in this study \(n=12\)), with parameters trained using end-to-end stochastic gradient descent.
Both factors significantly contribute to reducing the computational complexity of the model without affecting too much its performances: the ALBERT base used in all experimental chapters of this study have 9x fewer parameters than a regular BERT base model (12M vs. 108M) while performing comparably well on many natural language understanding benchmarks such as GLUE (Wang et al. 2018) and SQuAD (Rajpurkar et al. 2016).
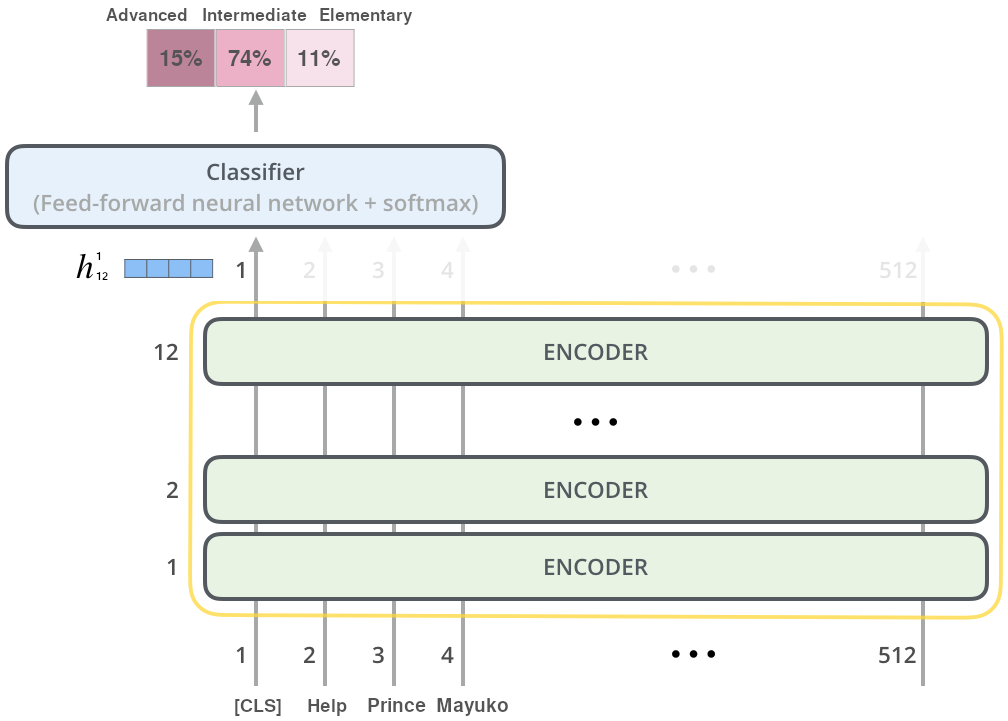
Figure 2.3 presents how a pretrained ALBERT model can be leveraged for sentence classification, using the ARA task as an example. We note that the procedure is the same as for GPT-2: a task-specific classification head is initialized with random weights, and the whole model-head architecture is fine-tuned on the target task end-to-end. The figure also shows how the common choice for BERT-based models is to use their [CLS] token \(h_{12}^{1}\) as the full-sentence representation equivalent \(h_{12}^{sent}\).
To conclude, the fine-tuning approach relying on a pretrained model “body” and a task-specific head adopted in both GPT-2 and ALBERT can be extended out-of-the-box to a multitask learning scenario. A multitask approach can prove useful when considering parallel annotations on the same corpus that provide similar but complementary information about a studied phenomenon’s nature. We can interpret this as an inductive bias that encourages finding knowledge representations to explain multiple sets of annotations at once.11 More specifically, multitask learning with hard parameter sharing (Caruana 1997) is performed in all experimental sections over eye-tracking scores to produce representations encompassing the whole set of phenomena related to natural reading. For doing so, each metric was associated with a task-specific head, and the whole set of heads was trained while sharing the same underlying model.
2.2.1 Emergent Linguistic Structures in Neural Language Models
This section presents evidence in support of the ability of pretrained language models to effectively encode language-related properties in their learned representations.12
Lin, Tan, and Frank (2019) were among the first to highlight how BERT representations encode hierarchical structures akin to syntax trees, despite the absence of syntactic information or recurrent biases during pretraining. Liu et al. (2019) and Tenney, Das, and Pavlick (2019) further showed that contextualized embeddings produced by BERT encode information about part-of-speech, entity roles, and partial syntactic structures.
