Are Character-level Translations Worth the Wait? Comparing ByT5 and mT5 for Machine Translation
Abstract
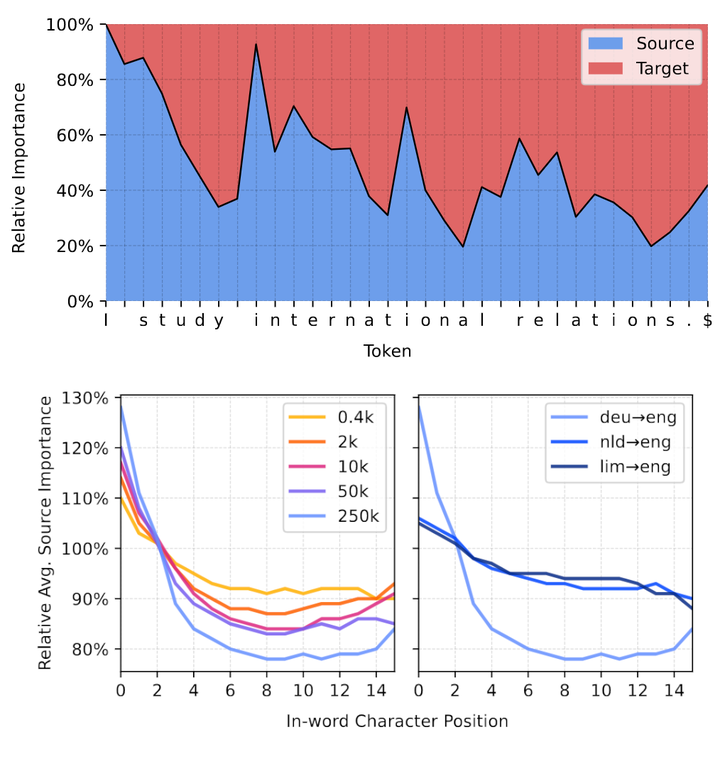
Pretrained character-level and byte-level language models have been shown to be competitive with popular subword models across a range of Natural Language Processing tasks. However, there has been little research on their effectiveness for neural machine translation (NMT), particularly within the popular pretrain-then-finetune paradigm. This work performs an extensive comparison across multiple languages and experimental conditions of character- and subword-level pretrained models (ByT5 and mT5, respectively) on NMT. We show the effectiveness of character-level modeling in translation, particularly in cases where fine-tuning data is limited. In our analysis, we show how character models’ gains in translation quality are reflected in better translations of orthographically similar words and rare words. While evaluating the importance of source texts in driving model predictions, we highlight word-level patterns within ByT5, suggesting an ability to modulate word-level and character-level information during generation. We conclude by assessing the efficiency tradeoff of byte models, suggesting their usage in non-time-critical scenarios to boost translation quality.