Hewitt and Manning (2019) formulate the syntax distance hypothesis, assuming that there exists a linear transformation \(B\) of the word representation space under which vector distance encodes parse trees. They proceed to test this assumption equating L2 distance in the 2-dimensional space of representations projected by \(B \in \mathbb{R}^{2 \times |h|}\) and tree distances in parse trees, finding a close match between BERT representational space and Penn Treebank formalisms. The approach is visualized in Figure 2.4. Jawahar, Sagot, and Seddah (2019) work support these findings, highlighting a close match between BERT representation and dependency trees after testing multiple decomposition schemes. The syntax distance hypothesis’s validity is especially relevant to this work, given the aforementioned importance of syntactic properties in driving human subjects’ perception of complexity.
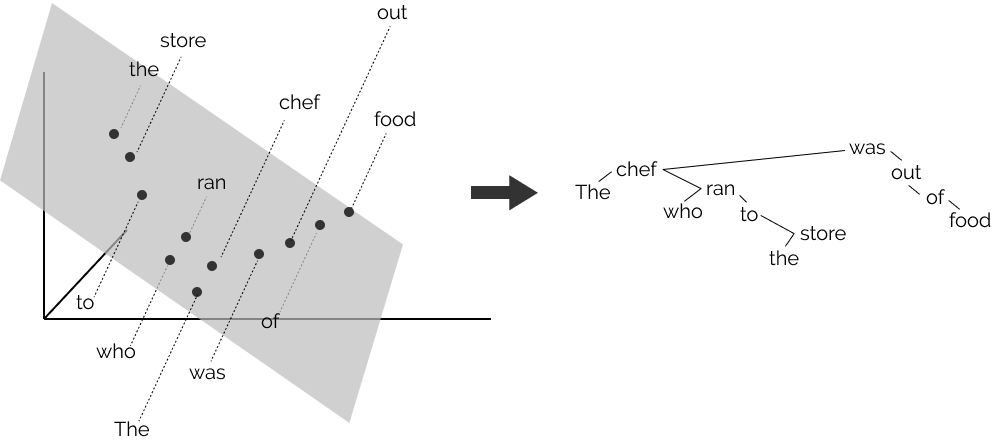
Figure 2.4: The mapping from 2D representation space to syntax tree distances adopted in Hewitt and Manning (2019).
Despite the evidence of syntactic knowledge in contextual word representations, recent results suggest that the model may not leverage this for its predictions. Ettinger (2020) highlights the insensitivity of BERT to negation and malformed inputs using psycholinguistic diagnostics commonly used with human subjects, while Wallace et al. (2019) show that nonsensical inputs do not affect the prediction quality of BERT, despite having a clear input on underlying syntactic structures. These results are coherent with the experimental findings of this study and will be further discussed in later sections.
2.3 Analyzing Neural Models of Complexity
Having introduced the model architectures that will be used throughout this study, we will now focus on the interpretability approaches allowing us to analyze and compare neural network representations.
When training deep neural networks, we would like to go beyond predictive performance and understand how different design choices and training objectives affect learned representations from a qualitative viewpoint. This fact is especially crucial in the model-driven approach adopted in this work, as stated at the end of Section 2.1. While for linear models, the direct correspondence between the magnitude of feature coefficients and feature importance provides us with some out-of-the-box insights about decision boundaries and feature importance, the hierarchical and nonlinear structure that characterizes neural networks produce model weights that are relatively uninformative when taken in isolation.
This work focuses on two interpretability perspectives: highlighting linguistic knowledge encoded in model representations (Chapter 3) and comparing representations across models trained on different complexity-related tasks (Chapter 4). For the first objective, probing classifiers, which have become the de-facto standard in the interpretability literature, are used to evaluate the amount of information encoded in each layer of the model.13 In the second case, two multivariate statistical analysis methods, namely representational similarity analysis and canonical correlation analysis, are leveraged to quantify the relation between model embeddings by evaluating their second-order similarity and learning a mapping to a shared low-dimensional space, respectively. The following sections conclude the chapter by presenting the three approaches in detail.
2.3.1 Probing classifiers
The probing task approach is a natural way to estimate the mutual information shared by a neural network’s parameters and some latent property that the model could have implicitly learned during training. During probing experiments, a supervised model (probe) is trained to predict the latent information from the network’s learned representations. If the probe does well, we may conclude that the network effectively encodes some knowledge related to the selected property.
Formally speaking, let \(f: x_i \rightarrow y_i\) be a neural network model mapping a corpus of input sentences \(X = (x_1, \dots, x_n)\) to a set of outputs \(Y = (y_1, \dots, y_n)\). Assume that each sentence \(x_i\) is also labeled with some linguistic annotations \(z_i\), reflecting the underlying properties we aim to detect. Let also \(h_l(x_i)\) be the network’s output at the \(l\)-th layer given the sentence \(x_i\) as input. To estimate the quality of representations \(h_l\) with respect to property \(z\), a supervised model \(g: h_l(x_i) \rightarrow z_i\) mapping representations to property values is trained. We take such model’s performances as a proxy of \(H(h_l(x),z)\). In information theoretic terms, the probe is trained to minimize entropy \(H(z|h_l(x))\), and by doing that it maximizes mutual information between the two quantities.
The probe \(g\) does not need to be a linear model. While historically simple linear probes were used to minimize the risk of memorization, recent results show that more complex probes produce tighter estimates for the actual underlying information (Pimentel et al. 2020). To account for the probe’s ability to learn the task through sheer memorization, Hewitt and Liang (2019) introduce control tasks using the performances of a probe exposed to random labels as baselines.
Alain and Bengio (2016) were among the first to use linear probing classifiers as tools to evaluate the presence of task-specific information inside neural networks’ layers. The approach was later extended to the field of NLP by Conneau et al. (2018) and Zhang and Bowman (2018) inter alia, which evaluated the presence of semantic and syntactic information inside sentence embeddings generated by LSTM encoders (Hochreiter and Schmidhuber 1997) pretrained on different objectives using probing task suites. Recently, Miaschi and Dell’Orletta (2020) showed how contextual representations produced by pretrained Transformer models could encode sentence-level properties within single-word embeddings. Moreover, Miaschi et al. (2020) highlighted the tendency of pretrained NLMs to lose general linguistic information during the fine-tuning process and found a positive relation between encoded linguistic information and the downstream performances of the model.
2.3.2 Representational Similarity Analysis
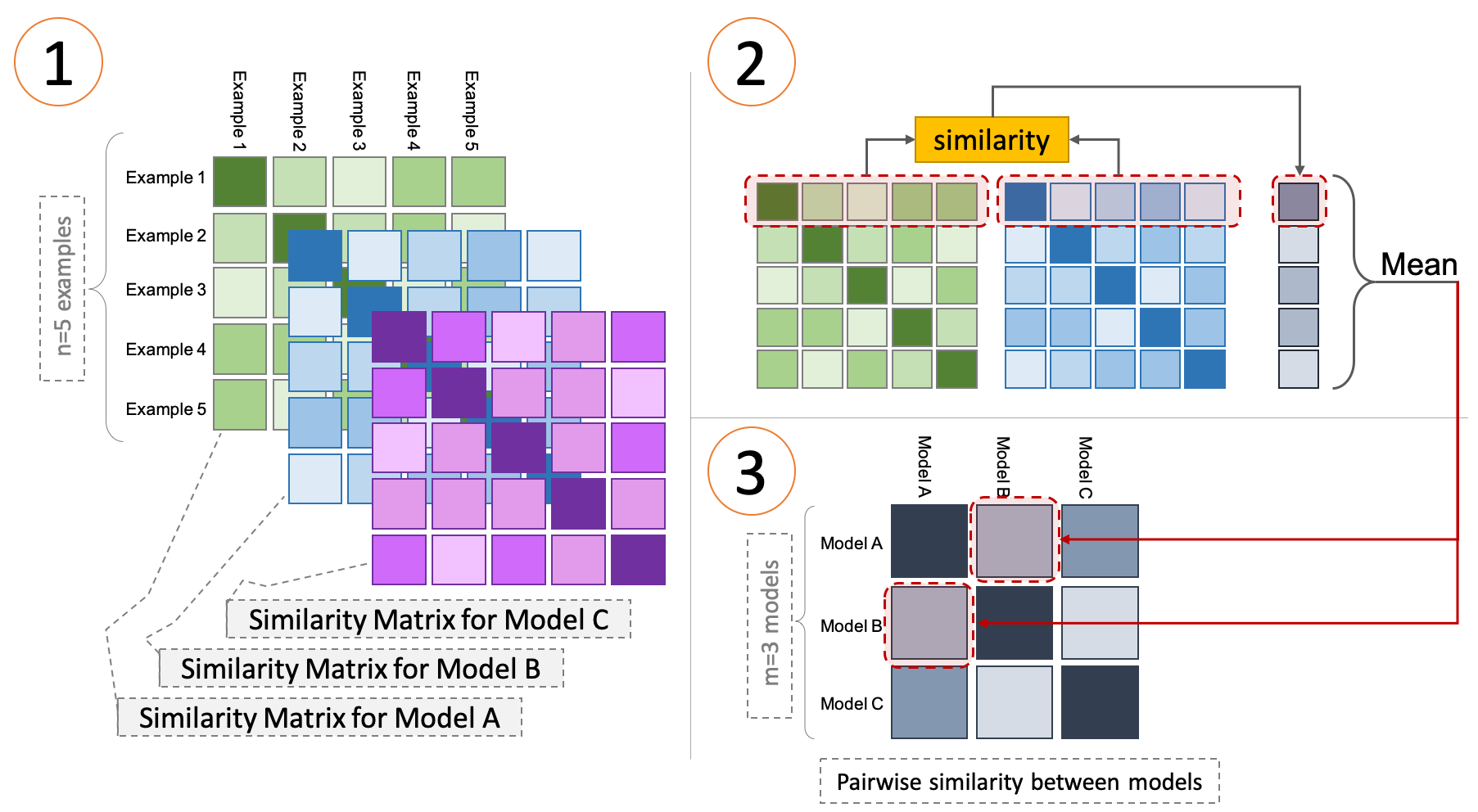
Figure 2.5: The Representational Similarity Analysis (RSA) algorithm applied to the representations of three models. Image taken from Abnar (2020).
Representational similarity analysis (RSA, Laakso and Cottrell (2000)) is a technique developed in the field of cognitive science to evaluate the similarity of fMRI responses in selected regions of the brain after a stimulus (Kriegeskorte, Mur, and Bandettini 2008). The technique can be extended to compare the heterogeneous representational spaces formed by a set of computational models \(m\) exposed to a shared set of observations. Figure 2.5 visualizes the approach. First, each model is fed with a shared corpus of \(n\) sentences to produce a set of matrix embeddings \((E^1, \dots, E^m)\), where \(E^i_j\) represents the embedding produced by the last layer of the \(i\)-th model on the \(j\)-th sentence of the corpus.14 Next, for each matrix \(E^i\) a representational distance matrix \(S^i\) is produced such that \(S^i_{j,k} = \text{sim}(E^i_j, E^i_k),\;S^i \in \mathbb{R}^{n \times n}\) where \(\text{sim}_1\) is a similarity function (here, dot product). \(S_i\) encodes information on the similarity subsisting between model activations across different observations. Finally, a second-level representational similarity matrix \(S'\) is computed, where for each pair of matrices \((S^i, S^j)\) the corresponding \(S'_{i,j}\) entry has value:
\[\begin{equation} S'_{i,j} = S'_{j,i} = \frac{1}{n}\sum_{k=1}^n \text{sim}_2\big(\,\eta\,(S^i_k),\eta\,(S^j_k)\big) \end{equation}\]
where \(\eta\) is the L1 normalization function and \(\text{sim}_2\) is a similarity function (here, Pearson’s correlation coefficient). Each entry \(S'_{i,j}\) corresponds to a similarity score between activity patterns of model \(i\) and model \(j\) across the entire set of \(n\) observations.
In the context of NLP, Abnar et al. (2019) recently used RSA to compare the activations of multiple neural language models and evaluated the impact of parameter values on the representations formed by a single model. Interestingly, they also use RSA to compare fMRI imaging data collected from human subjects and NLMs activations. Abdou et al. (2019) use RSA to highlight the connection between processing difficulties (measured by high gaze metrics values) and the representational divergence, both inter and intra-encoder. Abnar, Dehghani, and Zuidema (2020) visualize training paths of various neural network architectures as 2D projections of RSA and show how different inductive biases can be transferred across network categories using knowledge distillation (Hinton, Vinyals, and Dean 2015).
2.3.3 Projection-Weighted Canonical Correlation Analysis
Canonical correlation analysis (CCA, Thompson (1984)) is a statistical technique for relating two sets of observations arising from an underlying unknown process. In the context of this work, the underlying process is represented by NLMs being trained on complexity-related tasks. Given a corpus of sentences \(X = (x_1, \dots, x_m)\) annotated with complexity labels, we have that \(\boldsymbol z^l_ = (z_i^l(x_1), \dots z_i^l(x_m))\) corresponds to all activations of neuron \(z_i\) at layer \(l\) stacked to form a vector.15 If we consider all activations of all neurons in a layer \(L_i = (z^i_1, \dots, z^i_n)\) for all inputs, we can represent them as a matrix \(A_i \in \mathbb{R}^{m \times n}\), i.e. a set of multidimensional variates where \(n\) is the number of neurons in the layer. The CCA algorithm aims to identify the best (i.e. most correlated) linear relationship under mutual orthogonality and norm constraints between two sets of multidimensional variates, which in this case are activation matrices like \(L_1\). This approach was used, among other things, to study the coherence between modeled and real brain activations (Sussillo et al. 2015).
Formally, if we have two activation matrices \(A_1, A_2 \in \mathbb{R}^{m \times n}\) we aim to find vectors \(w, v \in \mathbb{R}^m\) such that the correlation:
\[\begin{equation} \rho = \frac{\langle w^TA_1, v^TA_2 \rangle}{\|w^TA_1\| \cdot \| v^T A_2\|} \end{equation}\]
is maximized. The formula can be solved by changing the basis and recurring to singular value decomposition. The output of CCA is a set of singular pairwise orthogonal vectors \(u, v\) and their canonical correlation coefficients \(\rho \in [0,1]\) representing the correlation of vectors \(w^TA_1\) and \(v^TA_2\).
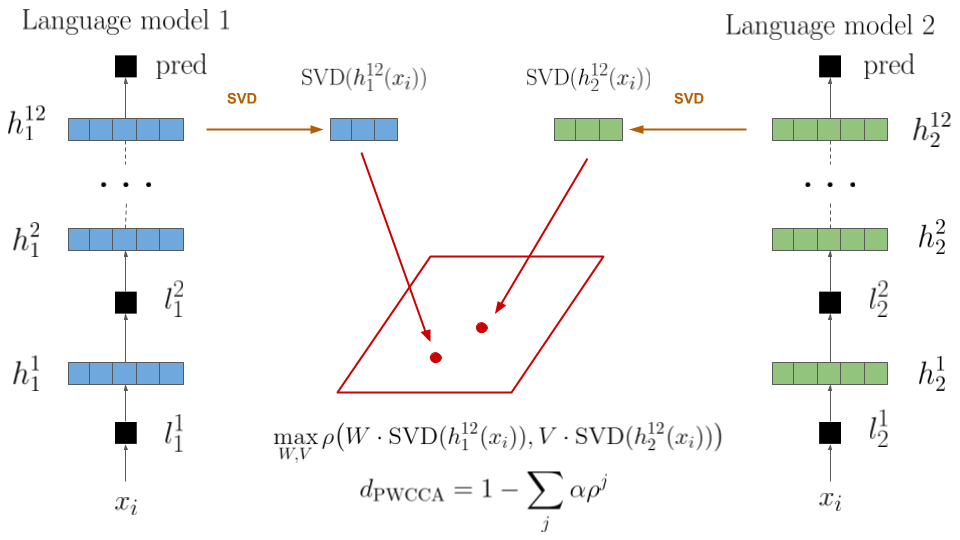
Figure 2.6: Projection-Weighted Canonical Correlation Analysis (PWCCA) applied to last-layer representations of two language models.
The SVCCA method (Raghu et al. 2017) extends the CCA approach for deep learning research by pruning neurons through a singular value decomposition step before computing canonical correlation coefficients. As the authors mention, “This is especially important in neural network representations, where as we will show many low variance directions (neurons) are primarily noise”. Then, the similarity between two layers \(L_1, L_2\) is computed as the mean correlation coefficient produce by SVCCA, and adapted to a distance measure for evaluation: \[\begin{equation} d_{\text{SVCCA}}(A_1, A_2) = 1 - \frac{1}{|\rho|} \sum_{i=1}^{|\rho|} \rho^{(i)} \end{equation}\] Morcos, Raghu, and Bengio (2018) suggest that the equal importance given to all the \(|\rho|\) SVCCA vectors during the final averaging step may be problematic since it has been extensively shown that overparametrized neural networks often do not recur to their full dimensionality for representing solutions (Frankle and Carbin 2018). They suggest replacing the mean with a weighted mean: \[\begin{equation} d_{\text{PWCCA}}(A_1, A_2) = 1 - \sum_{i=1}^{|\rho|} \alpha \rho^{(i)} \;\;\text{with} \;\; \tilde \alpha_i = \sum_j |\langle h_i, x_j \rangle| \end{equation}\] where weights \(\alpha\) corresponds to the portion of inputs \(x\) accounted for by CCA vectors \(h\) and \(\tilde \alpha_i\) values are normalized such that \(\sum_i \alpha_i = 1\). The resulting approach, projection-weighted canonical correlation analysis (PWCCA), is used in this study and was shown to be much more robust than SVCCA to filter noise in activations. Figure 2.6 visualizes the selected approach.
Notable applications of CCA-related methods in NLP are Saphra and Lopez (2019), where SVCCA is used to study the evolution of LSTM language models’ representations during training, and Voita, Sennrich, and Titov (2019), where PWCCA is used to compare Transformer language models across layers and pretraining objectives.
References
Abdou, Mostafa, Artur Kulmizev, Felix Hill, Daniel M. Low, and Anders Søgaard. 2019. “Higher-Order Comparisons of Sentence Encoder Representations.” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (Emnlp-Ijcnlp), 5838–45. Hong Kong, China: Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1593.
Abnar, Samira. 2020. “Visualizing Model Comparison.” Blog Post. https://samiraabnar.github.io/articles/2020-05/vizualization.
Abnar, Samira, Lisa Beinborn, Rochelle Choenni, and Willem Zuidema. 2019. “Blackbox Meets Blackbox: Representational Similarity & Stability Analysis of Neural Language Models and Brains.” In Proceedings of the 2019 Acl Workshop Blackboxnlp: Analyzing and Interpreting Neural Networks for Nlp, 191–203. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/W19-4820.
Abnar, Samira, Mostafa Dehghani, and Willem Zuidema. 2020. “Transferring Inductive Biases Through Knowledge Distillation.” ArXiv Pre-Print 2006.00555. https://arxiv.org/abs/2006.00555.
Alain, Guillaume, and Yoshua Bengio. 2016. “Understanding Intermediate Layers Using Linear Classifier Probes.” ArXiv Pre-Print 1610.01644. https://arxiv.org/abs/1610.01644.
Alammar, Jay. 2018a. “The Illustrated Bert, Elmo, and Co. (How NLP Cracked Transfer Learning).” Blog Post. https://jalammar.github.io/illustrated-bert/.
Alammar, Jay. 2018b. “The Illustrated Gpt-2.” Blog Post. https://http://jalammar.github.io/illustrated-gpt2/.
Andreas, Jacob, and Dan Klein. 2014. “How Much Do Word Embeddings Encode About Syntax?” In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 822–27. Baltimore, Maryland: Association for Computational Linguistics. https://doi.org/10.3115/v1/P14-2133.
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. 2015. “Neural Machine Translation by Jointly Learning to Align and Translate.” In Proceeding of the 3rd International Conference on Learning Representations (ICLR’15).
Caruana, Rich. 1997. “Multitask Learning.” Machine Learning 28: 41–75. https://www.cs.utexas.edu/~kuipers/readings/Caruana-mlj-97.pdf.
Conneau, Alexis, German Kruszewski, Guillaume Lample, Loı̈c Barrault, and Marco Baroni. 2018. “What You Can Cram into a Single $&!#* Vector: Probing Sentence Embeddings for Linguistic Properties.” In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2126–36. Melbourne, Australia: Association for Computational Linguistics. https://doi.org/10.18653/v1/P18-1198.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–86. Minneapolis, Minnesota: Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1423.
Ettinger, Allyson. 2020. “What BERT Is Not: Lessons from a New Suite of Psycholinguistic Diagnostics for Language Models.” Transactions of the Association for Computational Linguistics 8: 34–48. https://doi.org/10.1162/tacl_a_00298.
Frankle, Jonathan, and Michael Carbin. 2018. “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks.” In Proceedings of the 8th International Conference on Learning Representations (Iclr’18).
Goodfellow, Ian, Yoshua Bengio, Aaron Courville, and Yoshua Bengio. 2016. Deep Learning. MIT Press Cambridge.
Hendrycks, Dan, and Kevin Gimpel. 2016. “Gaussian Error Linear Units (Gelus).” ArXiv Pre-Print 1606.08415. https://arxiv.org/abs/1606.08415.
Hewitt, John, and Percy Liang. 2019. “Designing and Interpreting Probes with Control Tasks.” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (Emnlp-Ijcnlp), 2733–43. Hong Kong, China: Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1275.
Hewitt, John, and Christopher D. Manning. 2019. “A Structural Probe for Finding Syntax in Word Representations.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4129–38. Minneapolis, Minnesota: Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1419.
Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. 2015. “Distilling the Knowledge in a Neural Network.” ArXiv Pre-Print 1503.02531. https://arxiv.org/abs/1503.02531.
Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. “Long Short-Term Memory.” Neural Computation 9 (8). MIT Press: 1735–80.
Howard, Jeremy, and Sebastian Ruder. 2018. “Universal Language Model Fine-Tuning for Text Classification.” In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 328–39. Melbourne, Australia: Association for Computational Linguistics. https://doi.org/10.18653/v1/P18-1031.
Jawahar, Ganesh, Benoit Sagot, and Djamé Seddah. 2019. “What Does BERT Learn About the Structure of Language?” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 3651–7. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/P19-1356.
Kriegeskorte, N., M. Mur, and P. Bandettini. 2008. “Representational Similarity Analysis – Connecting the Branches of Systems Neuroscience.” Frontiers in Systems Neuroscience 2. https://doi.org/10.3389/neuro.06.004.2008.
Kudo, Taku, and John Richardson. 2018. “SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing.” In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 66–71. Brussels, Belgium: Association for Computational Linguistics. https://doi.org/10.18653/v1/D18-2012.
Laakso, Aarre, and Garrison Cottrell. 2000. “Content and Cluster Analysis: Assessing Representational Similarity in Neural Systems.” Philosophical Psychology 13 (1). Taylor & Francis: 47–76.
Lan, Zhenzhong, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2020. “ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations.” In International Conference on Learning Representations. https://openreview.net/forum?id=H1eA7AEtvS.
Lin, Yongjie, Yi Chern Tan, and Robert Frank. 2019. “Open Sesame: Getting Inside BERT’s Linguistic Knowledge.” In Proceedings of the 2019 Acl Workshop Blackboxnlp: Analyzing and Interpreting Neural Networks for Nlp, 241–53. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/W19-4825.
Liu, Nelson F., Matt Gardner, Yonatan Belinkov, Matthew E. Peters, and Noah A. Smith. 2019. “Linguistic Knowledge and Transferability of Contextual Representations.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 1073–94. Minneapolis, Minnesota: Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1112.
Miaschi, Alessio, Dominique Brunato, Felice Dell’Orletta, and Giulia Venturi. 2020. “Linguistic Profiling of a Neural Language Model.” In Proceedings of the 28th Conference on Computational Linguistics (Coling). Online: Association for Computational Linguistics. https://arxiv.org/abs/2010.01869.
Miaschi, Alessio, and Felice Dell’Orletta. 2020. “Contextual and Non-Contextual Word Embeddings: An in-Depth Linguistic Investigation.” In Proceedings of the 5th Workshop on Representation Learning for Nlp, 110–19. Online: Association for Computational Linguistics. https://www.aclweb.org/anthology/2020.repl4nlp-1.15.
Mikolov, Tomas, Kai Chen, G. S. Corrado, and J. Dean. 2013. “Efficient Estimation of Word Representations in Vector Space.” CoRR abs/1301.3781.
Mikolov, Tomas, M. Karafiát, L. Burget, J. Cernocký, and S. Khudanpur. 2010. “Recurrent Neural Network Based Language Model.” In INTERSPEECH.
Morcos, Ari, Maithra Raghu, and Samy Bengio. 2018. “Insights on Representational Similarity in Neural Networks with Canonical Correlation.” In Advances in Neural Information Processing Systems 31, edited by S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, 5727–36. Curran Associates, Inc. http://papers.nips.cc/paper/7815-insights-on-representational-similarity-in-neural-networks-with-canonical-correlation.pdf.
Pascanu, R., Tomas Mikolov, and Yoshua Bengio. 2013. “On the Difficulty of Training Recurrent Neural Networks.” In Proceedings of the 30th International Conference on Machine Learning (Icml’13).
Pennington, Jeffrey, Richard Socher, and Christopher Manning. 2014. “GloVe: Global Vectors for Word Representation.” In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1532–43. Doha, Qatar: Association for Computational Linguistics. https://doi.org/10.3115/v1/D14-1162.
Peters, Matthew, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. “Deep Contextualized Word Representations.” In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 2227–37. New Orleans, Louisiana: Association for Computational Linguistics. https://doi.org/10.18653/v1/N18-1202.
Pimentel, Tiago, Josef Valvoda, Rowan Hall Maudslay, Ran Zmigrod, Adina Williams, and Ryan Cotterell. 2020. “Information-Theoretic Probing for Linguistic Structure.” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 4609–22. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.420.
Radford, A., Jeffrey Wu, R. Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. “Language Models Are Unsupervised Multitask Learners.” OpenAI Blog. OpenAI.
Raghu, Maithra, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. 2017. “SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability.” In Advances in Neural Information Processing Systems 30, edited by I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, 6076–85. Curran Associates, Inc. http://papers.nips.cc/paper/7188-svcca-singular-vector-canonical-correlation-analysis-for-deep-learning-dynamics-and-interpretability.pdf.
Rajpurkar, Pranav, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. “SQuAD: 100,000+ Questions for Machine Comprehension of Text.” In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 2383–92. Austin, Texas: Association for Computational Linguistics. https://doi.org/10.18653/v1/D16-1264.
Samek, W., Grégoire Montavon, A. Vedaldi, L. Hansen, and K. Müller. 2019. “Explainable Ai: Interpreting, Explaining and Visualizing Deep Learning.” Explainable AI: Interpreting, Explaining and Visualizing Deep Learning.
Saphra, Naomi, and Adam Lopez. 2019. “Understanding Learning Dynamics of Language Models with SVCCA.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 3257–67. Minneapolis, Minnesota: Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1329.
Sennrich, Rico, Barry Haddow, and Alexandra Birch. 2016. “Neural Machine Translation of Rare Words with Subword Units.” In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1715–25. Berlin, Germany: Association for Computational Linguistics. https://doi.org/10.18653/v1/P16-1162.
Shwartz-Ziv, Ravid, and Naftali Tishby. 2017. “Opening the Black Box of Deep Neural Networks via Information.” ArXiv Pre-Print 1703.00810. https://arxiv.org/abs/1703.00810.
Sussillo, David, Mark M Churchland, Matthew T Kaufman, and Krishna V Shenoy. 2015. “A Neural Network That Finds a Naturalistic Solution for the Production of Muscle Activity.” Nature Neuroscience 18 (7). Nature Publishing Group: 1025–33.
Tenney, Ian, Dipanjan Das, and Ellie Pavlick. 2019. “BERT Rediscovers the Classical NLP Pipeline.” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 4593–4601. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/P19-1452.
Thompson, Bruce. 1984. Canonical Correlation Analysis: Uses and Interpretation. 47. Sage.
Turian, Joseph, Lev-Arie Ratinov, and Yoshua Bengio. 2010. “Word Representations: A Simple and General Method for Semi-Supervised Learning.” In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, 384–94. Uppsala, Sweden: Association for Computational Linguistics. https://www.aclweb.org/anthology/P10-1040.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need.” In Advances in Neural Information Processing Systems 30, edited by I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, 5998–6008. Curran Associates, Inc. http://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf.
Voita, Elena, Rico Sennrich, and Ivan Titov. 2019. “The Bottom-up Evolution of Representations in the Transformer: A Study with Machine Translation and Language Modeling Objectives.” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (Emnlp-Ijcnlp), 4396–4406. Hong Kong, China: Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1448.
Wallace, Eric, Yizhong Wang, Sujian Li, Sameer Singh, and Matt Gardner. 2019. “Do NLP Models Know Numbers? Probing Numeracy in Embeddings.” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (Emnlp-Ijcnlp), 5307–15. Hong Kong, China: Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1534.
Wang, Alex, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding.” In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 353–55. Brussels, Belgium: Association for Computational Linguistics. https://doi.org/10.18653/v1/W18-5446.
Wu, Y., Mike Schuster, Z. Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, M. Krikun, et al. 2016. “Google’s Neural Machine Translation System: Bridging the Gap Between Human and Machine Translation.” ArXiv Pre-Print 1609.08144. https://arxiv.org/abs/1609.08144.
Zhang, Kelly, and Samuel Bowman. 2018. “Language Modeling Teaches You More Than Translation Does: Lessons Learned Through Auxiliary Syntactic Task Analysis.” In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 359–61. Brussels, Belgium: Association for Computational Linguistics. https://doi.org/10.18653/v1/W18-5448.
Refer to Chapter 6.3 of Eisenstein (2019) for additional details about recurrent language models.↩
Rogers, Kovaleva, and Rumshisky (2020) and Linzen and Baroni (2021) are surveys covering this topic.↩
See Belinkov and Glass (2019) survey and Belinkov, Gehrmann, and Pavlick (2020) tutorial.↩
This can be any layer; embeddings can be produced by different layers of the same model.↩
Different from the activation vector, i.e. all neurons’ activations for a single input \((z^l_1(x_1),\dots,z^l_n(x_1))\)↩